

Probabilistic Causation
“Probabilistic Causation” designates a group of philosophical theories that aim to characterize the relationship between cause and effect using the tools of probability theory. The central idea behind these theories is that causes raise the probabilities of their effects, all else being equal. A great deal of the work that has been done in this area has been concerned with making the ceteris paribus clause more precise. This article traces these developments, as well as recent, related developments in causal modeling. Issues within, and objections to, probabilistic theories of causation will also be discussed.
- 1. Introduction and Motivation
- 2. Preliminaries
- 3. Main Developments
- 4. Counterfactual Approaches
- 5. Causal Modeling and Probabilistic Causation
- 6. Further Issues and Problems
- Bibliography
- Other Internet Resources
- Related Entries
1. Introduction and Motivation
1.1 Regularity Theories
According to David Hume, causes are invariably followed by their effects: “We may define a cause to be an object, followed by another, and where all the objects similar to the first, are followed by objects similar to the second.” (1748, section VII.) Attempts to analyze causation in terms of invariable patterns of succession are referred to as “regularity theories” of causation. There are a number of well-known difficulties with regularity theories, and these may be used to motivate probabilistic approaches to causation.
Suggested Readings: Hume (1748), especially section VII.
1.2 Imperfect Regularities
The first difficulty is that most causes are not invariably followed by their effects. For example, it is widely accepted that smoking is a cause of lung cancer, but it is also recognized that not all smokers develop lung cancer. (Likewise, not all non-smokers are spared the ravages of that disease.) By contrast, the central idea behind probabilistic theories of causation is that causes raise the probability of their effects; an effect may still occur in the absence of a cause or fail to occur in its presence. Thus smoking is a cause of lung cancer, not because all smokers develop lung cancer, but because smokers are more likely to develop lung cancer than non-smokers. This is entirely consistent with there being some smokers who avoid lung cancer, and some non-smokers who succumb.
The problem of imperfect regularities does not tell decisively against the regularity approach to causation. Successors of Hume, especially John Stuart Mill and John Mackie, have attempted to offer more refined accounts of the regularities that underwrite causal relations. Mackie introduced the notion of an inus condition: an inus condition for some effect is an insufficient but non-redundant part of an unnecessary but sufficient condition. Suppose, for example, that a lit match causes a forest fire. The lighting of the match, by itself, is not sufficient; many matches are lit without ensuing forest fires. The lit match is, however, a part of some constellation of conditions that are jointly sufficient for the fire. Moreover, given that this set of conditions occurred, rather than some other set sufficient for fire, the lighting of the match was necessary: fires do not occur in such circumstances when lit matches are not present.
There are, however, disadvantages to this type of approach. The regularities upon which a causal claim rest now turn out to be much more complicated then we had previously realized. In particular, this complexity raises problems for the epistemology of causation. One appeal of Hume's regularity theory is that it seems to provide a straightforward account of how we come to know what causes what: we learn that A causes B by observing that As are invariably followed by Bs. Consider again the case of smoking and lung cancer: on the basis of what evidence do we believe that the one is a cause of the other? It is not that all smokers develop lung cancer, for we do not observe this to be true. But neither have we observed some constellation of conditions C, such that smoking is invariably followed by lung cancer in the presence of C, while lung cancer never occurs in non-smokers meeting condition C. Rather, what we observe is that smokers develop lung cancer at much higher rates than non-smokers; this is the prima facie evidence that leads us to think that smoking causes lung cancer. This fits very nicely with the probabilistic approach to causation.
As we shall see in Section 3.2 below, however, the basic idea that causes raise the probability of their effects has to be qualified in a number of ways. By the time these qualifications are added, it appears that probabilistic theories of causation have to make a move that is quite analogous to Mackie's appeal to constellations of background conditions. Thus it is not clear that the problem of imperfect regulaties, by itself, offers any real reason to prefer probabilistic approaches to causation over regularity approaches.
Suggested Readings: Refined versions of the regularity analysis are found in Mill (1843), Volume I, chapter V, and in Mackie (1974), chapter 3. The introduction of Suppes (1970) presses the problem of imperfect regularities.
1.3 Indeterminism
While Mackie's inus condition approach can rule that smoking causes lung cancer even if there are smokers who do not develop lung cancer, it does require that there be some conjunction of conditions, including smoking, upon which lung cancer invariably follows. But even this more specific regularity may fail if the occurrence of lung cancer is not physically determined by those conditions. More generally, the regularity approach makes causation incompatible with indeterminism: if an event is not determined to occur, then no event can be a part of a sufficient condition for that event. (An analogous point may be made about necessity.) The recent success of quantum mechanics -- and to a lesser extent, other theories employing probability -- has shaken our faith in determinism. Thus it has struck many philosophers as desirable to develop a theory of causation that does not presuppose determinism.
Many philosophers find the idea of indeterministic causation counterintuitive. Indeed, the word “causality” is sometimes used as a synonym for determinism. A strong case for indeterministic causation can be made by considering the epistemic warrant for causal claims. There is now very strong empirical evidence that smoking causes lung cancer. Yet the question of whether there is a deterministic relationship between smoking and lung cancer is wide open. The formation of cancer cells depends upon mutation, which is a strong candidate for being an indeterministic process. Moreover, whether an individual smoker develops lung cancer or not depends upon a host of additional factors, such as whether or not she is hit by a bus before cancer cells begin to form. Thus the price of preserving the intuition that causation presupposes determinism is agnosticism about even our best supported causal claims.
Since probabilistic theories of causation require only that a cause raise the probability of its effect, these theories are compatible with indeterminism. This seems to be a potential advantage over regularity theories. It is unclear, however, to what extent this potential advantage is actual. In the realm of microphysics, where we have strong (but still contestable) evidence of indeterminism, our ordinary causal notions do not easily apply. This is brought out especially clearly in the famous Einstein, Podolski and Rosen thought experiment. On the other hand, it is unclear to what extent quantum indeterminism ‘percolates up’ to the macroworld of smokers and cancer victims, where we do seem to have some clear causal intuitions.
Suggested Readings: Humphreys (1989), contains a sensitive treatment of issues involving indeterminism and causation; see especially sections 10 and 11. Earman (1986) is a thorough treatment of issues of determinism in physics.
1.4 Asymmetry
If A causes B, then, typically, B will not also cause A. Smoking causes lung cancer, but lung cancer does not cause one to smoke. In other words, causation is usually asymmetric. This may pose a problem for regularity theories, for it seems quite plausible that if smoking is an inus condition for lung cancer, then lung cancer will be an inus condition for smoking. One way of enforcing the asymmetry of causation is to stipulate that causes precede their effects in time. Both Hume and Mill explicitly adopt this strategy. This has several systematic disadvantages. First, it rules out the possibility of backwards-in-time causation a priori, whereas many believe that it is only a contingent fact that causes precede their effects in time. Second, this approach rules out the possibility of developing a causal theory of temporal order (on pain of vicious circularity), a theory that has seemed attractive to some philosophers. Third, it would be nice if a theory of causation could to provide some explanation of the directionality of causation, rather than merely stipulate it.
Some proponents of probabilistic theories of causation follow Hume in identifying causal direction with temporal direction. Others have attempted to use the resources of probability theory to articulate a substantive account of the asymmetry of causation, with mixed success. We will discuss these proposals at greater length in Section 3.3 below.
Suggested Readings: Hausman (1998) contains a detailed discussion of issues involving the asymmetry of causation. Mackie (1974), chapter 3, shows how the problem of asymmetry can arise for his inus condition theory. Lewis (1986) contains a very brief but clear statement of the problem of asymmetry.
1.5 Spurious Regularities
Suppose that a cause is regularly followed by two effects. For instance, suppose that whenever the barometric pressure in a certain region drops below a certain level, two things happen. First, the height of the column of mercury in a particular barometer drops below a certain level. Shortly afterwards, a storm occurs. This situation is shown schemaatically in Figure 1. Then, it may well also be the case that whenever the column of mercury drops, there will be a storm. (More plausibly, the dropping of the barometer will be an inus condition for the storm.) Then it appears that a regularity theory would have to rule that the drop of the mercury column causes the storm. In fact, however, the regularity relating these two events is spurious; it does not reflect the causal influence of one on the other.
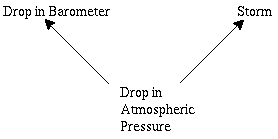
Figure 1
The ability to handle such spurious correlations is probably the greatest success of probabilistic theories of causation, and remains a major source of attraction for such theories. We will discuss this issue in greater detail in Section 3.2 below.
Suggested Readings: Mackie (1974), chapter 3, shows how the problem of spurious regularities can arise for his inus condition theory. Lewis (1986) contains a very brief but clear statement of the problem of spurious regularities.
2. Preliminaries
Before preceding to the formal development of a probablistic theory of causation in the next section, it will be helpful to address a few preliminary points. First, a given event may have many different causes. A match is struck and it lights. The striking of the match is a cause of its lighting, but the presence of oxygen is also a cause, and there will be many others besides. Sometimes, in casual conversation, we refer to one or another of these as “the cause” of the match's lighting. Which cause we single out in this manner may depend upon our interests, our expectations, and so on. Philosophical theories of causation normally attempt to analyze the notion of “a cause.” Note also that causes may be standing conditions -- such as the presence of oxygen -- as well as changes.
Second, it is common to distinguish two different kinds of causal claim. Singular causal claims, such as “Jill's heavy smoking during the ‘80's caused her to develop lung cancer,” relate particular events that have spatiotemporal locations. (Some authors claim that singular causal claims relate facts instead.) When used in this way, cause is a success verb: the singular causal claim implies that Jill smoked heavily during the ‘80's and that she developed lung cancer. Note that this usage is at odds with the usage of “probabilistic causation” in the legal literature. This phrase is used when an individual is exposed to a risk (such as a carcinogen) regardless of whether one in fact succumbs to that risk. (The legal issue is whether an individual who is exposed to a risk is thereby harmed, and can receive compensation for the exposure.) General causal claims, such “smoking causes lung cancer” relate repeatable event types or properties. Some authors have put forward probabilistic theories of singular causation, others have advanced probabilistic theories of general causation. The relationship between singular and general causation is discussed in Section 6.3 below; as we shall see, there seems to be some reason to think that probabilistic theories of causation are better suited to analyzing general causation. The causal relata -- the entities that stand in causal relations -- are variously thought to be facts, events, properties, and so on. I will not try to adjudicate between these different approaches, but will use the generic term “factor.” Note, however, that probabilistic theories of causation do require that causal relata be broadly “propositional” in character: they are the sorts of things that can be conjoined and negated.
Suggested Readings: Mill (1843) contains the classic discussion of “the cause” and “a cause.” Bennett (1988) is an excellent discussion of facts and events.
3. Main Developments
3.1 The Central Idea
The central idea that causes raise the probability of their effects can be expressed formally using the apparatus of conditional probability. Let A, B, C, … represent factors that potentially stand in causal relations. Let P be a probability function, satisfying the normal rules of the probability calculus, such that P(A) represents the empirical probability that factor A occurs or is instantiated (and likewise for the other factors). The issue of how empirical probability is to be interpreted will not be addressed here. Using standard notation, we let P(B | A) represent the conditional probability of B, given A. Formally, conditional probability is standardly defined as a certain ratio of probabilities:
P(B | A) = P(A & B)/P(A).
As an illustration, suppose that we toss a fair die. Let A represent the die's landing with an even number (2, 4 or 6) showing on the topmost face. Then P(A) is one-half. Let B represent the die's landing with a prime number (2, 3 or 5) showing on the topmost face (on that same roll). Then P(B) is also one-half. Now the conditional probability P(B | A) is one-third. It is the probability that the number on the die is both even and prime, i.e., that the number is 2, divided by the probability that the number is even. The numerator is one-sixth, and the denominator is one-half; hence that conditional probability is one-third. The concept of conditional probability does not have any notion of temporal or causal order built into it. Suppose, for example, that the die is rolled twice. It makes sense to ask about the probability that the first roll is a prime number, given that the first roll is even; the probability that the second roll is a prime number, given that the first roll is even; and the probability that the first roll is a prime number, given that the second roll is even.
If P(A) is 0, then the ratio in the definition of conditional probability is undefined. There are, however, other technical developments that will allow us to define P(B | A) when P(A) is 0. The simplest is simply to take conditional probability as a primitive, and to define unconditional probability as probability conditional on a tautology.
One natural way of understanding the idea that A raises the probability of B is that P(B | A) > P(B | not-A). Thus a first attempt at a probabilistic theory of causation would be:
PR: A causes B if and only if P(B | A) > P(B | not-A).
This formulation is labeled PR for “Probability-Raising.” When P(A) is strictly between 0 and 1, the inequality in PR turns out to be equivalent to P(B | A) > P(A) and also to P(A & B) > P(A)P(B). When this last relation holds, A and B are said to be positively correlated. If the inequality is reversed, they are negatively correlated. If A and B are either positively or negatively correlated, they are said to be probabilistically dependent. If equality holds, then A and B are probabilistically independent or uncorrelated.
PR addresses the problems of imperfect regularities and indeterminism, discussed above. But it does not address the other two problems discussed in section 1 above. First, probability-raising is symmetric: if P(B | A) > P(B | not-A), then P(A | B) > P(A | not-B). The causal relation, however, is typically asymmetric.
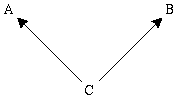
Figure 2
Second, PR has trouble with spurious correlations. If A and B are both caused by some third factor, C, then it may be that P(B | A) > P(B | not-A) even though A does not cause B. This situation is shown schematically in Figure 2. For example, let A be an individual's having yellow-stained fingers, and B that individual's having lung cancer. Then we would expect that P(B | A) > P(B | not-A). The reason that those with yellow-stained fingers are more likely to suffer from lung cancer is that smoking tends to produce both effects. Because individuals with yellow-stained fingers are more likely to be smokers, they are also more likely to suffer from lung cancer. Intuitively, the way to address this problem is to require that causes raise the probabilities of their effects ceteris paribus. The history of probabilistic causation is to a large extent a history of attempts to resolve these two central problems.
Suggested Readings: For a primer on basic probability theory, see the entry for “probability calculus: interpretations of.” This entry also contains a discussion of the intperpretation of probability claims.
3.2 Spurious Correlations
Hans Reichenbach introduced the terminology of “screening off” to apply to a particular type of probabilistic relationship. If P(B | A & C) = P(B | C), then C is said to screen A off from B. (When P(A & C) > 0, this equality is equivalent to P(A & B | C) = P(A | C)P(B | C).) Intuitively, C renders A probabilistically irrelevant to B. With this notion in hand, we can attempt to avoid the problem of spurious correlations by adding a ‘no screening off’ condition to the basic probability-raising condition:
NSO: Factor A occurring at time t, is a cause of the later factor B if and only if:
- P(B | A) > P(B | not-A)
- There is no factor C, occurring earlier than or simultaneously with A, that screens A off from B.
We will call this the NSO, or ‘No Screening Off’ formulation. Suppose, as in our example above, that smoking (C) causes both yellow-stained fingers (A) and lung cancer (B). Then smoking will screen yellow-stained fingers off from lung cancer: given that an individual smokes, his yellow-stained fingers have no impact upon his probability of developing lung cancer.
The second condition of NSO does not suffice to resolve the problem of spurious correlations, however. This condition was added to eliminate cases where spurious correlations give rise to factors that raise the probability of other factors without causing them. Spurious correlations can also give rise to cases where a cause does not raise the probability of its effect. So genuine causes need not satisfy the first condition of NSO. Suppose, for example, that smoking is highly correlated with exercise: those who smoke are much more likely to exercise as well. Smoking is a cause of heart disease, but suppose that exercise is an even stronger preventative of heart disease. Then it may be that smokers are, over all, less likely to suffer from heart disease than non-smokers. That is, letting A represent smoking, C exercise, and B heart disease, P(B | A) < P(B | not-A). Note, however, that if we conditionalize on whether one exercises or not, this inequality is reversed: P(B | A & C) > P(B | not-A & C), and P(B | A & not-C) > P(B | not-A & not-C). Such reversals of probabilistic inequalities are instances of “Simpson's Paradox.”
The next step is to replace conditions 1 and 2 with the requirement that causes must raise the probability of their effects in test situations:
TS: A causes B if P(B | A & T) > P(B | not-A & T) for every test situation T.
A test situation is a conjunction of factors. When such a conjunction of factors is conditioned on, those factors are said to be “held fixed.” To specify what the test situations will be, then, we must specify what factors are to be held fixed. In the previous example, we saw that the true causal relevance of smoking for lung cancer was revealed when we held exercise fixed, either positively (conditioning on C) or negatively (conditioning on not-C). This suggests that in evaluating the causal relevance of A for B, we need to hold fixed other causes of B, either positively or negatively. This suggestion is not entirely correct, however. Let A and B be smoking and lung cancer, respectively. Suppose C is a causal intermediary, say the presence of tar in the lungs. If A causes B exclusively via C, then C will screen A off from B: given the presence (absence) of carcinogens in the lungs, the probability of lung cancer is not affected by whether those carcinogens got there by smoking (are absent despite smoking). Thus we will not want to hold fixed any causes of B that are themselves caused by A. Let us call the set of all factors that are causes of B, but are not caused by A, the set of independent causes of B. A test situation for A and B will then be a maximal conjunction, each of whose conjuncts is either an independent cause of B, or the negation of an independent cause of B.
Note that the specification of factors that need to be held fixed appeals to causal relations. This appears to rob the theory of its status as a reductive analysis of causation. We will see in Section 6.4 below, however, that the issue is substantially more complex than that. In any event, even if there is no reduction of causation to probability, a theory detailing the systematic connections between causation and probability would be of great philosophical interest.
The move from the basic idea of PR to the complex formulation of TS is rather like the move from Hume's original regularity theory to Mackie's theory of inus conditions. In both cases, the move substantially complicates the epistemology of causation. In order to know whether A is a cause of B, we need to know what happens in the presence and absence of B, while holding fixed a complicated conjunction of further factors. The hope that a probabilistic theory of causation would enable us to handle the problem of imperfect regularities without appealing to such constellations of background conditions seems not to have been borne out. Nonetheless, TS does seem to provide us with a theory that is compatible with indeterminism and that can distinguish causation from spurious correlation.
TS can be generalized in at least two important ways. First, we can define a ‘negative cause’ or ‘preventer’ or ‘inhibitor’ as a factor that lowers the probability of its ‘effect’ in all test situations, and a ‘mixed’ or ‘interacting’ cause as one that affects the probability of its ‘effect’ in different ways in different test situations. It should be apparent that when constructing test situations for A and B one should also hold fixed preventers and mixed causes of B that are independent of A. Generalizing even further, one could define causal relationships between variables that are non-binary, such as caloric intake and blood pressure. In evaluating the causal relevance of X for Y, we will need to hold fixed the values of variables that are independently causally relevant to Y. In principle, there are infinitely many ways in which one variable might depend probabilistically on another, even holding fixed some particular test situation. Thus, once the theory is generalized to include non-binary variables, it will not be possible to provide any neat classification of causal factors into causes and preventers.
These two generalizations bring out an important distinction. It is one thing to ask whether A is causally relevant to B in some way; it is another to ask in which way is A causally relevant to B. To say that A causes B is then potentially ambiguous: it might mean that A is causally relevant to B in some way or other; or it could mean that A is causally relevant for B in a particular way, that A promotes B or is a positive factor for the occurrence of B. For example, if A prevents B, then A will count as a cause of B in the first sense, but not in the second. Probabilistic theories of causation can be used to answer both types of question. A is causally relevant to B if A makes some difference for the probability of B in some test situation; whereas A is a positive or promoting cause of B if A raises the probability of B in all test situations.
The problem of spurious correlations also plagues certain versions of decision theory. This can happen when one's choice of action is symptomatic of certain good or bad outcomes, without causing those outcomes. (The best-known example of this sort is Newcomb's Problem.) In cases like this, some versions of decision theory appear to recommend that one act so as to receive good news about events beyond one's control, rather than act so as to bring about desirable events that are within one's control. In response, many decision theorists have advocated versions of causal decision theory. Some versions closely resemble TS.
Suggested Readings: This section more or less follows the main developments in the history of probabilistic theories of causation. Versions of the NSO theory are found in Reichenbach (1956, section 23), and Suppes (1970, chapter 2). Good (1961, 1962) is an early essay on probabilistic causation that is rich in insights, but has had surprisingly little influence on the formulation of later theories. Salmon (1980) is an influential critique of these theories. The first versions of TS were presented in Cartwright (1979) and Skyrms (1980). Eells (1991, chapters 2, 3, and 4) and Hitchcock (1993) carry out the two generalizations of TS described. Skyrms (1980) presents a version of causal decision theory that is very similar to TS. See also the entry for “decision theory: causal.”
3.3 Asymmetry
The second major problem with the basic probability-raising idea is that the relationship of probability-raising is symmetrical. Some proponents of probabilistic theories of causation simply stipulate that causes precede their effects in time. As we saw in Section 1.4 above, this strategy has a number of disadvantages. Note also that while assigning temporal locations to particular events is entirely coherent, it is not so clear what it means to say that one property or event type occurs before another. For example, what does it mean to say that smoking precedes lung cancer? There have been many episodes of smoking, and many of lung cancer, and not all of the former occurred prior to all of the latter. This will be a problem for those who are interested in providing a probabilistic theory of causal relations among properties or event types.
Some defenders of manipulability or agency theories of causation have argued that the necessary asymmetry is provided by our perspective as agents. In assessing whether A is a cause of B, we must ask whether A increases the probability of B, where the relevant conditional probabilities are agent probabilities: the probabilities that B would have were A (or not-A) to be realized by the choice of a free agent. Critics have wondered just what these agent probabilities are.
Other approaches attempt to locate the asymmetry between cause and effect within the structure of the probabilities themselves. One very simple proposal would be to refine the way in which the test situations are constructed. (See the previous section for discussion of test situations.) In evaluating whether A is a cause of B, we should hold fixed not only the independent causes of B, but also the causes of A. Thus if B is a cause of A, rather than vice versa, A will not raise the probability of B in the appropriate test situation, since the presence or absence of B will already be held fixed. This idea is built into the Causal Markov Condition discussed in Section 5 below. Proponents of traditional probabilistic theories of causation have not adopted this strategy. This may be because they feel that this refinement would take the theory too close to vicious circularity: in order to assess whether A causes B, we would need to know already whether B causes A.
A more ambitious approach to the problem of causal asymmetry is due to Hans Reichenbach. Suppose that factors A and B are positively correlated:
1. P(A & B) > P(A)P(B)
It is easy to see that this will hold exactly when A raises the probability of B and vice versa. Suppose, moreover, that there is some factor C having the following properties:
2. P(A & B | C) = P(A | C)P(B | C)
3. P(A & B | not-C) = P(A | not-C)P(B | not-C)
4. P(A | C) > P(A | not-C)
5. P(B | C) > P(B | not-C).
In this case, the trio ACB is said to form a conjunctive fork. Conditions 2 and 3 stipulate that C and not-C screen off A from B. As we have seen, this sometimes occurs when C is a common cause of A and B. Conditions 2 through 5 entail 1, so in some sense C explains the correlation between A and B. If C occurs earlier than A and B, and there is no event satisfying 2 through 5 that occurs later than A and B, then ACB is said to form a conjunctive fork open to the future. Analogously, if there is a future factor satisfying 2 through 5, but no past factor, we have a conjunctive fork open to the past. If a past factor C and a future factor D both satisfy 2 through 5, then ACBD forms a closed fork. Reichenbach's proposal was that the direction from cause to effect is the direction in which open forks predominate. In our world, there are many forks open to the future, few or none open to the past. This proposal is closely related to Reichenbach's Common Cause Principle, which says that if A and B are positively correlated (i.e., they satisfy condition 1), then there exists a C, which is a cause of both A and B, and which screens them off from each other. (By contrast, common effects do not in general screen off their causes.)
It is not clear, however, that this asymmetry between forks open to the past and forks open to the future will be as pervasive as this proposal seems to presuppose. In quantum mechanics, there are correlated effects that are believed to have no common cause that screens them off. Moreover, if ACB forms a conjunctive fork in which C precedes A and B, but C has a deterministic effect D which occurs after A and B, then ACBD will form a closed fork. A further difficulty with this proposal is that since it provides a global ordering of causes and effects, it seems to rule out a priori the possibility that some effects might precede their causes. More complex attempts to derive the direction of causation from probabilities have been offered; the issues here intersect with the problem of reduction, discussed in Section 6.4 below.
Suggested Readings: Suppes (1970, chapter 2) and Eells (1991, chapter 5) define causal asymmetry in terms of temporal asymmetry. Price (1991) defends an account of causal asymmetry in terms of agent probabilities; see also the entry for “causation and manipulation.” Reichenbach's proposal is presented in his (1956, chapter IV). Some difficulties with this proposal are discussed in Arntzenius (1993); see also his entry to this encyclopedia under “physics: Reichenbach's common cause principle.” Papineau (1993) is a good overall discussion of the problem of causal asymmetry within probabilistic theories. Hausman (1998) is a detailed study of the problem of causal asymmetry.
4. Counterfactual Approaches
A leading approach to the study of causation has been to analyze causation in terms of counterfactual conditionals. A counterfactual conditional is a subjunctive conditional sentence, whose antecedent is contrary-to-fact. Here is an example: “if the butterfly ballot had not been used in West Palm Beach, then Albert Gore would be the president on the United States.” In the case of indeterministic outcomes, it may be appropriate to use probabilistic consequents: “if the butterfly ballot had not been used in West Palm Beach, then Albert Gore would have had a .7 chance of being elected president.” A probabilistic counterfactual theory of causation (PC) aims to analyze causation in terms of these probabilistic counterfactuals. The event B is said to causally depend upon the distinct event A just in case both occur and the probability that B would occur, at the time of As occurrence, was much higher than it would have been at the corresponding time if A had not occurred. This counterfactual is to be understood in terms of possible worlds: it is true if, in the nearest possible world(s) where A does not occur, the probability of B is much lower than it was in the actual world. On this account, the relevant notion of `probability-raising' is not understood in terms of conditional probabilities, but in terms of unconditional probabilities in different possible worlds. The test situation is not some specified conjunction of factors, but the sum total of all that remains unchanged in moving to the nearest possible world(s) where A does not occur. Note that PC is intended specifically as a theory of singular causation between particular events, and not as a theory of general causation.
Causal dependence, as defined in the previous paragraph, is sufficient, but not necessary, for causation. Causation is defined to be the ancestral of causal dependence; that is, A causes B just in case there is a sequence of events C1, C2, …, Cn, such that C1 causally depends upon A, C2 causally depends upon C1, …, B causally depends upon Cn. This modification guarantees that causation will be transitive: if A causes C, and C causes B, then A causes B. This modification is also useful in addressing certain problems discussed in Section 6.2 below.
Proponents of counterfactual theories of causation attempt to derive the asymmetry of causation from a corresponding asymmetry in the truth values of counterfactuals. For instance, it may be true that if Mary had not smoked, she would have been less likely to develop lung cancer, but we would not normally agree that if Mary had not developed lung cancer, she would have been less likely to smoke. Ordinary counterfactuals do not ‘backtrack’ from effects to causes. This proscription against backtracking also solves the problem of spurious correlations: we would not say that if the column of mecury had not risen, then the drop in atmospheric pressure would have been less likely, and so the storm would have been less likely as well.
One important question is whether the counterfactuals that appear in the analysis of causation can be characterized without reference to causation. In order to do this, one would have to say what makes some worlds closer than others without making reference to any causal notions. Despite some interesting attempts, it is not clear whether this can be done. If not, then it will not be possible to provide a reductive PC analysis of causation, although it may still be possible to articulate interesting interconnections between causation, probability and counterfactuals.
The Philosopher Igal Kvart has been a persistent critic of the claim that it is possible to analyze counterfactuals without using causation. He has developed a probabilistic theory of singular causation that does not use counterfactuals. Nonetheless, his theory has a number of features in common with counterfactual theories: it is an attempt to analyze singular causation among events; it elaborates on the basic probability-raising idea in an attempt to avoid some of the problems raised in Section 6.2 below; and it aspires to be a reductive analysis of causation, making no reference to causal relations in the analysans.
Suggested Readings: Lewis (1986a) is the locus classicus for PC. Lewis (1986b) is an attempt to explicate the notion of proximity among possible worlds. Recent attempts to analyze causation in terms of probabilistic counterfactuals have become quite intricate; see for example Noordhof (1999). For further discussion of counterfactual theories of causation, see the entry under “causation, counterfactual theories.” For Kvart's theory, see for example Kvart (1997).
5. Causal Modeling and Probabilistic Causation
5.1 Causal Modeling
‘Causal modeling’ is a new interdisciplinary field devoted to the study of methods of causal inference. This field includes contributions from statistics, artificial intelligence, philosophy, econometrics, epidemiology, and other disciplines. Within this field, the research programs that have attracted the greatest philosophical interest are those of the computer scientist Judea Pearl and his collaborators, and of the philosophers Peter Spirtes, Clark Glymour, and Richard Scheines (SGS). Not coincidentally, these two programs are the most ambitious in their claims to have developed algorithms for making causal inferences on the basis of statistical data. These claims have generated a great deal of controversy, often quite heated. Specfically, there seems to be a great deal of resistance to the idea that automated procedures can take the place of subject-specific background knowledge and good experimental design, the things that causal inference has always depended on. To some extent, this debate is one over emphasis and advertising. Both Pearl and SGS state explicit assumptions that must be made before their procedures can yield results. Critics charge, first, that these assumptions are buried in fine print while the automated procedures are advertised in bold; and second, that the required assumptions are rarely satisfied in realistic cases, rendering the new procedures virtually useless. These charges are orthogonal to the issue of whether the techniques perform as advertised when the necessary assumptions do hold.
Our concern here will not be with the efficacy of these methods of causal inference, but rather with their philosophical underpinnings. We will here follow the developments of SGS, as these bear a stronger resemblance to the probabilistic theories of causation described in Section 3 above. (Pearl's approach, at least in its more recent development, bears a stronger connection to counterfactual approaches.)
Suggested Readings: Pearl (2000) and Spirtes, Glymour and Scheines (2000) are the most detailed presentations of the two research programs discussed. Both works are quite technical, although the epilogue of Pearl (2000) provides a very readable historical introduction to Pearl's work. Pearl (1999) also contains a reasonably accessible introduction to some of Pearl's more recent developments. Scheines (1997) is a non-technical introduction to some of the ideas in SGS (2000). McKim and Turner (1997) is a collection of papers on causal modeling, including some important critiques of SGS.
5.2 The Markov and Minimality Conditions
We can present here only a very rudimentary overview of the SGS framework. We begin with a set V of variables. The set may, for instance, include variables representing the education-level, income, parental income, et al, of individuals in a population. These variables are different from the factors that normally figure in probabilistic theories of causation. Factors stand to variables as determinates to determinables. "Income" is a variable; "having an income of $40,000 per year" is a factor. Given a set of variables, we may define two different mathematical structures over this set. First, a directed graph G on V is a set of directed edges, or ‘arrows’, having the variables in V as their vertices. The variable X is a ‘parent’ of Y just in case there is an arrow from X to Y. X is an ‘ancestor’ of Y (equivalently, Y is a ‘descendant’ of X) just in case there is a ‘directed path’ from X to Y consisting of arrows linking intermediate variables. The directed graph is acyclic if there are no loops, that is, if no variable is an ancestor of itself. In addition to a directed acyclic graph over V, we also have a probability distribution P over the values of variables in V.
The directed acyclic graph G over V may be related to the probability distribution in a number of ways. One important condition that the two might satisfy is the so-called Markov Condition:
MC: For every X in V, and every set Y of variables in V \ DE(X), P(X | PA(X) & Y) = P(X | PA(X)); where DE(X) is the set of descendants of X, and PA(X) is the set of parents of X.
The notation needs a little clarification. Consider, for example, the first term in the equality. Since X is a variable, it doesn't really make sense to talk about the probability of X, or of the conditional probability of X. It makes sense to talk about the probability of having an income of $40,000 per year (at least if we are talking about members of some well-defined population), but it makes no sense to talk about the probability of "income". (Note that we do not mean here the probability of having some income or other. That probability is one, assuming we allow zero to count as a value of income.) This formulation of MC uses a common notational convention. Whenever a variable, or set of variables appears, there is a tacit universal quantifier ranging over values of the variable(s) in question. Thus MC should be understood as asserting an equality between two conditional probabilities that holds for all values of the variable X, and for all values of the variables in Y and PA(X). In words, the Markov condition says that the parents of X screen X off from all other variables, except for the descendents of X. Given the values of the variables that are parents of X, the values of the variables in Y (which includes no descendents of X), make no further difference to the probability that X will take on any given value.
As stated, the Markov Condition describes a purely formal relation between abstract entities. Suppose, however, that we give the graph and probability distribution empirical interpretations. The graph will represent the causal relationships among the variables in a population, and the probability distribution will represent the empirical probability that an individual in the population will possess certain values of the relevant variables. When the directed graph is given a causal interpretation, it is called a causal graph. We will return shortly to the question of what, exactly, the arrows in a causal graph represent.
The Causal Markov Condition (CMC) asserts that MC holds of a population when the directed graph and probability distribution are given these interpretations. CMC does not hold in general, but only when certain further conditions are satisfied. For instance, V must include all common causes of variables that are included in V. Suppose, for example, that V = {X, Y}, that neither variable is a cause of the other, and that Z is a common cause of X and Y (the true causal structure is shown in Figure 3 below). The correct causal graph on V will include no arrows, since neither X nor Y cause the other. But X and Y will be probabilistically correlated, because of the underlying common cause. This is a violation of CMC. Since the correct causal graph on {X, Y} has no arrows, X has no parents or descendents; thus CMC entails that P(X | Y) = P(X). This equality is false, since X and Y are in fact correlated. CMC can also fail for certain types of heterogeneous populations composed of subpopulations with differenct causal structures. And CMC will fail for certain quantum systems. One area of controversy concerns the extent to which actual populations satisfy CMC with respect to the sorts of variable sets that are typically employed in empirical investigations. For purposes of further discussion, we will assume that CMC holds.
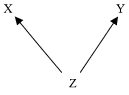
Figure 3
The Causal Markov Condition is a generalization of Reichenbach's Common Cause Principle, discussed in Section 3.3 above. Here are a few illustrations of how it works.
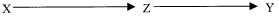
Figure 4
In Figures 3 and 4, CMC entails that the values of Z screen off the values of X from the values of Y.
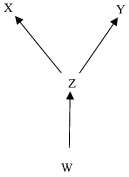
Figure 5
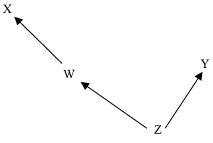
Figure 6
In Figures 5 and 6, CMC again entails that the values of Z screen off the values of X from the values of Y. However, CMC does not entail that the values of W screen off the values of X from the values of Y in Figure 5, whereas it does entail that the values of W screen off the values of X from the values of Y in Figure 6. This shows that being a common cause of X and Y is neither necessary nor sufficient for screening off the values of those variables.
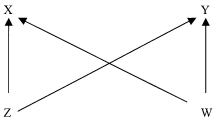
Figure 7
In Figure 7, both Z and W are common causes of X and Y, yet CMC does not entail that either one of them, by itself, suffices to screen off the values of X and Y. This seems reasonable: if we hold fixed the value of Z, we should expect X and Y to remain correlated due to the action of W. CMC does entail that Z and W jointly screen off X and Y; that is, when we condition on the values of Z and W, there will be no residual correlation between X and Y.
A second important relation between a directed graph and probability distribution is the Minimality Condition. Suppose that the directed graph G on variable set V satisfies the Markov condition with respect to the probability distribution P. The Minimality Condition asserts that no sub-graph of G over V also satisfies the Markov Condition with respect to P. The Causal Minimality Condition asserts that the Minimality Condition holds when G and P are given their empirical interpretations. As an illustration, consider the variable set {X, Y}, let there be an arrow from X to Y, and suppose that X and Y are probabilistically independent of each other in P. This graph would satisfy the Markov Condition with respect to P: none of the independence relations mandated by MC are absent (in fact, MC mandates no independence relations). But this graph would violate the Minimality Condition with respect to P, since the subgraph that omits the arrow from X to Y would also satisfy the Markov Condition.
Suggested Readings: Spirtes, Glymour and Scheines (2000) and Scheines (1997). Hausman and Woodward (1999) provide a detailed discussion of the Causal Markov Condition.
5.3 What the Arrows Mean
We are now in a better position to say something about what the arrows in a causal graph mean. First consider a simple graph with two variables X and Y and an arrow from X to Y. The Minimality Condition requires that the two variables not be probabilistically independent. This means that there must be values x and x′ of X and y of Y, such that
P(Y = y | X = x) ≠ P(Y = y | X = x′).
This says nothing about how X bears on Y. Suppose for example, that we have a three variable model, including the variables smoking, exercise, and heart disease. The causal graph would (presumably) include an arrow from smoking to heart disease, and an arrow from exercise to heart disease. Nothing in the graph indicates that increased levels of smoking increase the risk and severity of heart disease, whereas increased levels of exercise (up to a point, anyway) decrease the risk and severity of heart disease. Thus an arrows in a causal graph indicates only that one variable is causally relevant to another, and says nothing about the way in which it is relevant (whether it is a promoting, inhibiting, or interacting cause, or stands in some more complex relation).
Figure 8
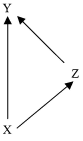
Consider Figure 8. Note that it differs from Figure 4 in that there is an additional arrow running directly fron X to Y. What does this arrow from X to Y indicate? It does not merely indicate that X is causally relevant to Y; in Figure 4, it is natural to expect that X will relevant to Y via its effect on Z. Applying the Causal Markov and Minimality Conditions, the arrow from X to Y indicates that Y is probabilistically dependent on X, even when we hold fixed the value of Z. That is, X makes a probabilistic difference for Y, over and above the difference it makes in virtue of its effect on Z. Figure 8 thus indicates that X has an effect on Y via two different routes: one route that runs through the variable Z and the other route which is direct, i.e., unmediated by any other variable in V. As an illustration, consider a well-known example due to Germund Hesslow. Consumption of birth control pills (X) is a risk factor for thrombosis (Y). On the other hand, birth control pills are an effective preventer of pregnancy (Z), which is in turn a powerful risk factor for thrombosis. The use of birth control pills may thus affect one's chances of suffering from thrombosis in two different ways, one 'direct', and one via the effect of pills on one's chances of becoming pregnant. Whether birth control pills raise or lower the probability of thrombosis overall will depend upon the relative strengths of these two routes. The probabilistic theories of causation described in Section 3 above are suited to analyze the total or net effect of one factor or variable on other, whereas the causal modeling techniques discussed in this section are primarily geared toward decomposing a causal system into individual routes of causal influence.
Suggested Readings: The birth control pill example was originally presented in Hesslow (1976). Hitchcock (2001a) discusses the distinction between total or net effect, and causal influence along individual routes.
5.4 The Faithfulness Condition
One final condition that SGS make extensive use of is the Faithfulness Condition. (I will dispense with the distinction between the causal and non-causal versions.) The Faithfulness Condition says that all of the (conditional and unconditional) probabilistic independencies that exist among the variables in V are required by the Causal Markov Condition. For example, suppose that V = {X, Y, Z}. Suppose also that X and Y are unconditionally independent of one another, but dependent, conditional upon Z. (The other two variables pairs are dependent, both conditionally and unconditionally.) The graph shown in Figure 8 does not satisfy the faithfulness condition with respect to this distribution (colloquially, the graph is not faithful to the distribution). CMC, when applied to the graph of Figure 8, does not imply the independence of X and Y. By contrast, the graph shown in Figure 9 is faithful to the described distribution. Note that Figure 8 does satisfy the Minimality Condition; no subgraph satisfies CMC with respect to the described distribution. (The graph in Figure 9 is not a subgraph of the graph in Figure 8.)
Figure 9
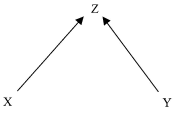
The Faithfulness Condition implies that the causal influences of one variable on another along multiple causal routes does not ‘cancel’. For example, suppose that Figure 8 correctly represents the underlying causal structure. Then the Faithfulness Condition implies that X and Y cannot be unconditionally independent of one another in the empirical distribution. In Hesslow's example, this means that the tendency of birth control pills to cause thrombosis along the direct route cannot be exactly canceled by the tendency of birth control pills to prevent thrombosis by preventing pregnancy. This ‘no canceling’ condition seems implausible as a metaphysical or conceptual constraint upon the connection between causation and probabilities. Why can't competing causal paths cancel one another out? Indeed, Newtonian physics provides us with an example: the downward force on my body due to gravity triggers an equal and opposite upward force on my body from the floor. My body responds as if neither force were acting upon it. The Faithfulness Condition seems rather to be a methodological principle. Given a distribution on {X, Y, Z} in which X and Y are independent, we should infer that the causal structure is that depicted in Figure 9, rather than Figure 8. This is not because Figure 8 is conclusively ruled out by the distribution, but rather because it is gratuitously complex: it postulates causal connections that are not necessary to explain the underlying pattern of probabilistic dependencies. The Faithfulness Condition is thus a formal version of Ockham's razor.
SGS use the Causal Markov, Minimality, and Faithfulness Conditions to prove a variety of statistical indistinguishability theorems. These theorems tell us when two distinct causal structures can or cannot be distinguished on the basis of the probability distributions to which they give rise. We will return to this issue in Section 6.4 below.
Suggested Readings: Spirtes, Glymour and Scheines (2000) and Scheines (1997).
6. Further Issues and Problems
6.1 Contextual-unanimity
According to TS, a cause must raise the probability of its effect in every test situation. This has been called the requirement of contextual-unanimity. This requirement is vulnerable to the following sort of counterexample. Suppose that there is a gene that has the following effect: those that possess the gene have their chances of contracting lung cancer lowered when they smoke. This gene is very rare, let us imagine (indeed, it need not exist at all in the human population, so long as humans have some non-zero probability of possessing this gene, perhaps as a result of a very improbable mutation). In this scenario, there would be test situations (those that hold fixed the presence of the gene) in which smoking lowers the probability of lung cancer: thus smoking would not be a cause of lung cancer according to the context-unanimity requirement. Nonetheless, it seems unlikely that the discovery of such a gene (or of the mere possibility of its occurrence) would lead us to abandon the claim that smoking causes lung cancer.
This line of objection is surely right about our ordinary use of causal language. It is nonetheless open to the defender of context-unanimity to respond that she is interested in supplying a precise concept to replace the vague notion of causation that corresponds to our everyday usage. In a population consisting of individuals lacking the gene, smoking causes lung cancer. In a population consisting entirely of individuals who possess the gene, smoking prevents lung cancer.
Note that this dispute only arises in the context of a heterogeneous population. Restricting ourselves to one particular test situation, both parties can agree that smoking causes lung cancer in that test population just in case it increases the probability of lung cancer in that test situation.
One's position in this debate will depend, in part, on how one wants to use general causal claims such as “smoking causes lung cancer”. If one conceives of them as causal laws, then the contextual-unanimity requirement may seem attractive. If “smoking causes lung cancer” is a kind of law, then its truth should not be contingent upon the scarcity of the gene that reverses the effects of smoking. By contrast, one may understand the causal claim in a more practical way, by treating it as a kind of policy-guiding principle. Since the gene in question is very rare, it would still be rational for public health organizations to promote policies that would reduce the incidence of smoking.
Suggested Readings: Dupré; (1984) presents this challenge to the context-unanimity requirement, and offers an alternative. Eells (1991, chapters 1 and 2), defends context-unanimity using the idea that causal claims are made relative to a population. Hitchock (2001b) contains further discussion and develops the idea of treating general causal claims as policy-guiding principles.
6.2 Potential Counterexamples
Given the basic probability-raising idea, one would expect putative counterexamples to probabilistic theories of causation to be of two basic types: cases where causes fail to raise the probabilities of their effects, and cases where non-causes raise the probabilities of non-effects. The discussion in the literature has focused almost entirely on the first sort of example. Consider the following example, due to Deborah Rosen. A golfer badly slices a golf ball, which heads toward the rough, but then bounces off a tree and into the cup for a hole in one. The golfer's slice lowered the probability that the ball would wind up in the cup, yet nonetheless caused this result. One way of avoiding this problem is to attend to the probabilities that are being compared. If we label the slice A, not-A is a disjunction of several alternatives. One such alternative is a clean shot -- compared to this alternative, the slice lowered the probability of a hole-in-one. Another alternative is no shot at all, relative to which the slice increases the probability of a hole-in-one. By making the latter sort of comparison, we can recover our original intuitions about the example.
A different sort of counterexample involves causal preemption. Suppose that an assassin puts a weak poison in the king's drink, resulting in a 30% chance of death. The king drinks the poison and dies. If the assassin had not poisoned the drink, her associate would have spiked the drink with an even deadlier elixir (70% chance of death). In the example, the assassin caused the king to die by poisoning his drink, even though she lowered his chance of death (from 70% to 30%). Here the cause lowered the probability of death, because it preempted an even stronger cause.
One approach to this problem, built into the counterfactual approach described in Section 4 above, is to invoke the principle of the transitivity of causation. The assassin's action increased the probability of, and hence caused, the presence of weak poison in the king's drink. The presence of weak poison in the king's drink raised the probability of, and hence caused, the king's death. (By this time, it is already determined that the associate will not poison the drink.) By transitivity, the assassin's action caused the king's death. The claim that causation is transitive is highly controversial, however, and is subject to many persuasive counterexamples.
Another approach would be to invoke a distinction introduced in Section 5.3 above. The assassin's action affects the king's chances of death in two distinct ways: first, it introduces the weak poison into the king's drink; second, it prevents the introduction of a stronger poison. The net effect is to reduce the king's chance of death. Nonetheless, we can isolate the first of these effects (which would be indicated by an arrow in a causal graph). We do this by holding fixed the inaction of the associate: given that the associate did not in fact poison the drink, the assassin's action increased the king's chance of death (from near zero to .3). We count the assassin's action as a cause of death because it increased the chance of death along one of the routes connecting the two events.
For a counterexample of the second type, suppose that two gunmen shoot at a target. Each has a certain probability of hitting, and a certain probability of missing. Assume that none of the probabilities are one or zero. As a matter of fact, the first gunman hits, and the second gunman misses. Nonetheless, the second gunman did fire, and by firing, increased the probability that the target would be hit, which it was. While it is obviously wrong to say that the second gunman's shot caused the target to be hit, it would seem that a probabilistic theory of causation is committed to this consequence. A natural approach to this problem would be to try to combine the probabilistic theory of causation with a requirement of spatiotemporal connection between cause and effect, although it is not at all clear how this hybrid theory would work.
Suggested Readings: The example of the golf ball, due to Deborah Rosen, is first presented in Suppes (1970) Salmon (1980) presents several examples of probability-lowering causes. Hitchcock (1995) presents a response. Lewis (1986a) discusses cases of preemption, see also the entry for “causation: counterfactual theories.” Hithcock (2001a) presents the solution in terms of decomposition into component causal routes. Woodward (1990) describes the structure that is instantiated in the example of the two gunmen. Humphreys (1989, section 14) responds. Menzies (1989, 1996) discusses examples involving causal pre-emption where non-causes raise the probabilities of non-effects. Hitchcock (2002) provides a general discussion of these counterexamples. For a discussion of attempts to analyze cause and effect in terms of contiguous processes, see the entry for “causation: causal processes.”
6.3 Singular and General Causation
We noted in section 2 above that we make at least two different kinds of causal claim, singular and general. With this distinction in mind, we may note that the counterexamples mentioned in the previous section are all formulated in terms of singular causation. So one possible reaction to the counterexamples of the previous section would be to maintain that a probabilistic theory of causation is appropriate for general causation only, and that singular causation requires a distinct philosophical theory. One consequence of this move is that there are (at least) two distinct species of causal relation, each requiring its own philosophical account -- not an altogether happy predicament.
Suggested Readings: The need for distinct theories of singular and general causation is defended in Good (1961, 1962), Sober (1985), and Eells (1991, introduction and chapter 6). Eells (1991, chapter 6) offers a distinct probabilistic theory of singular causation in terms of the temporal evolution of probabilities. Carroll (1991) and Hitchcock (1995) offer two quite different lines of response. Hitchcock (2001b) argues that there are really (at least) two different distinctions at work here.
6.4 Reduction and Circularity
Returning to the theories outlined in section 3, recall that theory NSO was an attempt at a reductive analysis of causation in terms of probabilities (and perhaps also temporal order). By contrast, TS defines causal relations in terms of probabilities conditional upon specifications of test conditions, which are themselves characterized in causal terms. Thus it appears that the latter theories cannot be analyses of causation, since causation appears in the analysans. Given that TS contains much needed improvements over NSO, it looks as though there can be no reduction of causation to probabilities. This may be giving up too soon, however. In order to determine whether a probabilistic reduction of causation is possible, the central issue is not whether the word ‘cause’ appears in both the analysandum and the analysans; rather, the key question should be whether, given an assignment of probabilities to a set of factors, there is a unique set of causal relations among those factors compatible with the probability assignment and the theory in question.
The most important work along these lines has been carried out by Spirtes, Glymour and Scheines. Rather than report on the details of their results, we present here a more generalized discussion. Suppose that a set of factors, and a system of causal relations among those factors is given: call this the causal structure CS. Let T be a theory connecting causal relations among factors with probabilistic relations among factors. Then the causal structure CS will be probabilistically distinguishable relative to T, if for every assignment of probabilities to the factors in CS that is compatible with CS and T, CS is the unique causal structure compatible with Tand those probabilities. (One could formulate a weaker sense of distinguishability by requiring that only some assignment of probabilities uniquely determines CS). Intuitively, T allows you to infer that the causal structure is in fact CS given the probability relations between factors. Given a probabilistic theory of causation T, it is possible to imagine many different properties it might have. Here are some possibilities:
- All causal structures are probabilistically distinguishable relative to T
- All causal structures having some interesting property are probabilistically distinguishable relative to T
- Any causal structure can be embedded in a causal structure that is probabilistically distinguishable relative to T
- The actual causal structure of the world (assuming there is such a thing) is probabilistically distinguishable relative to T.
It is not obvious which type of distinguishability properties a theory must have in order to constitute a reduction of causation to probabilities. The question of whether causation can be reduced to probabilities is thus less univocal than it might appear.
Suggested Readings: The most detailed treatment of probabilistic distinguishability is given in Spirtes, Glymour and Scheines (2000); see especially chapter 4. Spirtes, Glymour and Scheines prove (theorem 4.6) a result along the lines of 3 for a theory that they propose. This work is very technical. An accessible presentation is contained in Papineau (1993), which defends a position along the lines of 4.
Bibliography
- Arntzenius, Frank. (1993) “The Common Cause Principle,” in Hull, Forbes, and Okruhlik (1993), pp. 227 - 237.
- Bennett, Jonathan. (1988) Events and Their Names. Indianapolis and Cambridge: Hackett.
- Carroll, John. (1991) “Property-level Causation?” Philosophical Studies 63: 245-70.
- Cartwright, Nancy. (1979) ?usal Laws and Effective Strategies,” Noûs 13: 419-437.
- Dupré, John. (1984) “Probabilistic Causality Emancipated,” in Peter French, Theodore Uehling, Jr., and Howard Wettstein, eds., (1984) Midwest Studies in Philosophy IX (Minneapolis: University of Minnesota Press), pp. 169 - 175.
- Earman, John. (1986) A Primer on Determinism. Dordrecht: Reidel.
- Eells, Ellery. (1991) Probabilistic Causality. Cambridge, U.K.: Cambridge University Press.
- Good, I. J. (1961) “A Causal Calculus I,” British Journal for the Philosophy of Science 11: 305-18.
- -----. (1962) “A Causal Calculus II,” British Journal for the Philosophy of Science 12: 43-51.
- Hausman, Daniel. (1998) Causal Asymmetries. Cambridge: Cambridge University Press.
- Hausman, Daniel, and Woodward, James. (1999) “Independence, Invariance, and the Causal Markov Condition,” British Journal for the Philosophy of Science 50: 1 - 63.
- Hesslow, Germund. (1976) “Discussion: Two Notes on the Probabilistic Approach to Causality,” Philosophy of Science 43: 290 - 292.
- Hitchcock, Christopher. (1993) “A Generalized Probabilistic Theory of Causal Relevance,” Synthese 97: 335-364.
- -----. (1995) “The Mishap at Reichenbach Fall: Singular vs. General Causation,” Philosophical Studies 78: 257 - 291.
- ----. (2001a) “A Tale of Two Effects,” Philosophical Review 110: 361 - 396.
- -----. (2001b) “Causal Generalizations and Good Advice,” Monist 84: 218 - 241.
- -----. (2002) “Do All and Only Causes Raise the Probabilities of Effects?” in John Collins, Ned Hall, and L.A. Paul (eds.), Causation and Counterfactuals (Cambridge MA: MIT Press, 2002).
- Hull, David, Mickey Forbes, and Kathleen Okruhlik, eds. (1993) PSA 1992, Volume Two. East Lansing: Philosophy of Science Association.
- Hume, David. (1748) An Enquiry Concerning Human Understanding.
- Humphreys, Paul. (1989) The Chances of Explanation: Causal Explanations in the Social, Medical, and Physical Sciences, Princeton: Princeton University Press.
- Kvart, Igal. (1997) “Cause and Some Positive Causal Impact,” Noûs 11: 401 - 432.
- Lewis, David. (1986a) “Causation” and “Postscripts to ‘Causation’,” in Lewis (1986c), pp. 172-213.
- -----. (1986b) “Counterfactual Dependence and Time's Arrow” and “Postscripts to ‘Counterfactual Dependence and Time's Arrow’,” in Lewis (1986c), pp. 32 - 66.
- -----. (1986c) Philosophical Papers, Volume II. Oxford: Oxford University Press.
- Mackie, John. (1974) The Cement of the Universe. Oxford: Clarendon Press.
- McKim, Vaughn, and Stephen Turner, eds. (1997) Causality in Crisis? Notre Dame: University of Notre Dame Press.
- Menzies, Peter. (1989) “Probabilistic Causation and Causal Processes: A Critique of Lewis,” Philosophy of Science 56: 642-63.
- Menzies, Peter. (1996) “Probabilistic Causation and the Pre-emptionProblem”, Mind 105: 85-117.
- Mill, John Stuart. (1843) A System of Logic, Ratiocinative and Inductive. London: Parker and Son.
- Noordhof, Paul. (1999) “Probabilistic Causation, Preemption and Counterfactuals,” Mind 108: 95 - 125.
- Papineau, David. (1993) “Can We Reduce Causal Direction to Probabilities?” in Hull, Forbes and Okruhlik (1993), pp. 238-252.
- Pearl, Judea. (1999) “Reasoning with Cause and Effect,” in Proceedings of the International Joint Conference on Artificial Intelligence (San Francisco: Morgan Kaufman), pp. 1437 - 1449.
- -----. (2000) Causality: Models, Reasoning, and Inference. Cambridge: Cambridge University Press.
- Price, Huw. (1991) “Agency and Probabalistic Causality”, British Journal for the Philosophy of Science 42: 157 -76.
- Reichenbach, Hans. (1956) The Direction of Time. Berkeley and Los Angeles: University of California Press.
- Salmon, Wesley. (1980) “Probabilistic Causality,” Pacific Philosophical Quarterly 61: 50 - 74.
- Scheines, Richard. (1997) “An Introduction to Causal Inference” in McKim and Turner (1997), pp. 185 - 199.
- Skyrms, Brian. (1980) Causal Necessity. New Haven and London: Yale University Press.
- Sober, Elliott. (1985) “Two Concepts of Cause” in Peter Asquith and Philip Kitcher, eds., PSA 1984, Vol. II (East Lansing: Philosophy of Science Association), pp. 405-424.
- Spirtes, Peter, Clark Glymour, and Richard Scheines. (2000) Causation, Prediction and Search, Second edition. Cambridge, MA: M.I.T. Press.
- Suppes, Patrick. (1970) A Probabilistic Theory of Causality. Amsterdam: North-Holland Publishing Company.
- Woodward, James. (1990) “Supervenience and Singular Causal Claims,” in Dudley Knowles, ed., Explanation and its Limits (Cambridge, U.K: Cambridge University Press), pp. 211 - 246.
Other Internet Resources
[Please contact the author with suggestions.]
Related Entries
causation: and manipulability | causation: backward | causation: causal processes | causation: counterfactual theories of | causation: in the law | causation: the metaphysics of | conditionals: counterfactual | decision theory: causal | determinism: causal | events | Hume, David | physics: Reichenbach's common cause principle | probability, interpretations of | quantum mechanics | quantum theory: the Einstein-Podolsky-Rosen argument in | Simpson's paradox | time