

Non-monotonic Logic
The term "non-monotonic logic" covers a family of formal frameworks devised to capture and represent defeasible inference, i.e., that kind of inference of everyday life in which reasoners draw conclusions tentatively, reserving the right to retract them in the light of further information. Such inferences are called "non-monotonic" because the set of conclusions warranted on the basis of a given knowledge base does not increase (in fact, it can shrink) with the size of the knowledge base itself. This is in contrast to classical (first-order) logic, whose inferences, being deductively valid, can never be "undone" by new information.
- Abstract consequence relations
- Skeptical or credulous?
- Non-monotonic formalisms
- Conclusion
- Bibliography
- Other Internet Resources
- Related Entries
Abstract Consequence relations
Classical first-order logic (henceforth: FOL) is monotonic: if a sentence φ can be inferred in FOL from a set Γ of premises, then it can also be inferred from any set Δ of premises containing Γ as a subset. In other words, FOL provides a relation ⊨ of consequence between sets of premises and single sentences with the property that if Γ ⊨ φ and Γ ⊆ Δ then Δ ⊨ φ. This follows immediately from the nature of the relation ⊨, for Γ ⊨ φ holds precisely when φ is true on every interpretation on which all sentences in Γ are true (see the entry on classical logic for details on the relation ⊨).
From an abstract point of view, we can consider the formal
properties of a consequence relation. Let
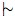 be any relation between sets of premises and
single sentences. It is natural to consider the following properties,
all of which are satisfied by the consequence relation
⊨
of FOL:
be any relation between sets of premises and
single sentences. It is natural to consider the following properties,
all of which are satisfied by the consequence relation
⊨
of FOL:
- Supraclassicality: if Γ
⊨
φ then Γ
φ.
- Reflexivity: if φ ∈ Γ then
Γ
φ;
- Cut: If Γ
φ and Γ, φ
ψ then Γ
ψ;
- Monotony: If Γ
φ and Γ ⊆ Δ then Δ
φ.
Supraclassicality just requires that
be an extension of
⊨,
i.e., that if φ follows from Γ in FOL,
then it must also follow according to
.
(The relation
⊨
is trivially supraclassical).
The most straightforward of the remaining conditions is reflexivity: we certainly would like all sentences in Γ to be inferable from Γ. This translates to the requirement that if φ belongs to the set Γ, then φ is a consequence of Γ. Reflexivity is a rather minimal requirement on a relation of logical consequence: It is hard to imagine in what sense a relation that fails to satisfy reflexivity, can still be considered considered a consequence relation.
Cut, a form of transitivity, is another crucial feature of consequence relations. Cut is a conservativity principle: if φ is a consequence of Γ, then ψ is a consequence of Γ together with φ only if it is already a consequence of Γ alone. In other words, by adjoining to Γ something which is already a consequence of Γ does not lead to any increase in inferential power.
Cut is best regarded as a condition on the "length" of a proof (where "length" is to be understood in some intuitive sense related to the complexity of the argument supporting a given conclusion). When viewed in these terms, Cut amounts to the requirement that the length of the proof does not affect the degree to which the assumptions support the conclusion. Where φ is already a consequence of Γ, if ψ can be inferred from Γ together with φ, then ψ can also be obtained via a longer "proof" that proceeds indirectly by first inferring φ.
In many forms of probabilistic reasoning the degree to which the premises support the conclusion is inversely correlated to the length of the proof. For this reason, many forms of probabilistic reasoning fail to satisfy Cut. To see this, we adapt a well-known counter-example: let Ax abbreviate "x is a Pennsylvania Dutch", Bx abbreviate "x is a native speaker of German", and Cx abbreviate "x was born in Germany". Further, let Γ comprise the statements "Most As are Bs," "Most Bs are Cs," and Ax. Then Γ supports Bx, and Γ together with Bx supports Cx, but Γ by itself does not support Cx. (Here statements of the form "Most As are Bs" are interpreted probabilistically, as saying that the conditional probability of B given A is, say, greater that 50%.) To the extent that Cut is a necessary feature of a well-behaved consequence relation, examples of inductive reasoning such as the one just given cast some doubt on the possibility of coming up with a well-behaved relation of probabilistic consequence.
For our purposes, Monotony is the central property. Monotony states that if φ is a consequence of Γ then it is also a consequence of any set containing Γ (as a subset). The import of monotony is that one cannot pre-empt conclusions by adding new premises. However, there are many inferences typical of everyday (as opposed to mathematical or formal) reasoning, that do not satisfy monotony. These are cases in which we reach our conclusions defeasibly (i.e., tentatively), reserving the right to retract them in the light of further information. Perhaps the clearest examples are derived from legal reasoning, in which defeasible assumptions abound. In the judicial system, the principle of presumption of innocence leads us to infer (defeasibly) from the fact that x is to stand trial, the conclusion that x is innocent; but clearly the conclusion can be retracted in the light of further information.
Other examples are driven by typicality considerations. If being a B is a typical trait of A's, then from the fact that x is an A we infer the conclusion that x is a B. But the conclusion is defeasible, in that B-ness is not a necessary trait of A's, but only (perhaps) of 90% of them. For example, mammals, by and large, don't fly, so that lack of flight can be considered a typical trait of mammals. Thus, when supplied with information that x is a mammal, we naturally infer that x does not fly. But this conclusion is defeasible, and can be undermined by the acquisition of new information, for example by the information that x is a bat. This inferential process can be further iterated. We can learn, for instance, that x is a baby bat, that does not know how to fly yet.
Defeasible reasoning, not unlike FOL, can follow complex patterns. However, such patterns are beyond reach for FOL, which is, by its very nature, monotonic. The challenge then is to provide for defeasible reasoning what FOL provides for formal or mathematical reasoning, i.e., an account that is both materially adequate and formally precise.
The conclusion of the preceding discussion is that monotony has to
be abandoned, if we want to give a formal account of these patterns of
defeasible reasoning. Then the question naturally arises of what formal
properties of the consequence relation are to replace monotony. Two
such properties, given below, have been considered in the literature,
where
is an arbitrary
consequence relation:
- Cautious Monotony: If Γ
φ and Γ
ψ, then Γ, φ
ψ.
- Rational Monotony: If it's not the case
that
Γ¬ φ, and moreover
Γ
ψ,
then Γ,
φ
ψ.
Both Cautious Monotony and the stronger principle of Rational Monotony are special cases of Monotony, and are therefore not in the foreground as long as we restrict ourselves to the classical consequence relation ⊨ of FOL.
Although superficially similar, these principles are in reality quite different. Cautious Monotony is the converse of Cut: it states that adding a consequence φ back into the premise-set Γ does not lead to any decrease in inferential power. Cautious Monotony tells us that inference is a cumulative enterprise: we can keep drawing consequences that can in turn be used as additional premises, without affecting the set of conclusions. Together with Cut, Cautious Monotony says that if φ is a consequence of Γ then for any proposition ψ, ψ is a consequence of Γ if and only if it is a consequence of Γ together with φ. It has been often pointed out, most notably by Gabbay (1985), that Reflexivity, Cut and Cautious Monotony are critical properties for any well-behaved non-monotonic consequence relation.
The status of Rational Monotony is much more problematic. As we
observed, Rational Monotony can be regarded as a strengthening of
Cautious Monotony, and like the latter it is a special case of
Monotony. However, there are reasons to think that Rational Monotony
might not be a correct feature of a non-monotonic consequence relation.
A counter-example due to Robert Stalnaker (see
Stalnaker (1994))
involves three composers: Verdi,
Bizet, and Satie. Suppose that we initially accept (correctly but
defeasibly) that Verdi is Italian, while Bizet and Satie are French. We
assume that these defeasible conclusions are built into whatever
inferential mechanism implements the non-monotonic relation
.
Suppose now that we are told by a reliable (but not infallible!) source of information that that Verdi and Bizet are compatriots. This leads us no longer to endorse the proposition that Verdi is Italian (because he could be French), and that Bizet is French (because he could be Italian); but we would still draw the defeasible consequence that Satie is French, since nothing that we have learned conflicts with it. By letting I(v), F(b), and F(s) represent our initial beliefs about the composers' nationalities, and C(v,b) represent the proposition that Verdi and Bizet are compatriots, the situation could be represented as follows:
C(v,b)
Now consider the proposition C(v,s) that Verdi and Satie are compatriots. Before learning that C(v,b) we would be inclined to reject the proposition C(v,s) because we endorse and I(v) and F(s), but after learning that Verdi and Bizet are compatriots, we can no longer endorse I(v), and therefore no longer reject C(v,s). Then the following fails:
C(v,b)
However, if we added C(v,s) to our stock of beliefs, we would lose the inference to F(s): in the context of C(v,b), the proposition C(v,s) is equivalent to the statement that all three composers have the same nationality. This leads us to suspend our assent to the proposition F(s). In other words, and contrary to Rational Monotony, the following also fails:
C(v,b), C(v,s)
The previous discussion gives a rather clear picture of the desirable features of a non-monotonic consequence relation. Such a relation should satisfy Supraclassicality, Reflexivity, Cut, and Cautious Monotony.
Skeptical or credulous?
A separate issue from the formal properties of a non-monotonic consequence relation, although one that is strictly intertwined with it, is the issue of how conflicts between potential defeasible conclusions are to be handled.
There are two different kinds of conflicts that can arise within a given non-monotonic framework: (i) conflicts between defeasible conclusions and "hard facts," some of which possibly newly learned; and (ii) conflicts between one potential defeasible conclusion and another (many formalisms, for instance, provide some form of defeasible inference rules, and such rules might have conflicting conclusions). When a conflict (of either kind) arises, steps have to be taken to preserve or restore consistency.
All non-monotonic logics handle conflicts of the first kind in the same way: indeed, it is the very essence of defeasible reasoning that conclusions can be retracted when new facts are learned. But conflicts of the second kind can be handled in two different ways: one can draw inferences either in a "cautious" or "bold" fashion (also known as "skeptical" or, respectively, "credulous"). These two options correspond to significantly different ways to construe a given body of defeasible knowledge, and yield different results as to what defeasible conclusions are warranted on the basis of such a knowledge base.
The difference between these basic attitudes comes to this. In the presence of potentially conflicting defeasible inferences (and in the absence of further considerations such as specificity -- see below), the credulous reasoner always commits to as many defeasible conclusions as possible, subject to a consistency requirement, whereas the skeptical reasoner withholds assent from potentially conflicted defeasible conclusions.
A famous example from the literature, the so-called "Nixon diamond," will help make the distinction clear. Suppose our knowledge base contains (defeasible) information to the effect that a given individual, Nixon, is both a Quaker and a Republican. Quakers, by and large, are pacifists, whereas Republicans, by and large are not. The question is what defeasible conclusions are warranted on the basis of this body of knowledge, and in particular whether we should infer that Nixon is a pacifist or that he is not pacifist. The following figure provides a schematic representation of this state of affairs in the form a (defeasible) network:
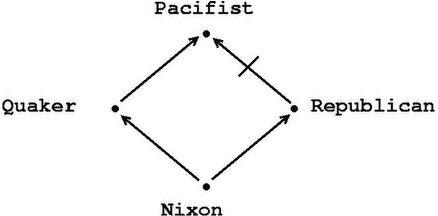
The credulous reasoner has no reason to prefer either conclusion ("Nixon is a pacifist;" "Nixon is not a pacifist") to the other one, but will definitely commit to one or the other. The skeptical reasoner recognizes that this is a conflict not between hard facts and defeasible inferences, but between two different defeasible inferences. Since the two possible inferences in some sense "cancel out," the skeptical reasoner will refrain from drawing either one.
Defeasible inheritance networks can also be interpreted as providing a representation of that particular kind of inference referred to as "stereotypical." Stereotypes are just generalizations concerning particular populations; while they might be sometimes useful as such, their applicability to individual cases is problematic. In fact, the particular point of view according to which stereotypes apply to groups but not to individuals meshes particularly well with the skeptical approach to defeasible inheritance.
Consider again the Nixon Diamond above. Part of what it says is that there are stereotypes to the effect that Quakers are Pacifists and Republicans are not. But of course the whole point of the skeptical interpretation of the diagram is that one cannot reliably use such information to reach conclusions about a particular individual.
The point can be presented quantitatively as well. Consider the following Venn diagram, where the numbers represent the population inhabiting a particular region:
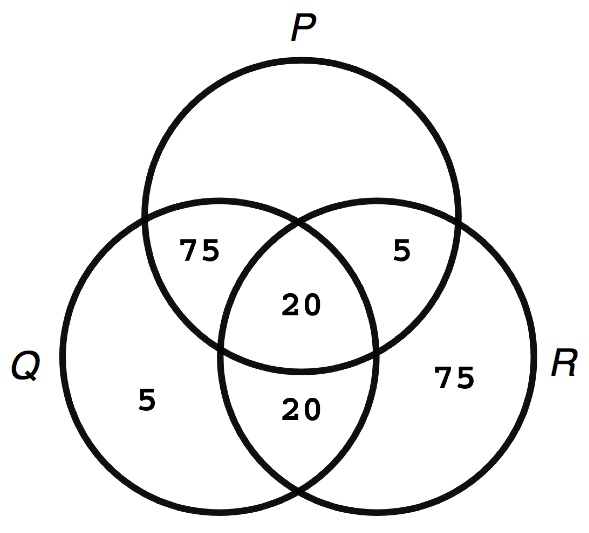
The stereotypes are supported, from a probabilistic point of view. In fact, the probability of P given Q is 96/120, or about 79%. Similarly, the probability of not-P given R is about 79%. But of course the probability of P given Q and R is only 50%. It seems like no particular conclusions can be drawn from the fact that a particular individual is both a Quaker and a Republican. (Thanks to Julia Hairston for a useful discussion of stereotypes).
Indeed, whereas many of the early formulations of defeasible reasoning have been credulous, skepticism has gradually emerged as a viable alternative, which can, at times, be better behaved. Arguments have been given in favor of both skeptical and credulous inference. Some have argued that credulity seems better to capture a certain class of intuitions, while others have objected that although a certain degree of "jumping to conclusion" is by definition built into any non-monotonic formalism, such jumping to conclusions needs to be regimented, and that skepticism provides precisely the required regimentation. (A further issue in the skeptical/credulous debate is the question of whether so-called "floating conclusions" should be allowed; see Horty (2002) for a review of the literature and a substantial argument that they should not.)
Non-monotonic formalisms
One of the most significant developments both in logic and artificial intelligence is the emergence of a number of non-monotonic formalisms, which were devised expressly for the purpose of capturing defeasible reasoning in a mathematically precise manner. The fact that patterns of defeasible reasoning have been accounted for in such a rigorous fashion has wide-ranging consequences for our conceptual understanding of argumentation and inference.
Pioneering work in the field of non-monotonic logics began with the realization that ordinary first-order logic is inadequate for the representation of defeasible reasoning accompanied by the effort to reproduce the success of FOL in the representation of mathematical, or formal, reasoning. Among the pioneers of the field in the late 1970's were (among others) J. McCarthy, D. McDermott & J. Doyle, and R. Reiter (see Ginsberg (1987) for a collection of early papers in the field and Gabbay et al (1994) for a more recent collection of excellent survey papers). In 1980, the Artificial Intelligence Journal published an issue (vol. 13, 1980) dedicated to these new formalisms, an event that has come to be regarded as the "coming of age" of non-monotonic logic.
If one of the goals of non-monotonic logic is to provide a materially adequate account of defeasible reasoning, it is important to rely on a rich supply of examples to guide and hone intuitions. Database theory was one of the earliest sources of such examples, especially as regards the closed world assumption. Suppose a travel agent has access to a flight database, and needs to answer a client's query about the best way to get from Oshkosh to Minsk. The agents queries the database and, not surprisingly, responds that there are no direct flights. How does the travel agent know?
It is quite clear that, in a strong sense of "know", the travel agent does not know that there are no such flights. What is at work here is a tacit assumption that the database is complete, and that since the database does not list any direct flights between the two cities, then there are none. A useful way to look at this process is as a kind of minimization, i.e., an attempt to minimize the extension of a given predicate ("flight-between," in this case). Moreover, on pain of inconsistencies, such a minimization needs to take place not with respect to what the database explicitly contains but with respect to what it implies.
The idea of minimization is at the basis of one of the earliest non-monotonic formalisms, McCarthy's circumscription. Circumscription makes explicit the intuition that, all other things being equal, extensions of certain predicates should be minimal. Again, consider principles such as "all normal birds fly". Implicit in this principle is the idea that the extension of the abnormality predicate should be minimal, and that specimens should not be considered to be abnormal unless there is positive information to that effect. McCarthy's idea was to represent this formally, using second-order logic (SOL). In SOL, in contrast to FOL, one is allowed to explicitly quantify over predicates, forming sentences such as ∃P∀xPx ("there is a universal predicate") or ∀P(Pa ↔Pb) ("a and b are indiscernible").
In circumscription, given predicates P and Q, we abbreviate ∀x(Px → Qx) as P≤Q; similarly, we abbreviate P≤Q & ¬ Q≤P as P<Q. If A(P) is a formula containing occurrences of a predicate P, then the circumscription of P in A is the second-order sentence A*(P):
A(P) & ¬∃Q[A(Q) & Q<P]A*(P) says that P satisfies A, and that no smaller predicate does. Let Px be the predicate "x is abnormal," and let A(P) be the sentence "All normal birds fly." Then the sentence "Tweety is a bird," together with A*(P) implies "Tweety flies," for the circumscription axiom forces the extension of P to be empty, so that "Tweety is normal" is automatically true.
In terms of consequence relations, circumscription allows us to
define, for each predicate P, a non-monotonic relation
A(P) φ
that holds precisely when A*(P)
⊨ φ.
(This basic form of circumscription has been
generalized, for in practice, one needs to minimize the extension of a
predicate, while allowing the extension of certain other predicates to
vary.) From the point of view of applications, however, circumscription
has a major computational shortcoming, which is due to the nature of
second-order language in which circumscription is formulated. The
problem is that SOL, contrary to FOL, lacks a complete inference
procedure: the price one pays for the greater expressive power of
second-order logic is that there are no complete axiomatizations, as we
have for FOL. It follows that there is no way to list, in an effective
manner, all SOL validities, and hence to determine whether
A(P)
φ.
Another non-monotonic formalism inspired by the intuition of minimization of abnormalities is non-monotonic inheritance. Whenever we have a taxonomically organized body of knowledge, we presuppose that subclasses inherit properties from their superclasses: dogs have lungs because they are mammals, and mammals have lungs. However, there can be exceptions, which can interact in complex ways. To use an example already introduced, mammals, by and large, don't fly; since bats are mammals, in the absence of any information to the contrary, we are justified in inferring that bats do not fly. But then we learn that bats are exceptional mammals, in that they do fly: the conclusion that they don't fly is retracted, and the conclusion that they fly is drawn instead. Things can be more complicated still, for in turn, as we have seen, baby bats are exceptional bats, in that they do not fly (does that make them unexceptional mammals?). Here we have potentially conflicting inferences. When we infer that Stellaluna, being a baby bat, does not fly, we are resolving all these potential conflicts based on a specificity principle: more specific information overrides more generic information.
Non-monotonic inheritance networks were developed for the purpose of capturing taxonomic examples such as the above. Such networks are collections of nodes and directed ("IS-A") links representing taxonomic information. When exceptions are allowed, the network is interpreted defeasibly. The following figure gives a network representing this state of affair:
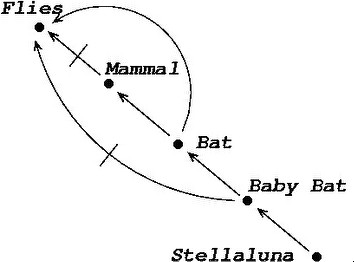
In such a network, links of the form A → B, represent the fact that, typically and for the most part, A's are B's, and that therefore information about A's is more specific than information about B's. More specific information overrides more generic information. Research on non-monotonic inheritance focuses on the different ways in which one can make this idea precise.
The main issue in defeasible inheritance is to characterize the set of assertions that are supported by a given network. It is of course not enough to devise a representational formalism, one also needs to specify how the formalism is to be interpreted. Such a characterization is accomplished through the notion of extension of a given network. There are two competing characterizations of extension for this kind of networks, one that follows the credulous strategy and one that follows the skeptical one. Both proceed by first defining the degree of path through the network as the length of the longest sequence of links connecting its endpoints; extensions are then constructed by considering paths in ascending order of their degrees. We are not going to review the details, since many of the same issues arise in connection with default logic (which is treated to greater length below), but Horty (1994) provides an extensive survey. It is worth mentioning that since the notion of degree makes sense only in the case of acyclic networks, special issues arise when networks contain cycles (see Antonelli (1997), (2005) for a treatment of inheritance on cyclic networks).
Although the language of non-monotonic networks is expressively limited by design (in that only links of the form "IS-A" can be represented in a natural fashion), such networks provide an extremely useful setting in which to test and hone one's intuitions and methods for handling defeasible information. Such intuitions and methods are then applied to more expressive formalisms. Among the latter is Reiter's Default Logic, perhaps the most flexible among non-monotonic frameworks.
In Default Logic, the main representational tool is that of a default rule, or simply a default. A default is a defeasible inference rule of the form
γ : θ
τ
(where γ, θ, τ are sentences in a given language, respectively called the pre-requisite, the justification and the conclusion of the default). The interpretation of the default is that if γ is known, and there is no evidence that θ might be false, then τ can be inferred.
As is clear, application of the rule requires that a consistency condition be satisfied. What makes meeting the condition complicated is the fact that rules can interact in complex ways. In particular, it is possible that application of some rule might cause the consistency condition to fail for some, not necessarily distinct, rule. For instance, if θ is ¬τ then application of the rule is in a sense self-defeating, in that application of the rule itself causes the consistency condition to fail.
Reiter's default logic uses its own notion of an extension to make precise the idea that the consistency condition has to be met both before and after the rule is applied. Given a set Γ of defaults, an extension for Γ represents a set of inferences that can be reasonably and consistently drawn using defaults from Γ. Such inferences are those that are warranted on the basis of a maximal set of defaults whose consistency condition is met both before and after their being triggered.
More in particular (and in typical circular fashion), an extension for Γ is a maximal subset Δ of Γ the conclusions of whose defaults both imply all the pre-requisites of defaults in Γ and are consistent with all the justifications of defaults in Γ. This definition can be made both less mysterious and more precise as follows. By a default theory we mean a pair (W,Δ), where Δ is a (finite) set of defaults, and W is a set of sentences (a world description). The idea is that W represents the strict or background information, whereas Δ specifies the defeasible information. Given a pair (T1,T2) of sets of sentences, a default such as the above is triggered by (T1,T2) if and only if T1 ⊨ γ and it's not the case that T2⊨ ¬θ (i.e., θ is consistent with T2). (Notice how this definition is built "on top" of ⊨: we could, conceivably, employ a different relation here.)
Finally we say that a set of sentences E is an extension for a default theory (W,Δ) if and only if
E = E0∪E1∪ ... ∪ En∪... ,
where: E0 = W, and
En+1 = En ∪{τ : (γ : θ) / τ ∈Δ is triggered by (En, E) }.
It is important to notice the occurrence of the limit E in the definition of En+1: the condition above is not a garden-variety recursive defintion, but a truly circular characterization of extensions.
This circularity can be made explicit by giving an equivalent definition of extension as solution of fixpoint equations. Given a default theory, let S be an operator defined on set of sentences such that for any set S of sentences, S(S) is the smallest set containing W, deductively closed (i.e., such that if S(S) ⊨ φ then φ ∈S(S)), and such that if a default with consequent τ is triggered by (S,S) then τ∈S(S). Then one can show that E is an extension for (W,Δ) if and only if E is a fixed point of S, i.e., if S(E) = E.
For any given default theory, extensions need not exist, and even when they exist, they need not be unique. Let us consider a couple of examples. Our first example is a default theory that has no extension: let W contain the sentence γ let Δ comprise the single default
γ : θ
¬θ
If E were an extension, then the default above would have to be either triggered or not triggered by it, and either case is impossible. For if the default were triggered, then the consistency condition would fail, and if if were not triggered then the consistency condition would hold, and hence the default would have to be triggered by maximality of extensions.
Let us now consider an example of a default theory with multiple extensions. As before, let W contain the sentence γ, and suppose Δ comprises the following two defaults
γ : θ
¬τ
and
γ : τ
¬θ
This theory has exactly two extensions, one in which the first default is triggered and one in which the second one is. It is easy to see that at least a default has to be triggered in any extension, and that both defaults cannot be triggered by the same extension.
These examples are enough to bring out a number of features. First, it should be noted that neither one of the two characterizations of extension for default logic (i.e., the fixpoint definition and the pseudo-iterative one) given above gives us a way to "construct" extension by means of anything resembling an iterative process. Essentially, one has to "guess" a set of sentences E, and then verify that it satisfies the definition of an extension.
Further, the fact that default theories can have zero, one, or more extensions raises the issues of what inferences one is warranted in drawing from a given default theory. The problem can be presented as follows: given a default theory (W,Δ), what sentences can be regarded as defeasible consequences of the theory? At first sight, there are several options available.
One option is to take the union of the extensions of the theory, and consider a sentence φ a consequence of a given default theory if and only if φ belongs to any extension of the theory. But this option is immediately ruled out, in that it leads to endorsing contradictory conclusion, as in the second example above. It is widely believed that any viable notion of defeasible consequence for default logic must have the property that the set
{φ : (W,Δ)
must be consistent whenever W is. Once this option is ruled out, only two alternatives are left:
The first alternative, known as the "credulous" or "bold" strategy, is to pick an extension E for the theory, and say that φ is a defeasible consequence if and only if φ∈ E. The second alternative, known as the "skeptical" or "cautious" strategy, is to endorse a conclusion φ if and only if φ is contained in every extension of the theory.
Both the credulous and the skeptical strategy have problems. The problem with the credulous strategy is that the choice of E is arbitrary: with the notion of extension introduced by Reiter, extensions are orthogonal: of any two distinct extensions, neither one contains the other. Hence, there seems to be no principled way to pick an extension over any other one. This has led a number of researcher to endorse the skeptical strategy as a viable approach to the problem of defeasible consequence. But as showed by Makinson, skeptical consequence, as based on Reiter's notion of extension, fails to be cautiously monotonic. To see this, consider the default theory (WΔ), where W is empty, and Δ comprises the following two defaults:
: θ
θ
and
θ∨γ : ¬θ
¬θ
This theory has only one extension, coinciding with the deductive
closure of {θ}. Hence, if we define defeasible consequence by
putting (W,Δ)
φ
if and only if φ belongs to every
extension of (W,Δ), we have (W,Δ)
θ, as well as
(W,Δ)
θ∨γ (by the deductive closure of
extensions).
Now consider the theory with Δ as before, but with W
containing the sentence
θ∨γ.
This theory has two extensions: one the same as before, but also
another one coinciding with the deductive closure of {¬θ},
and hence not containing θ. It follows that the intersection of
the extensions no longer contains θ, so that ({
θ∨γ} Δ)
θ now fails, against cautious
monotony. (Notice that the same example establishes a counter-example
for Cut for the credulous strategy, when we pick the extension
of
({θ∨ γ},Δ) that
contains ¬θ.)
(The skeptical approach is also, conceivably, subject to consideration related to floating conclusions, as we already mentioned. But missing these conclusion might indeed be a desirable feature, as argued by Horty (2002)).
It is clear that the issue of how to define a non-monotonic consequence relation for default logic is intertwined with the way that conflicts are handled. The problem of course is that in this case neither the skeptical nor the credulous strategy yield an adequate relation of defeasible consequence. In Antonelli (1999) a notion of general extension for default logic is introduced, showing that this notion yields a well-behaved relation of defeasible consequence that satisfies all four requirements of Supraclassicality, Reflexivity, Cut, and Cautious Monotony. (The same treatment can be found in Antonelli (2005)).
A different set of issues arises in connection with the behavior of
default logic from the point of view of computation. For a given
semi-decidable set Γ of sentences, the set of all φ that are
a consequence of Γ in FOL is itself semi-decidable (see the entry
on
computability and complexity).
In
the case of default logic, to formulate the corresponding problem one
extends (in the obvious way) the notion of (semi-)decidability to sets
of defaults. The problem, then, is to decide, given a default theory
(W,Δ) and a sentence φ whether
(W,Δ) φ,
where
is
defined, say,
skeptically. Such a problem is not even semi-decidable, the essential
reason being that in general, in order to determine whether a default
is triggered by a pair of sets of sentences, one has to perform a
consistency check, and such checks are not computable.
But the consistency checks are not the only source of complexity in default logic. For instance, we could restrict our language to conjunctions of atomic sentences and their negations (making consistency checks feasible). Even so, the problem of determining whether a given default theory has an extension would still be highly intractable (NP-complete, to be precise, as shown by Kautz & Selman (1991)), seemingly because the problem requires checking all possible sequences of firings of defaults
Default logic is intimately connected with certain modal approaches to non-monotonic reasoning, which belong to the family of autoepistemic logics. Modal logics in general have proved to be one of the most flexible tools for modelling all sorts of dynamic processes and their complex interactions (see the entry "modal logic", this Encyclopedia). Beside the applications in knowledge representation, which we are going to treat below, there are modal frameworks, known as dynamic logics, that play a crucial role, for instance, in the modelling of serial or parallel computation. The basic idea of modal logic is that the language is interpreted with respect to a given set of states, and that sentences are evaluated relative to one of these states. What these states are taken to represent depends on the particular application under consideration (they could be epistemic states, or states in the evolution of a dynamical system, etc.), but the important thing is that there are transitions (of one or more different kinds) between states.
In the case of one transition that is both transitive (i.e., such that if a→b and b→c then a→ c) and euclidean (if a → b and a → c then b → c), the resulting modal system is referred to as K45. Associated with each kind of state transition there is a corresponding modality in the language, usually represented as a box □. A sentence of the form □A is true at a state s if and only if A is true at every state s′ reachable from s by the kind of transition associated with □ (see Chellas (1980) or Hughes and Cresswell (1996) for comprehensive introductions to modal logic).
In autoepistemic logic, the states involved are epistemic states of the agent (or agents). The intuition underlying autoepistemic logic is that we can sometimes draw inferences concerning the state of the world using information concerning our own knowledge or ignorance. For instance, I can conclude that I do not have a sister given that if I did I would probably know about it, and nothing to that effect is present in my "knowledge base". But such a conclusion is defeasible, since there is always the possibility of learning new facts. In order to make these intuitions precise, consider a modal language in which the necessity operator □ is interpreted as "it is known that". As in default logic or defeasible inheritance, the central notion in autoepistemic logic is that of an extension of a theory S, i.e., a consistent and self-supporting sets of beliefs that can reasonably be entertained on the basis of S. Given a set S of sentences, let S0 be the subset of S composed of those sentences containing no occurrences of □; further, let the positive introspective closure PIC(S0) of S0 be the set
{□φ : φ ∈S0 },
and the negative introspective closure NIC(S0) of S0 the set
{¬□φ : φ ∉ S0 }.
The set PIC(S0) is called the introspective closure because it explicitly contains positive information about the agent's epistemic status: PIC(S0) expresses what is known (similarly, NIC(S0) contains negative information about the agent's epistemic status, stating explicitly what is not known).
With these notions in place, we define an extension for S to be a set T of sentences such that:
T = { φ : φ follows (in K45) from S ∪ PIC(T0) ∪ NIC(T0) }
Autoepistemic logic provides a rich language, with interesting mathematical properties and connections to other non-monotonic formalisms. It is faithfully intertranslatable with Reiter's version of default logic, and provides a defeasible framework with well-understood modal properties.
Conclusion
There are three major issues connected with the development of logical frameworks that can adequately represent defeasible reasoning: (i) material adequacy; (ii) formal properties; and (iii) complexity. Material adequacy concerns the question of how broad a range of examples is captured by the framework, and the extent to which the framework can do justice to our intutions on the subject (at least the most entrenched ones). The question of formal properties has to do with the degree to which the framework allows for a relation of logical consequence that satisfies the above mentioned conditions of Supraclassicality, Reflexivity, Cut, and Cautious Monotony. The third set of issues has to do with computational complexity of the most basic questions concerning the framework.
There is a potential tension between (i) and (ii): the desire to capture a broad range of intuitions can lead to ad hoc solutions that can sometimes undermine the desirable formal properties of the framework. In general, the development of non-monotonic logics and related formalisms has been driven, since its inception, by consideration (i) and has relied on a rich and well-chosen array of examples. Of course, there is some question as to whether any single framework can aspire to be universal in this respect.
More recently, researchers have started paying attention to consideration (ii), looking at the extent to which non-monotonic logics have generated well-behaved relations of logical consequence. As Makinson (1994) points out, practitioners of the field have encountered mixed success. In particular, one abstract property, Cautious Monotony, appears at the same time to be crucial and elusive for many of the frameworks to be found in the literature. This is a fact that is perhaps to be traced back, at least in part, to the above-mentioned tension between the requirement of material adequacy and the need to generate a well-behaved consequence relation.
The complexity issue appears to be the most difficult among the ones that have been singled out. Non-monotonic logics appear to be stubbornly intractable with respect to the corresponding problem for classical logic. This is clear in the case of default logic, given the ubiquitous consistency checks. But beside consistency checks, there are other, often overlooked, sources of complexity that are purely combinatorial. Other forms of nonmonotonic reasoning, beside default logic, are far from immune from these combinatorial roots of intractability. Although some important work has been done trying to make various non-monotonic formalism more tractable, this is perhaps the problem on which progress has been slowest in coming.
Bibliography
The following list of references is of course far from exhaustive, but it is only meant to provide entry points to the literature.
- Antonelli, G.A., 1997, "Defeasible inheritance over cyclic networks", Artificial Intelligence, vol. 92 (1), pp. 1-23.
- –––, 1999, "A directly cautious theory of defeasible consequence for default logic via the notion of general extension", Artificial Intelligence, vol. 109 (1-2), pp. 71-109.
- –––, 2005, Grounded Consequence for Defeasible Logic, Cambridge: Cambridge University Press, 2005.
- Chellas, B., 1980, Modal Logic: an introduction, Cambridge: Cambridge University Press, 1980.
- Gabbay, D. M., 1985, "Theoretical foundations for nonmonotonic reasoning in expert systems", in K. Apt, ed., Logics and Models of Concurrent Systems, Berlin and New York: Springer Verlag, pp. 439-459.
- Gabbay, D., Hogger, C., and Robinson, J., (eds.), 1994, Handbook of Logic in Artificial Intelligence and Logic Programming, volume 3, Oxford and New York: Oxford University Press.
- Ginsberg, M., (ed.), 1987, Readings in Nonmonotonic Reasoning, , Los Altos, CA: Morgan Kauffman.
- Hughes, G. and Cresswell, M., 1996, A New Introduction to Modal Logic, London: Routledge.
- Horty, J.F., 1994, "Some direct theories of nonmonotonic inheritance", in Gabbay et al. (1994), pp. 111-187.
- –––, 2002, "Skepticism and floating conclusions", Artificial Intelligence Journal 135, pp. 55-72.
- Kautz, H., and Selman, B., 1991, "Hard problems for simple default logic", Artificial Intelligence Journal, vol. 49, pp. 243-279
- Lifschitz, V., 1993, "Circumscription", in Gabbay, Hogger, and Robinson (eds) 1994.
- Makinson, D., 1994, "General patterns in nonmonotonic reasoning", in Gabbay et al. (1994), pp. 35-110.
- McCarthy, J., 1980, "Circumscription — A Form of Non-Monotonic Reasoning", Artificial Inteligence, 13 (1980) pp. 27-39.
- –––, 1986, "Applications of Circumscription to Formalizing Common Sense Knowledge", Artificial Inteligence, 28 (1986), pp. 89-116.
- –––, 1990, Formalization of common sense. Papers by John McCarthy edited by V. Lifschitz", Ablex, 1990.
- Stalnaker, R., 1994, "Nonmonotonic consequence relations", Fundamenta Informaticae, vol. 21, pp. 7-21.
Other Internet Resources
[Please contact the author with suggestions.]
Related Entries
artificial intelligence | artificial intelligence: logic and | computability and complexity | logic: classical | logic: modal | model theory: first-order