

Simpson's Paradox
An association between a pair of variables can consistently be inverted in each subpopulation of a population when the population is partitioned. For example, a medical treatment can be associated with a higher recovery rate for treated patients compared with the recovery rate for untreated patients; yet, treated male patients and treated female patients can each have lower recovery rates when compared with untreated male patients and untreated female patients. Conversely, higher recovery rates for treated patients in each subpopulation are consistent with a lower recovery rate in the total population when data are aggregated. The arithmetical structures that underlie facts like these invalidate a cluster of arguments that many people, at least initially, take to be intuitively valid. E.g., despite intuitions to the contrary, the following argument is invalid.
The probability of male patients recovering following treatment is greater than the probability of their recovering following no treatment.
The probability of female patients recovering following treatment is greater than the probability of their recovering following no treatment.
Therefore, the probability of (male and female) patients recovering following treatment is greater than the probability of their recovering following no treatment.
Further, the arithmetical structures that invalidate such arguments pose deep problems for inferences from statistical regularities to conclusions about causal relations. Robust associations between variables can mask underlying causal structures that, when made explicit, expose the associations to be causally spurious. In the example above, higher recovery rates in each subpopulation are not sufficient to establish that a proposed treatment is causally effective in promoting recovery. Provided that the sample space is large enough to support causal inferences, different partitions of the population will exhibit different regularities that can appear to support incompatible conclusions about whether a treatment is causally effective. However, once the arithmetical structures that underlie arguments like the one above are made explicit, the structures provide a rich resource for providing causal models for actual and possible causal systems that are initially puzzling and can appear to be impossible. These include causal models for the evolution of traits such as altruism in a setting in which natural selection disadvantages individuals who confer net benefits on their competitors.
Section 1 provides a brief history of Simpson's Paradox, a statement and diagnosis of the arithmetical structures that give rise to it, and the boundary conditions for its occurrence. Section 2 examines patterns of invalid reasoning that have their sources in Simpson's Paradox and possible ways of countering its effects. A particularly important case where Simpson's Paradox has been invalidly employed is discussed in Section 3. It has been mooted that paradoxical data provide counter-examples to the Sure Thing Principle in theories of rational choice. Why such data appear to provide counter-examples to the Sure Thing Principle is explained, and the appearance that they do so is dispelled. Section 4 discusses the roles and implications of paradoxical data for theories of causal inference and for analyses of causal relations in terms of probabilities. While the conclusions of this section are largely negative, Section 5 illustrates how apparently paradoxical data can support causal models for the evolution of traits that at first appear to be incompatible with a setting in which natural selection disadvantages individuals that exhibit the traits.
- 1. Simpson's Paradox: Its History, Diagnosis, and Boundary Conditions
- 2. Simpson's Reversals of Inequalities as Sources of Invalid Reasoning
- 3. Do Paradoxical Data Provide Counter-examples to the Sure Thing Principle?
- 4. Simpson's Reversals of Inequalities, Correlations, and Causation
- 5. Simpson's Reversal of Inequalities in Evolutionary Settings
- Bibliography
- Other Internet Resources
- Related Entries
1. Simpson's Paradox: Its History, Diagnosis, and Boundary Conditions
1.1 History
In a seminal paper published in 1951, E. H. Simpson drew attention to a simple fact about fractions that has a wide variety of surprising applications (Simpson 1951). The applications arise from the close connections between proportions, percentages, probabilities, and their representations as fractions. While statisticians in the early 20th Century had known of the problems for statistics to which Simpson drew attention, it was his witty and surprising illustrations of them that earned them the title of being paradoxical (cf. Yule 1903). In 1934, Morris Cohen and Ernst Nagel introduced philosophers to one aspect of the problems posed by paradoxical data. They cited actual death rates in 1910 from tuberculosis in Richmond, Virginia and New York, New York that verified the following propositions (Cohen & Nagel 1934):[1]
The death rate for African Americans was lower in Richmond than in New York.
The death rate for Caucasians was lower in Richmond than in New York.
The death rate for the total combined population of African Americans and Caucasians was higher in Richmond than in New York.
They next posed two questions about the data concerning mortality rates: “Does it follow that tuberculosis caused [italics added] a greater mortality in Richmond than in New York…” and “…are the two populations that are compared really comparable, that is, homogeneous?” (Cohen & Nagel 1934). After posing the questions, they left it as an exercise for the reader to answer them. Following the publication of Simpson's paper, statisticians initiated a lively debate about the significance of facts like those that are verified by the tables Cohen and Nagel cited. The debate sought constraints on statistical practice that would avoid conundrums arising from actual and possible paradoxical data. However, this debate did not address the first question posed by Cohen and Nagel concerning causal inference. As Judea Pearl notes in his survey of the statistical literature on Simpson's paradox, statisticians had an aversion to talk of causal relations and causal inference that was based on the belief that the concept of causation was unsuited to and unnecessary for scientific methods of inquiry and theory construction (Pearl 2000, 173–181).
Philosophical interest in Simpson's paradox was rekindled by Nancy Cartwright's use of it in support of her claims that appeals to causal laws and causal capacities are required by scientific inquiry and by theories of rational choice (Cartwright 1979). She aimed to show that reliance on regularities and frequencies on which probability judgments can be based are not sufficient for representing causal relations. In particular, tests of scientific theories and philosophical analyses of causation and causal inference need to provide answers to questions like those posed by Cohen and Nagel: e.g., is it possible that tuberculosis caused greater mortality in Richmond than New York even if the mortality rates for each sub-population classified by race appears to suggest otherwise? If causal relations track regularities, what system of causal relations can achieve such effects? Once representations of causal relations that provide answers to questions like those posed by Cohen and Nagel are at hand, the representations turn out to have interpretations that provide causal models for a range of interesting and puzzling phenomena. These include causal models for the evolution of altruism as a stable trait in a population even though altruistic acts disadvantage those who perform them and advantage their competitors. (See Sober 1993, and Sober & Wilson 1998, which develop these themes in detail in the areas of population biology and sociobiology.) Examples of such models are formulated and discussed in Section 5.
1.2 What is Simpson's Paradox?: A Diagnosis
For some whole numbers we may have:
- a/b < A/B,
- c/d < C/D, and
- (a + c)/(b + d) > (A + C)/(B + D).
Call this a Simpson's Reversal of Inequalities. Below is an instructive illustration. The arithmetical inequalities on which it is based are:
- 1/5 < 2/8
- 6/8 < 4/5
- 7/13 > 6/13.
The following interpretation of the structure illustrates why it can give rise to perplexity. The example is loosely based on a discrimination suit that was brought against the University of California, Berkeley (see Bickle et al., 1975).
Suppose that a University is trying to discriminate in favour of women when hiring staff. It advertises positions in the Department of History and in the Department of Geography, and only those departments. Five men apply for the positions in History and one is hired, and eight women apply and two are hired. The success rate for men is twenty percent, and the success rate for women is twenty-five percent. The History Department has favoured women over men. In the Geography Department eight men apply and six are hired, and five women apply and four are hired. The success rate for men is seventy-five percent and for women it is eighty percent. The Geography Department has favoured women over men. Yet across the University as a whole 13 men and 13 women applied for jobs, and 7 men and 6 women were hired. The success rate for male applicants is greater than the success rate for female applicants.
Men Women History 1/5 < 2/8 Geography 6/8 < 4/5 University 7/13 > 6/13
How can it be that each Department favours women applicants, and yet overall men fare better than women? There is a ‘bias in the sampling’, but it is not easy to see exactly where this bias arises. There were 13 male and 13 female applicants: equal sample sizes for both groups. Geography and History had 13 applicants each: equal sample sizes again. Nor does the trouble lie in the fact that the samples are small: multiply all the numbers by 1000 and the puzzle remains. Then the reversal of inequalities becomes fairly robust: you can add or subtract quite a few from each of those thousands without disturbing the Simpson's Reversal.
The key to this puzzling example lies in the fact that more women are applying for jobs that are harder to get. It is harder to make your way into History than into Geography. (To get into Geography you just have to be born; to get into History you have to do something memorable.) Of the women applying for jobs, more are applying for jobs in History than in Geography, and the reverse is true for men. History hired only 3 out of 13 applicants, whereas Geography hired 10 out of 13 applicants. Hence the success rate was much higher in Geography, where there were more male applicants.
1.3 Boundary Conditions for Simpson's Reversals
Simpson's Reversal of Inequalities occurs for a wide range of values that can be substituted for a, b, c, d, A, B, C, D in the above schema. The values fall within a broad band that lies between two extremes:
On one extreme, slightly more women are applying for jobs that are much harder to get.
Men Women History 1/45 < 5/55 Geography 50/55 < 45/45 University 51/100 > 50/100
On the other extreme, many more women are applying for jobs that are slightly harder to get.
Men Women History 4/5 < 90/95 Geography 94/95 < 5/5 University 98/100 > 95/100
Further, the numerators and denominators of fractions that instantiate the schematic pattern can be uniformly multiplied by any positive number without perturbing the relations between the fractions. Fractions that exhibit these patterns correspond to percentages and probabilities. In their probabilistic form, Colin Blyth provides the following boundary conditions for Simpson's Reversals (Blyth 1972). Let ‘P’ represent a probability function, and take conditional probabilities to be ratios of unconditional probabilities in accordance with their orthodox definition; i.e., reading the ‘/’ in the context P(--/..) as ‘given that’,
P(A/B) = P(A&B)/P(B), provided that P(B) is positive.
Blyth notes that from a mathematical standpoint, subject to the conditions
P(A/B&C) ≥ δ . P(A/~B&C)
P(A/B&~C) ≥ δ . P(A/~B&~C)
with δ ≥ 1, it is possible to have
P(A/B) ≈ 0 and P(A/~B) ≈ 1/δ.
On the assumption that the propositions of arithmetic are necessary, these possibilities are tantamount to existence conditions in arithmetic. The schema:
[If it is possible that A is necessary, then A]
is valid in a large family of modal logics. The boundary conditions for Simpson's Reversals allow that any probabilistic association between A and B can be inverted in some further partition of B. From the standpoint of arithmetic there is a partition {C,~C} within which associations between A and B are inverted. An important related consequence is that it is always mathematically possible to provide some condition or factor C that renders A probabilistically independent of B when C is conjoined with B as a condition on A and with ~B as a condition on A. These facts of arithmetic carry no empirical significance by themselves. However, they do have methodological significance insofar as substantive empirical assumptions are required to identify salient partitions for making inferences from statistical and probability relationships.
The need for substantive empirical assumptions arises in settings where there are instances of arithmetical possibilities that are marked out by Simpson's Reversals in urn models and in possible and actual empirical settings. For example, consider an urn model for our story about the success rates for job applicants. The model consists of twenty-six balls. Each ball is labeled with one of the elements from the sets {M, ~M}, {H, ~H}, and {S, ~S}, e.g., a given ball might be labeled [~M, H, ~S] Assume that the labels are distributed to correspond to the distributions of job applicants. In trials of drawing balls from the urn with replacement, the associations between the M's, H's, and S's in the sub-populations, and the reverse association between M's and S's in the overall population, are resilient. The resilient associations are due only to the structure of the model and do not have any causal significance. By way of contrast, substantive assumptions are required to draw inferences in other cases.
Patterns in data that fall within the boundary conditions for Simpson's Reversals of Inequalities can raise problems for testing and evaluating empirical hypotheses, e.g., testing the effectiveness and safety of medical procedures. A course of treatment for a malady that affects the staff of History and Geography can be correlated with a lower death rate for treated compared with untreated patients in History, and a lower death rate for treated compared with untreated patients in Geography; yet, the course of treatment may nevertheless correlate with a higher death rate when treated patients are compared with untreated patients overall. Conversely, a treatment can be correlated with higher mortality rates in each sub-population, while it is correlated with a lower mortality rate in the total population. In such cases it is far from clear what, if anything, to conclude from the correlations about the effectiveness and safety of the treatment.[2] Moreover, with patterns like those surmised for this example, different ways of partitioning the same data can produce different correlations that appear to be incompatible with the correlations under the initial way of partitioning the data. E.g., under a partition by academic discipline, patients appear to fare worse when treated, even though there can be a positive correlation in the total population between treatments and recoveries. This is consistent with a positive correlation between treatments and recoveries when the population is partitioned by gender. While Historians and Geographers each fare worse given the treatment, males and females from the two Departments can each fare better given the treatment, and these facts are consistent with the combined population faring better, or with the combined population faring worse.[3]
The aforementioned possibilities are due to the fact that the following formulae are collectively consistent. Take ‘P’ to be a probability function. Probability models can be provided that verify the consistency of the set consisting of the following formulae:
P(A/B) > P(A/~B)
P(A/B & C) < P(A/~B & C)
P(A/B & ~C) < P(A/~B & ~C)
P(A/B & D) > P(A/~B & D)
P(A/B & ~D) > P(A/~B & ~D)
Similar inequalities are possible with signs reversed, and equalities that represent probabilistic independence are consistent with positive and/or negative associations in partitions of the populations. These facts are not paradoxical from an arithmetical point of view. However, regularities that can be represented by them cannot all be assigned causal significance, and probabilistic equalities that are sufficient for probabilistic independence cannot all be taken to represent causal independence.
Standard statistical methods for significance testing offer no insurance against conflicting results when data are partitioned or consolidated. In a setting where the effectiveness of a new medical treatment is under test, the following data support rejecting the null hypothesis, at the .05 level, that treatment (T) makes no difference to recovery (R), where the alternative to the null hypothesis is that treatment is favorable for recovery.[82]
R ~R T 369 340 ~T 152 176
However, in this model, when the population is further partitioned by gender, the opposite recommendation for males and for females is supported at the .05 level of significance.
RM ~RM R~M ~R~M T 48 152 321 188 ~T 73 145 79 31
Take the null hypothesis to be that there is no association between treatments and recoveries, and the alternative to the null hypothesis that treatment is less favorable for recovery than no treatment. Rejecting the null hypothesis falls within the .05 level of significance for both the M-tables and the ~M-tables. So, when the consolidated data are considered, treatment is favored, but when the population is partitioned by gender, no treatment is favored for both males and females. A further partition, e.g., a partition by age groups, can reverse the associations within partitions by gender. So treatments can be positively correlated with recoveries in the total population, negatively correlated with recoveries when the population is partitioned by gender, and positively correlated with recoveries when the population is partitioned by age. The generality of the boundary conditions for Simpson's reversals of inequalities guarantees that there always are models in arithmatic that accomodate data and support conflicting recommendations. Arithmatic is silent on which partitions to take as the basis for evaluating conflicts between hypotheses given data and the ways data can be partitioned.
2. Simpson's Reversals of Inequalities as Sources of Invalid Reasoning
Intuitive reasoning about percentages and probability relations is notoriously accident prone. The example that was based on the suit brought against Berkeley illustrated how a bias in hiring practices in each department of a university can be inverted when the data are pooled. But many people at least initially would deem it impossible that a higher percentage of males were successful in a setting where females had higher success rates in each department in which appointments were made. One way to view the flaw in intuitive reasoning that arises from Simpson's Reversals is by noting that the representation of data from partitions of a population as fractions and the uses to which the fractions are put when data are pooled to get statistics on total populations is not guaranteed to maintain the relations between fractions within the partitions. Proper fractions have infinitely many equivalent representations. For example, 1/2 = 2/4 = 4/8 = …. Now recall the form of relations between fractions in terms of which Simpson's Reversals were illustrated, i.e.,
- a/b < A/B,
- c/d < C/D, and
- (a + c)/(b + d) > (A + C)/(B + D).
Now, treating terms as proper fractions, we can have a/b = 2a/2b, and A/B = 5A/5B; c/d = 3c/3d, and C/D = 4C/4D. However, when these equivalent representations are pooled, the resulting relations between fractions will often differ from the original relations. E.g., (2a + 3c)/(2b + 3d) can be more or less than (a + c)/(b + d). Hence, it is invalid to conclude that relations between percentages or ratios when data are pooled will conform to the regularities that are exhibited by the sets that comprise partitions of the data. Equivalent representations of ratios make different contributions when data are pooled.
One way to arithmetically counter this difficulty is by ‘normalizing’ the representations of data from sub-populations and only pooling the normalized representations of the data. Normalizing data counters the effects of skewing by providing constant denominators for the fractions that represent the data, and by representing the sub-populations that are compared as if they were of equal sizes in the relevant respects in terms of which they are compared. However, Simpson's Reversals show that there are numerous ways of partitioning a population that are consistent with associations in the total population. A partition by gender might indicate that both males and females fared worse when provided with a new treatment, while a partition of the same population by age indicated that patients under fifty, and patients fifty and older both fared better given the new treatment. Normalizing data from different ways of partitioning the same population will provide incompatible conclusions about the associations that hold in the total population.
A related point comes out even more vividly when fractions are interpreted as probabilities. It was noted above that a Simpson's Reversal can take the following probabilistic form: It is possible to have
P(A/B) > P(A/~B), where
P(A/B & C) < P(A/~B & C) and
P(A/B & ~C) < P(~B & ~C).
One way for intuitive reasoning to overlook this possibility is by overlooking the so-called law of total probability and its relevance to this setting. From the probability calculus we have the following equivalences that represent probabilities as weighted averages.
P(A/B) = P(A/B & C)P(B/C) + P(A/B & ~C)P(B/~C)
P(A/~B) = P(A/~B & C)P(~B/C) + P(A/~B & ~C)P(~B/~C)
Skewed weights for P(B/C), P(B/~C), P(~B/C), and P(~B/~C) create the range of possibilities that are marked out by the boundary conditions for Simpson's Reversals. E.g., let P(A/B) = .54 and P(A/~B) = .44. So, B is positively relevant to A. Let the weights that feature in the representation of these probabilities in terms of a factor C be as follows: P(B/C) = .28, P(~B/C) = .72, P(B/~C) = .66, and P(~B/~C) = .34. Given these weightings, B will be positively relevant to A, but it will be negatively relevant to A in each of the cells provided by the partition {C, ~C}. I.e., P(A/B&C) = .27 and P(A/B&~C) = .33, and P(A/~B&C) = .64, and P(A/~B&~C) = .66.[4] If, as a matter of habit, intuitive reasoners tend to ignore the effects of such skewing, they will be taken aback when Simpson's Reversals turn up in actual and possible data. Of course, it is an empirical question whether such oversight is the source of invalid reasoning, or whether another hypothesis better explains why many people find Simpson's Reversals to be impossible at first, and why the reversals continue to be surprising even after their source has been explained to them.
3. Do Paradoxical Data Provide Counter-examples to the Sure Thing Principle?
The so-called Sure Thing Principle (hereafter STP) is fundamental for theories of rational decision. L. J. Savage provides the following formulation of it:
If you would definitely prefer g to f , either knowing that the event C obtained, or knowing that the event C did not obtain, then you definitely prefer g to f (Savage 1954, 21–2).
In theories of rational choice in which preferences are ordered by the rule of maximizing expected utility, STP is a consequence of the fact that the expected utility of an option can be represented as a probabilistically weighted average of the expected utilities of mutually exclusive and collectively exhaustive ways the world could be on the assumption that the option is chosen. E.g., with ‘EU’ representing a function that assigns expected utilities and ‘P’ a probability function,
EU(A) = EU(A&B)P(B) + EU(A&~B)P(~B)
When you know that B holds, it becomes a parameter for the expected utility of A, and similarly when you know that ~B holds. So if the expected value that is assigned to C is less than A on the assumption you know that B obtains, and similary on the assumption that B does not obtain, then the expected value of C is unconditionally less than the expected value of A.
Now suppose that you are offered bets on applicants gaining jobs in the example concerning the two departments. Your options are to bet on a randomly drawn successful applicant being male, or to bet on a randomly drawn successful applicant being female. Let C be the event of applying for a job in History, and ~C be the event of applying for a job in Geography. (Every person in the relevant domain applies for exactly one position.) Given that the success rates for females were greater than that for males in both departments, does the STP recommend that you should back females as the bettor's choice? One might (invalidly) reason as follows: given that females have a greater chance of success in their applications given C and given ~C, STP recommends a preference for bets on females in a lottery in which you are betting on the gender of successful applicants. Of course, this would be bad advice in the setting of the example, as the success rate for males was greater overall. Given a suitably large number of bets, a clever bookie could be assured of a handsome profit if bettors backed females in the competitions for jobs. Their success rate was lower than their male competitors’ success rate overall despite being higher in each department.
To see what has gone awry in the attempt to apply STP in this setting it suffices to note that a random draw from successful applicants is made from the mixture that contains males and females, and there are more males in the mixture. (Recall that females were applying in greater numbers for jobs that were harder to get.) It is insufficient for the applicability of the Principle that probabilities line up with females having a greater chance of success in each department. The Principle applies to preferences , taken as weighted averages of utilities with probabilities supplying the weights. The presented options are
Option 1: A randomly drawn successful applicant is female.
Option 2: A randomly drawn successful applicant is male.
To be told that a selected applicant applied for a position in History (C) or in Geography (~C) does not affect the probabilities of success in the mixture. This is evident when the expected utilities of the options are explicitly represented as weighted averages. Using ‘M’ for male, ‘~M’ for female, ‘S’ for successful, and ‘C’ and ‘~C’ as above, the expected utilities for the options are as follows.
Option 1: EU(~M&S) =
EU(~M&S&C)P(C/S&~M) + EU(~M&S&~C)P(~C/S&~M)Option 2: EU(M&S) =
EU(M&S&C)P(C/S&M) + EU(M&S&~C)P(~C/S&M)
Given the figures that were used in the example, the probability relations between the weightings are as follows:
P(C/S&~M) > P(C/S&M) and P(~C/S&~M) > P(~C/S&M)
It is these relations that are the source of the illusion that STP selects Option 1. The probability of a successful female applicant having applied for a position in History is greater than that of her male competitor among the applicants in History, and similarly for females in Geography. If the candidates had been sorted by their applications to the respective departments, where females had higher success rates, and the drawing was done from a randomly chosen department (with repeated draws and replacement until a successful applicant is drawn) rather than from the mixture of successful applicants, then the best choice would be for the gender with the higher success rates in the respective departments, i.e., females. Such an arrangement would not be affected by the fact that more women applied for jobs that were harder to get. But that is not the arrangement that has been stipulated for the bets where selection is made from the pooled successful applicants. The chances of selecting a male (or a female) from that mixture are independent of the department to which the successful applicants had applied. Accordingly, rational bettors will find STP to be inapplicable in the setting, because they will not have the preferences that its application requires, i.e., a preference for females, given that they applied for a job in History (C), and a preference for females, given that they applied for a job in Geography (~C). For rational bettors, EU(~M&S) = EU(~M&S&C) = EU(~M&S&~C), and similarly for M's, while, on the figures provided in the example, EU(~M&S) < EU(M&S).
4. Simpson's Reversals of Inequalities, Correlations, and Causation
It is a commonplace that correlations between variables do not entail that they stand in causal relations. While some correlations are purely accidental, others can be lawful even when no causal connection obtains between the correlated variables — e.g.,the correlation between falling barometers and rain is lawful because they are joint effects of a common cause, i.e., falling air pressure. Controlled experiments seek to expose correlations that are merely accidental. What then of robust correlations between variables that do not causally interact? Hans Reichenbach proposed that a robust correlation between variables is spurious [acausal] when there is a factor that ‘screens off’ the correlation and serves as a common cause of the associated variables (Reichenbach 1971, Ch. 4). Say that A is associated with B if and only if they are not probabilistically independent, i.e., P(A/B) ≠ P(A). Reichenbach proposed that such an association is spurious provided that there is a factor C such that P(A/B&C) = P(A/C).
Simpson's Reversal of Inequalities illustrates that from an arithmetical point of view, there always is a factor or proposition C that ‘screens off’ any correlation. The existence of such a factor cannot be sufficient for a correlation to be spurious. For example, suppose that the probability of A given B is greater than without B. The following diagram illustrates this possibility with probabilities corresponding to the proportional sizes of enclosed spaces with all of A represented by the enclosed rectangle that is intersected by the line dividing B from ~B.
P(A/B) > P(A/~B)
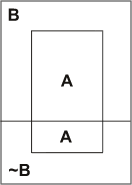
The boundary conditions for Simpson's Reversals guarantee that there is a C that intersects equal parts of A&B and A&~B. In Section 1 it was noted that arithmetical possibilities are tantamount to existence conditions for arithmetical facts. Provided that a sample space can be partitioned sufficiently finely, the probabilistic relevance between A and B can be “washed out” by some arbitrary factor C within which the probabilities of A&B and A&~B are equal. The following diagram illustrates this arithmetical possibility:
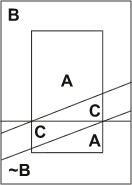
P(A/B&C) = P(A/~B&C)
where C is represented by the parallelogram that is bisected by the boundary between B and ~B and comprises equal parts of A&B and A&~B. C is an arbitrary proposition or factor. As enclosed spaces correspond to probabilities, P(A/B&C) = P(A/~B&C). So, C ‘screens off’ A from B; however, its existence is clearly insufficient to show that the correlation between A and B is spurious. While ‘screening off’ may provide a necessary condition for showing that a correlation between variables is due to a common cause, this necessary condition is guaranteed to be fulfilled by the underlying arithmetic of the probability calculus. Further substantive conditions have to be provided over and above the probability relations between A, B, and C in order to identify C as a common cause of A and B.
The inference that lawfully correlated variables are causally independent of each other if the correlation is due to a common cause is a special case of a more general view that causes increase the chances of their effects.[5] When there is a common cause C of a correlation between variables B and A, B does not cause A; the raising of A's chances is due to C, and while B might be a symptom of A, it is so by virtue of being a separate effect of C that precedes A. The following diagram illustrates these relationships. (Arrows represent the directions of causal connections.)
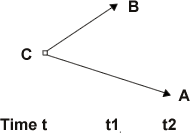
B precedes A and C is a common cause of B and A
Given C, B does not raise A's chances. The underlying idea behind analyses of causation in terms of chance raising is that causes promote their effects. In deterministic settings, chances take only extreme values, and causes do not ‘raise’ an effects’ chances of occurring except in the degenerate sense that they raise the chances of their effects from zero without them to one with them (excluding cases of deterministic overdetermination). However, it is a contingent matter whether the world we inhabit is deterministic or indeterministic, and concepts of causation need to accommodate the latter possibility as well as the former. Then, representations of deterministic causation can be viewed as a special case of probabilistic causation in which causes are sufficient and necessary for their effects.
In view of Simpson's Reversals of Inequalities, probability relations between variables will vary widely under different partitions of populations or state spaces. This fact about probability relations provides an invaluable resource for the representation in probabilistic terms of the complex relations that hold between networks of causes and their effects. Causes not only can promote effects, but they can promote the absence of or inhibit effects that might occur in their absence. E.g., regular exercise inhibits or reduces the chances of cardiovascular disorders. Accordingly, whatever promotes regular exercise also promotes cardiovascular health even if it also promotes cardiovascular disease. Cartwright gives the following example. Smoking causes heart disease, but it also could cause smokers to take up exercise in greater numbers than non-smokers. In that case smoking could indirectly cause cardiovascular health while directly causing disease. With plus and minus signs indicating whether a cause promotes or inhibits an effect, the following diagram represents a causal set-up in which smoking could promote cardiovascular health while directly promoting disease.
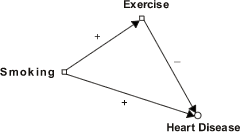
E.g., if smoking increases the chances of heart disease by 25%, but also increases the chances of regular exercise by 40% while exercise decreases the chances of disease by 70%, smokers will on balance benefit from their habit with respect to cardiovascular health. In this set-up, there could be a Simpson's Reversal where smokers who exercise fare worse than non-smokers who exercise, and similarly for smokers who do not exercise compared with non-smokers, while the smokers’ rates of disease are lower overall. The net causal effect of smoking on health is positive in the example due to the contribution of a third variable, exercising, that is an effect of smoking. It is the causal contributions of further variables that are the sources of Simpson's Reversals in other causal set-ups where the effects of direct causal links are modified by the additional variables’ contributions. These include cases where direct effects are nullified by inhibitory effects of an accompanying factor, e.g., substances that are separately poisonous, acid and alkali, can interact to have no deleterious effect when they are taken together. Each acts as an antidote for the other.[6] Further entanglements include cases where a cause that promotes an effect is accompanied by an inhibitory cause of the effect and they are both effects of a common cause. E.g.,
E's chance is unperturbed
A common cause
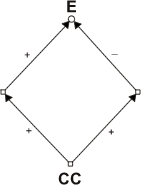
An interpretation of this diagram: thrombosis can be an effect of pregnancy and it can also be an effect of some of the ingredients of birth control pills. Both pregnancy and the pills increase the chances of thrombosis. However, the pills decrease the chances of pregnancy, and the net effect on populations of women who take the pills could show no change in the frequency of thrombosis. Examples such as those that have been canvassed show that it is neither necessary nor sufficient for a causal relation between two variables that one raise the chances of the other. Cartwright (2001, 271) puts the matter in the following terms: ‘Causes can increase the probability of their effects; but they need not. And for the other way around: an increase in probability can be due to a causal connection; but lots of other things can be responsible as well.’
Is Cartwright's observation cause for pessimism about the program of analyzing causation and causal relevance in probabilistic terms? Not necessarily. It sets a problem about causal entanglements that are not tracked by probability relations and probabilistic entanglements that are not due to causal relations. The program of providing probabilistic representations of causal relations needs to provide conditions that disentangle causal networks. What is required is a way of locating the right partitions of populations, where the right ones are the ones whose probability relations do track causal connections while holding relevant background factors fixed. A number of different proposals have been put forward in the literature on probabilistic causation that aim to provide criteria for locating the right partitions of data for the purpose of identifying causal connections.
The proposals fall into two broad categories: (1) Reductive proposals: these do not appeal to causal concepts and they aim to provide a filter on correlations that identifies which correlations are spurious. Correlations that are not spurious are meant to conform to intuitions about causal relations and to implement the roles that are intuitively assigned to causal relations.[7] (2) Non-reductive proposals: these are unabashed about using causal concepts to distinguish between spurious and causal correlations. Proposals from this second group are generally skeptical about the Humean program that motivates reductive proposals, and set-ups that are instances of Simpson's Reversals are one of their main critical scalpels (Cartwright 1979, and especially Dupre & Cartwright 1988). Nevertheless, they too face the problem of providing a filter on correlations that marks out which of them are spurious, but they do not feel constrained to avoid reference to causal relations in providing criteria for selecting partitions that provide reliable data for causal inferences. In sum, both reductionists and anti-reductionists who endorse the program of representing causal relations in terms of probability relations propose that
C causes E if and only if the probability of E is greater given C than given not C, provided that …X….
The proviso is needed to filter cases where probability relations between C-type events and E-type events do not track causal relations. Their opinions divide on whether causal concepts need to or can be used without vicious circularity in spelling out the content of the proviso …X…. Reductionists seek ways of spelling out the proviso in terms of homogenous reference classes, where homogeneity is spelled out in terms of robust correlations conditional on a set of factors that are held fixed. Anti-reductionists are quick to ask: which factors? To take all possible factors to be relevant is not only epistemologically intractable, but it can lead to silly conclusions insofar as all but absolutely fundamental causal processes can be manipulated by introducing some intervening factors. E.g., the probability of death given a heart attack is greater than without the heart attack, but the contribution of the heart attack is ‘screened off’ in cases where the heart attack coincides with being run down by a truck. In this example, the chances of death are overdetermined. Cases of causal overdetermination are extreme examples of causal networks in which probabilistic relevance is washed out or inverted by the causal contributions of an exogenous variable. In the experimental sciences, attempts at isolating interactions between factors from intervening variables are standard procedure. However, what is achievable even in the best laboratory conditions will fall short of the ideal of showing that there are no intervening factors on which a correlation is dependent. To show the latter would require showing that a negative existential proposition is true.
Anti-reductionists have a ready answer to the question of which factors have to be held fixed when evaluating probabilistic dependencies and probabilistic independence. They want all potentially causally relevant factors that are of interest to be held fixed for the purposes of identifying the probability relations between C and E that are due to and are apt for representing causal connections. According to this approach, reference classes that are causally homogenous provide the proper basis for evaluating probability relations. One then looks to background scientific theories and other knowledge of causal relations to determine whether reference classes are causally homogenous.[8] In many cases, however, our curiosity about causal relations outstrips our current knowledge of causally relevant variables that need to be held fixed. Then, inferences to causal relations from statistical data that can always be counter-posed with reversed regularities in different partitions of the data can lead to inconsistent claims concerning causal relations.
5. Simpson's Reversal of Inequalities in Evolutionary Settings
Simpson's Reversals of Inequalities have applications in economic theory and population genetics, especially in cases involving competition among businesses or organisms. In the above example of differential hiring of men and women, imagine that we were to map the women onto, say, ‘lemmings’ and the men onto, say, ‘rats’. Imagine the lemmings to be altruistic and self-sacrificing, or alternatively imagine them to be irrational, inefficient or lazy — either way, by one means or another, imagine that they behave in ways that benefit their neighbours at their own expense. Imagine the rats to be selfish, rational and efficient, and regularly to gain benefits at the expense of their neighbours.
Next, map the History Department onto Norway during a very severe winter in Norway, and suppose there are more rats than lemmings in Norway. Then life is tough for everyone in Norway, and it is even tougher for lemmings than for rats. Map the Geography Department onto Sweden which is in the midst of a very mild winter, and suppose there to be more lemmings than rats in Sweden. Then life is easier for everyone in Sweden, though it is even easier for free-riding and opportunistic rats than it is for lemmings. Finally, consider the reproductive rates for rats and lemmings in the total land mass of the two countries. (Or, if these ‘rats’ and ‘lemmings’ were businesses, consider their relative bankruptcy rates.) The numbers might then display the same pattern that we described for hiring rates of men and women at the University of California:
| Lemmings | Rats | ||
|---|---|---|---|
| Norway | (1×109)/(5×109) | < | (2×109)/(8×109) |
| Sweden | (6×109)/(8×109) | < | (4×109)/(5×109) |
| Scandinavia | (7×109)/(13×109) | > | (6×109)/(13×109) |
Lemmings are losing ground in Norway, and they are losing ground in Sweden; yet they are gaining ground in combined areas that constitute the two countries.
The reason that lemmings are gaining ground in the combined area of the two countries is that more of the lemmings are living where the survival rate is higher. Note that the survival rate is higher there precisely because that is where more of the lemmings are living. Thus, if rats congregate together, the selfish efficiency of each rat will be bad not only for the poor lemmings in the neighborhood but also for other rats. Even if only slightly more of the rats are living in one region rather than another, if the benefits they gain at their neighbors’ expense become too extreme then this will reduce the survival rate of everyone in that neighborhood, rats included; this will precipitate a Simpson's Reversal, and the number of rats will begin to go down globally when compared with lemmings.
In both Darwinian evolutionary theory and much of economic theory, it is hard to see how ‘altruism’ (or, for that matter, systematic inefficiency) could evolve, or be sustained over the long term. That is, it is hard to see how a population could sustain heritable patterns of behaviour that benefit the competitors of an individual business or organisms at the expense of the long-term chances of survival or reproductive success for those individuals and others with the same dispositions. For this reason it is of considerable theoretical significance to explore the applications of Simpson's Paradox, to see whether this might help to explain not only the altruism but also the irrationality, inefficiency, laziness and other vices that may prevail in populations, and that can cause a population to fall short of the economic rationalist's or Darwinian's ideal of the ruthlessly efficient pursuit by each individual of its own profits or long-term reproductive success.
Sam Butchart has devised two Games that illustrate the dynamics of survival and reproduction in settings where Simpson's Reversals occur. (See the link in the Other Internet Resources section below.) One, Sharks and Suckers, is modeled on John Conway's ‘Game of Life’. The other, Rats and Lemmings, is modeled on Axelrod's tournaments of iterated rounds of ‘Prisoner's Dilemma’. In these games, it is a surprising result that populations robustly sustain a proportion of Suckers or Lemmings in the long term. Sharks and Rats never disappear completely, but nor do they ever take over completely. Thus, Simpson's Paradox places a constraint on how selfish, how efficient and how rational businesses or organisms can become. On balance, this is probably cheerful news.
Bibliography
- Axelrod, R., 1984, The Evolution of Cooperation, New York: Basic Books.
- Bickel, P. J., Hjammel, E. A., and O'Connell, J. W., 1975, “Sex Bias in Graduate Admissions: Data From Berkeley”, Science, 187: 398–404.
- Blyth, C. R., 1972, “On Simpson's Paradox and the Sure Thing Principle”, Journal of the American Statistical Association, 67: 364–366.
- Cartwright, N., 1979, “Causal laws and effective strategies”, Noûs, 13 (4): 419–437.
- Cartwright, N., 2001, “What is wrong with Bayes Nets?”, The Monist, 84 (2): 242–265. Reprinted in Probability is the Very Guide of Life, H. E. Kyburg, Jr. and M. Thalos (eds.), Chicago and La Salle, IL: Open Court, 2003, 253–275.
- Cohen, M. R., and Nagel, E., 1934, An Introduction to Logic and Scientific Method, New York: Harcourt, Brace and Co.
- Dawid, A. P., 1979, “Conditional independence in statistical theory,” Journal of the Royal Statistical Society (Series B), 41: 1–15.
- Dupre, J. and Cartwright, N., 1988, “Probability and causality: Why Hume and indeterminism don't mix”, Noûs, 22: 521–536.
- Eells, E., 1987, “Cartwright and Otte on Simpson's Paradox,” Philosophy of Science, 54: 233–243.
- Glymour, C. and Meek, C., 1994, “Conditioning and Intervening”, British Journal for the Philosophy of Science, 45: 1001–1021.
- Hardcastle, V.G., 1991, “Partitions, probabilistic causal laws, and Simpson's Paradox,” Synthese, 86: 209–228.
- Hesslow, G., 1976, “Discussion: Two notes on the probabilistic approach to causality,” Philosophy of Science, 43: 290–292.
- Lindly, D. V., and Novick, M. R., 1981, “The role of exchangeability in inference”, Journal of the American Statistical Association, 9: 45–58.
- Malinas, G., 1997, “Simpson's Paradox and the wayward researcher”, Australasian Journal of Philosophy, 75: 343–359.
- Malinas, G., 2001, “Simpson's Paradox: A logically benign, empirically treacherous hydra”, The Monist, 84 (2): 265–284. Reprinted in Probability Is the Very Guide of Life, Henry E. Kyburg, Jr. and Mariam Thalos (eds.), Chicago and La Salle, IL: Open Court, 2003, 165–182.
- Mittal, Y., 1991, “Homogeneity of subpopulations and Simpson's Paradox”, Journal of the American Statistical Association, 86: 167–172.
- Otte, R., 1985, “Probabilistic causality and Simpson's Paradox”, Philosophy of Science, 52: 110–125.
- Pearl, J., 1988, Probabilistic Reasoning in Intelligent Systems, San Mateo, CA: Morgan Kaufman.
- Pearl, J., 2000, Causality: Models, Reasoning, and Inference, New York, Cambridge: Cambridge University Press.
- Reichenbach, H., 1971, The Direction of Time, Berkeley: University of California Press.
- Savage, L. J., 1954, The Foundations of Statistics, New York: John Wiley and Sons.
- Simpson, E.H., 1951, “The interpretation of interaction in contingency tables”, Journal of the Royal Statistical Society (Series B), 13: 238–241.
- Skyrms, B., 1980, Causal Necessity, New Haven; Yale University Press.
- Sober, E., 1993, The Nature of Selection, Chicago: University of Chicago Press.
- Sober, E., 1993, Philosophy of Biology, Oxford: Oxford University Press.
- Sober, E. and D. S. Wilson, 1998,Unto Others: The Evolution and Psychology of Unselfish Behaviour, Cambridge, MA: Harvard University Press.
- Spohn, W., 2001, “Bayesian nets are all there is to causality”, in Stochastic Dependence and Causality, D. Constantini, M. C. Galavotti, and P. Suppes (eds.), Stanford: CSLI Publications.
- Sunder, S., 1983, “Simpson's reversal paradox and cost allocations”, Journal of Accounting Research, 21: 222–233.
- Suppes, P., 1970, A Probabilistic Theory of Causality, Amsterdam; North-Holland Publishing Co..
- Thalos, M., 2003, “The Reduction of Causation”, in H. Kyburg and M. Thalos (eds.), Probability is the Very Guide of Life: The Philosophical Uses of Chance, Chicago: Open Court.
- Thornton, R. J., and Innes, J. T., 1985, “On Simpson's Paradox in economic statistics”, Oxford Bulletin of Economics and Statistics, 47: 387–394.
- Van Frassen, B. C., 1989, Laws and Symmetry, Oxford: Clarendon.
- Yule, G. H., 1903, “Notes on the theory of association of attributes in Statistics”, Biometrika, 2: 121–134.
Other Internet Resources
- Butchart, Sam and John Bigelow, Sharks and Suckers and Rats and Lemmings, two computer games designed to illustrate Simpson's Paradox.
- Simpson's Paradox, by Alan Crowe
- Simpson's Paradox — When Big Data Sets Go Bad, in Amazing Applications of Probability and Statistics at www.intuitor.com.
- Online paper by Nick Chater, Ivo Vlaev and Maurice Grinberg, “A new consequence of Simpson's Paradox: Stable co-operation in one-shot Prisoner's Dilemma from populations of individualistic learning agents,” University College London/New Bulgarian University.
Related Entries
causation: probabilistic | game theory: evolutionary | physics: Reichenbach's common cause principle | prisoner's dilemma
Acknowledgments
The authors would like to thank Paul Oppenheimer for spotting an incorrectly specified statistic and probability in Section 1.3 and Section 2, respectively.
Gary Malinas <g.malinas@uq.edu.au>
John Bigelow <john.bigelow@arts.monash.edu.au>