
Computational Linguistics
“Human knowledge is expressed in language. So computational linguistics is very important.” –Mark Steedman, ACL Presidential Address (2007)
Computational linguistics is the scientific and engineering discipline concerned with understanding written and spoken language from a computational perspective, and building artifacts that usefully process and produce language, either in bulk or in a dialogue setting. To the extent that language is a mirror of mind, a computational understanding of language also provides insight into thinking and intelligence. And since language is our most natural and most versatile means of communication, linguistically competent computers would greatly facilitate our interaction with machines and software of all sorts, and put at our fingertips, in ways that truly meet our needs, the vast textual and other resources of the internet.
The following article outlines the goals and methods of computational linguistics (in historical perspective), and then delves in some detail into the essential concepts of linguistic structure and analysis (section 2), interpretation (sections 3–5), and language use (sections 6–7), as well as acquisition of knowledge for language (section 8), statistical and machine learning techniques in natural language processing (section 9), and miscellaneous applications (section 10).
- 1. Introduction: Goals and methods of computational linguistics
- 2. Syntax and parsing
- 3. Semantic representation
- 4. Semantic interpretation
- 5. Making sense of text
- 6. Language generation
- 7. Making sense of, and engaging in, dialogue
- 8. Acquiring knowledge for language
- 9. Statistical NLP
- 10. Applications
- 10.1 Machine translation (again)
- 10.2 Document retrieval and clustering applications
- 10.3 Knowledge extraction and summarization
- 10.4 Sentiment analysis
- 10.5 Chatbots and companionable dialogue agents
- 10.6 Virtual worlds, games, and interactive fiction
- 10.7 Natural language user interfaces
- 10.8 Collaborative problem solvers and intelligent tutors
- 10.9 Language-enabled robots
- Bibliography
- Academic Tools
- Other Internet Resources
- Related Entries
1. Introduction: Goals and methods of computational linguistics
1.1 Goals of computational linguistics
The theoretical goals of computational linguistics include the formulation of grammatical and semantic frameworks for characterizing languages in ways enabling computationally tractable implementations of syntactic and semantic analysis; the discovery of processing techniques and learning principles that exploit both the structural and distributional (statistical) properties of language; and the development of cognitively and neuroscientifically plausible computational models of how language processing and learning might occur in the brain.
The practical goals of the field are broad and varied. Some of the most prominent are: efficient text retrieval on some desired topic; effective machine translation (MT); question answering (QA), ranging from simple factual questions to ones requiring inference and descriptive or discursive answers (perhaps with justifications); text summarization; analysis of texts or spoken language for topic, sentiment, or other psychological attributes; dialogue agents for accomplishing particular tasks (purchases, technical trouble shooting, trip planning, schedule maintenance, medical advising, etc.); and ultimately, creation of computational systems with human-like competency in dialogue, in acquiring language, and in gaining knowledge from text.
1.2 Methods of computational linguistics
The methods employed in theoretical and practical research in computational linguistics have often drawn upon theories and findings in theoretical linguistics, philosophical logic, cognitive science (especially psycholinguistics), and of course computer science. However, early work from the mid-1950s to around 1970 tended to be rather theory-neutral, the primary concern being the development of practical techniques for such applications as MT and simple QA. In MT, central issues were lexical structure and content, the characterization of “sublanguages” for particular domains (for example, weather reports), and the transduction from one language to another (for example, using rather ad hoc graph transformation grammars or transfer grammars). In QA, the concern was with characterizing the question patterns encountered in a specific domain, and the relationship of these question patterns to the forms in which answers might stored, for instance in a relational database.
By the mid-1960s a number of researchers emboldened by the increasing power and availability of general-purpose computers, and inspired by the dream of human-level artificial intelligence, were designing systems aimed at genuine language understanding and dialogue. The techniques and theoretical underpinnings employed varied greatly. An example of a program minimally dependent on linguistic or cognitive theory was Joseph Weizenbaum's ELIZA program, intended to emulate (or perhaps caricature) a Rogerian psychiatrist. ELIZA relied on matching user inputs to stored patterns (brief word sequences interspersed with numbered slots, to be filled from the input), and returned one of a set of output templates associated with the matched input pattern, instantiated with material from the input. While ELIZA and its modern chatbot descendants are often said to rely on mere trickery, it can be argued that human verbal behavior is to some degree reflexive in the manner of ELIZA, i.e., we function in “preprogrammed” or formulaic manner in certain situations, for example, in exchanging greetings, or in responding at a noisy party to comments whose contents, apart from an occasional word, eluded us.
A very different perspective on linguistic processing was proffered in the early years by researchers who took their cue from ideas about associative processes in the brain. For example, M. Ross Quillian (1968) proposed a model of word sense disambiguation based on “spreading activation” in a network of concepts (typically corresponding to senses of nouns) interconnected through relational links (typically corresponding to senses of verbs or prepositions). Variants of this “semantic memory” model were pursued by researchers such as Rumelhart, Lindsay and Norman (1972), and remain as an active research paradigm in computational models of language and cognition. Another psychologically inspired line of work was initiated in the 1960s and pursued for over two decades by Roger Schank and his associates, but in his case the goal was full story understanding and inferential question answering. A central tenet of the work was that the representation of sentential meaning as well as world knowledge centered around a few (e.g., 11) action primitives, and inference was driven by rules associated primarily with these primitives; (a prominent exponent of a similar view was Yorick Wilks). Perhaps the most important aspect of Schank's work was the recognition that language understanding and inference were heavily dependent on a large store of background knowledge, including knowledge of numerous “scripts” (prototypical ways in which familiar kinds of complex events, such as dining at a restaurant, unfold) and plans (prototypical ways in which people attempt to accomplish their goals) (Schank & Abelson 1977).
More purely AI-inspired approaches that also emerged in the 1960s were exemplified in systems such as Sad Sam (Lindsay 1963), Sir (Raphael 1968) and Student (Bobrow 1968). These featured devices such as pattern matching/transduction for analyzing and interpreting restricted subsets of English, knowledge in the form of relational hierarchies and attribute-value lists, and QA methods based on graph search, formal deduction protocols and numerical algebra. An influential idea that emerged slightly later was that knowledge in AI systems should be framed procedurally rather than declaratively—to know something is to be able to perform certain functions (Hewitt 1969). Two quite impressive systems that exemplified such a methodology were shrdlu (Winograd 1972) and Lunar (Woods et al. 1972), which contained sophisticated proceduralized grammars and syntax-to-semantics mapping rules, and were able to function fairly robustly in their “micro-domains” (simulated blocks on a table, and a lunar rock database, respectively). In addition, shrdlu featured significant planning abilities, enabled by the microplanner goal-chaining language (a precursor of Prolog). Difficulties that remained for all of these approaches were extending linguistic coverage and the reliability of parsing and interpretation, and most of all, moving from microdomains, or coverage of a few paragraphs of text, to more varied, broader domains. Much of the difficulty of scaling up was attributed to the “knowledge acquisition bottleneck”—the difficulty of coding or acquiring the myriad facts and rules evidently required for more general understanding. Classic collections containing several articles on the early work mentioned in the last two paragraphs are Marvin Minsky's Semantic Information Processing (1968) and Schank and Colby's Computer Models of Thought and Language (1973).
Since the 1970s, there has been a gradual trend away from purely procedural approaches to ones aimed at encoding the bulk of linguistic and world knowledge in more understandable, modular, re-usable forms, with firmer theoretical foundations. This trend was enabled by the emergence of comprehensive syntactico-semantic frameworks such as Generalized Phrase Structure Grammar (GPSG), Head-driven Phrase Structure Grammar (HPSG), Lexical-Functional Grammar (LFG), Tree-Adjoining Grammar (TAG), and Combinatory Categorial Grammar (CCG), where in each case close theoretical attention was paid both to the computational tractability of parsing, and the mapping from syntax to semantics. Among the most important developments in the latter area were Richard Montague's profound insights into the logical (especially intensional) semantics of language, and Hans Kamp's and Irene Heim's development of Discourse Representation Theory (DRT), offering a systematic, semantically formal account of anaphora in language.
A major shift in nearly all aspects of natural language processing began in the late 1980s and was virtually complete by the end of 1995: this was the shift to corpus-based, statistical approaches (signalled for instance by the appearance of two special issues on the subject by the quarterly Computational Linguistics in 1993). The new paradigm was enabled by the increasing availability and burgeoning volume of machine-readable text and speech data, and was driven forward by the growing awareness of the importance of the distributional properties of language, the development of powerful new statistically based learning techniques, and the hope that these techniques would overcome the scalability problems that had beset computational linguistics (and more broadly AI) since its beginnings.
The corpus-based approach has indeed been quite successful in producing comprehensive, moderately accurate speech recognizers, part-of-speech (POS) taggers, parsers for learned probabilistic phrase-structure grammars, and even MT and text-based QA systems and summarization systems. However, semantic processing has been restricted to rather shallow aspects, such as extraction of specific data concerning specific kinds of events from text (e.g., location, date, perpetrators, victims, etc., of terrorist bombings) or extraction of clusters of argument types, relational tuples, or paraphrase sets from text corpora. Currently, the corpus-based, statistical approaches are still dominant, but there appears to be a growing movement towards integration of formal logical approaches to language with corpus-based statistical approaches in order to achieve deeper understanding and more intelligent behavior in language comprehension and dialogue systems. There are also efforts to combine connectionist and neural-net approaches with symbolic and logical ones. The following sections will elaborate on many of the topics touched on above. General references for computational linguistics are Allen 1995, Jurafsky and Martin 2009, and Clark et al. 2010.
2. Syntax and parsing
2.1 The structural hierarchy
Language is structured at multiple levels, beginning in the case of spoken language with patterns in the acoustic signal that can be mapped to phones (the distinguishable successive sounds of which languages are built up). Groups of phones that are equivalent for a given language (not affecting the words recognized by a hearer, if interchanged) are the phonemes of the language. The phonemes in turn are the constituents of morphemes (minimal meaningful word segments), and these provide the constituents of words. (In written language one speaks instead of characters, graphemes, syllables, and words.) Words are grouped into phrases, such as noun phrases, verb phrases, adjective phrases and prepositional phrases, which are the structural components of sentences, expressing complete thoughts. At still higher levels we have various types of discourse structure, though this is generally looser than lower-level structure.
Techniques have been developed for language analysis at all of these structural levels, though space limitations will not permit a serious discussion of methods used below the word level. It should be noted, however, that the techniques developed for speech recognition in the 1980s and 1990s were very influential in turning NLP research towards the new corpus-based, statistical approach referred to above. One key idea was that of hidden Markov models (HMMs), which model “noisy” sequences (e.g., phone sequences, phoneme sequences, or word sequences) as if generated probabilistically by “hidden” underlying states and their transitions. Individually or in groups, successive hidden states model the more abstract, higher-level constituents to be extracted from observed noisy sequences, such as phonemes from phones, words from phonemes, or parts of speech from words. The generation probabilities and the state transition probabilities are the parameters of such models, and importantly these can be learned from training data. Subsequently the models can be efficiently applied to the analysis of new data, using fast dynamic programming algorithms such as the Viterbi algorithm. These quite successful techniques were subsequently generalized to higher-level structure, soon influencing all aspects on NLP.
2.2 Syntax
Before considering how grammatical structure can be represented, analyzed and used, we should ask what basis we might have for considering a particular grammar “correct”, or a particular sentence “grammatical,” in the first place. Of course, these are primarily questions for linguistics proper, but the answers we give certainly have consequences for computational linguistics.
Traditionally, formal grammars have been designed to capture linguists' intuitions about well-formedness as concisely as possible, in a way that also allows generalizations about a particular language (e.g., subject-auxiliary inversion in English questions) and across languages (e.g., a consistent ordering of nominal subject, verb, and nominal object for declarative, pragmatically neutral main clauses). Concerning linguists' specific well-formedness judgments, it is worth noting that these are largely in agreement not only with each other, but also with judgments of non-linguists—at least for “clearly grammatical” and “clearly ungrammatical” sentences (Pinker 2007). Also the discovery that conventional phrase structure supports elegant compositional theories of meaning lends credence to the traditional theoretical methodology.
However, traditional formal grammars have generally not covered any one language comprehensively, and have drawn sharp boundaries between well-formedness and ill-formedness, when in fact people's (including linguists') grammaticality judgments for many sentences are uncertain or equivocal. Moreover, when we seek to process sentences “in the wild”, we would like to accommodate regional, genre-specific, and register-dependent variations in language, dialects, and erroneous and sloppy language (e.g., misspellings, unpunctuated run-on sentences, hesitations and repairs in speech, faulty constituent orderings produced by non-native speakers, and fossilized errors by native speakers, such as “for you and I”—possibly a product of schoolteachers inveighing against “you and me” in subject position). Consequently linguists' idealized grammars need to be made variation-tolerant in most practical applications. The way this need has typically been met is by admitting a far greater number of phrase structure rules than linguistic parsimony would sanction—say, 10,000 or more rules instead of a few hundred. These rules are not directly supplied by linguists (computational or otherwise), but rather can be “read off” corpora of written or spoken language that have been decorated by trained annotators (such as linguistics graduate students) with their basic phrasal tree structure. Unsupervised grammar acquisition (often starting with POS-tagged training corpora) is another avenue (see section 9), but results are apt to be less satisfactory. In conjunction with statistical training and parsing techniques, this loosening of grammar leads to a rather different conception of what comprises a grammatically flawed sentence: It is not necessarily one rejected by the grammar, but one whose analysis requires some rarely used rules.
As mentioned in section 1.2, the representations of grammars used in computational linguistics have varied from procedural ones to ones developed in formal linguistics, and systematic, tractably parsable variants developed by computationally oriented linguists. Winograd's shrdlu program, for example, contained code in his programmar language expressing,
To parse a sentence, try parsing a noun phrase (NP); if this fails, return NIL, otherwise try parsing a verb phrase (VP) next and if this fails, or succeeds with words remaining, return NIL, otherwise return success.
Similarly Woods' grammar for lunar was based on a certain kind of procedurally interpreted transition graph (an augmented transition network, or ATN), where the sentence subgraph might contain an edge labeled NP (analyze an NP using the NP subgraph) followed by an edge labeled VP (analogously interpreted). In both cases, local feature values (e.g., the number and person of a NP and VP) are registered, and checked for agreement as a condition for success. A closely related formalism is that of definite clause grammars (e.g., Pereira & Warren 1982), which employ Prolog to assert “facts” such as that if the input word sequence contains an NP reaching from index I1 to index I2 and a VP reaching from index I2 to index I3, then the input contains a sentence reaching from index I1 to index I3. (Again, feature agreement constraints can be incorporated into such assertions as well.) Given the goal of proving the presence of a sentence, the goal-chaining mechanism of Prolog then provides a procedural interpretation of these assertions.
At present the most commonly employed declarative representations of grammatical structure are context-free grammars (CFGs) as defined by Noam Chomsky (1956, 1957), because of their simplicity and efficient parsability. Chomsky had argued that only deep linguistic representations are context-free, while surface form is generated by transformations (for example, in English passivization and in question formation) that result in a non-context-free language. However, it was later shown that on the one hand, unrestricted Chomskian transformational grammars allowed for computationally intractable and even undecidable languages, and on the other, that the phenomena regarded by Chomsky as calling for a transformational analysis could be handled within a context-free framework by use of suitable features in the specification of syntactic categories. Notably, unbounded movement, such as the apparent movement of the final verb object to the front of the sentence in “Which car did Jack urge you to buy?”, was shown to be analyzable in terms of a gap (or slash) feature of type /NP[wh] that is carried by each of the two embedded VPs, providing a pathway for matching the category of the fronted object to the category of the vacated object position. Within non-transformational grammar frameworks, one therefore speaks of unbounded (or long-distance) dependencies instead of unbounded movement. At the same time it should be noted that at least some natural languages have been shown to be mildly context-sensitive (e.g., Dutch and Swiss German exhibit cross-serial dependencies where a series of nominals “NP1 NP2 NP3 …” need to be matched, in the same order, with a subsequent series of verbs, “V1 V2 V3 …”). Grammatical frameworks that seem to allow for approximately the right degree of mild context sensitivity include Head Grammar, Tree-Adjoining Grammar (TAG), Combinatory Categorial Grammar (CCG), and Linear Indexed Grammar (LIG). Head grammars allow insertion of a complement between the head of a phrase (e.g., the initial verb of a VP, the final noun of a NP, or the VP of a sentence) and an already present complement; they were a historical predecessor of Head-Driven Phrase Structure Grammar (HPSG), a type of unification grammar (see below) that has received much attention in computational linguistics. However, unrestricted HPSG can generate the recursively enumerable (in general only semi-decidable) languages.
A typical (somewhat simplified) sample fragment of a context-free grammar is the following, where phrase types are annotated with feature-value pairs:
| S[vform:v] | → | NP[pers:p numb:n case:subj] VP[vform:v pers:p numb:n] |
| VP[vform:v pers:p numb:n] | → | V[subcat:_np vform:v pers:p numb:n] NP[case:obj] |
| NP[pers:3 numb:n] | → | Det[pers:3 numb:n] N[numb:n] |
| NP[numb:n pers:3 case:c] | → | Name[numb:n pers:3 case:c] |
Here v, n, p, c are variables that can assume values such as ‘past’, ‘pres’, ‘base’, ‘pastparticiple’, … (i.e., various verb forms), ‘1’, ‘2’, ‘3’ (1st, 2nd, and 3rd person), ‘sing’, ‘plur’, and ‘subj’, ‘obj’. The subcat feature indicates the complement requirements of the verb. The lexicon would supply entries such as
V[subcat:_np vform:pres numb:sing pers:3] → loves Det[pers:3 numb:sing] → a N[pers:3 numb:sing] → mortal Name[pers:3 numb:sing gend:fem case:subj] → Thetis,
allowing, for example, a phrase structure analysis of the sentence “Thetis loves a mortal” (where we have omitted the feature names for simplicity, leaving only their values, and ignored the case feature):
![[a tree diagram: at the top,
S[pres], a line connects the top node to first, NP[3 sing subj], which
connects to, Name[3 sing subj], which connects to
‘Thetis’. A second line from the top node connects to
VP[pres 3 sing] which in turn first connects to V[_np pres 3 sing]
that connects to ‘loves’. Second it connects to NP[3
sing] that in turn connects to Def[3 sing] (and that to
‘a’) and N[3 sing] (and that to ‘mortal’).]](fig1.png)
Figure 1: Syntactic analysis of a sentence as a parse tree
As a variant of CFGs, dependency grammars (DGs) also enjoy wide popularity. The difference from CFGs is that hierarchical grouping is achieved by directly subordinating words to words (allowing for multiple dependents of a head word), rather than phrases to phrases. For example, in the sentence of figure 1 we would treat Thetis and mortal as dependents of loves, using dependency links labeled subj and obj respectively, and the determiner a would in turn be a dependent of mortal, via a dependency link mod (for modifier). Projective dependency grammars are ones with no crossing dependencies (so that the descendants of a node form a continuous text segment), and these generate the same languages as CFGs. Significantly, mildly non-projective dependency grammars, allowing a head word to dominate two separated blocks, provide the same generative capacity as the previously mentioned mildly context-sensitive frameworks that are needed for some languages (Kuhlmann 2013).
As noted at the beginning of this section, traditional formal grammars proved too limited in coverage and too rigid in their grammaticality criteria to provide a basis for robust coverage of natural languages as actually used, and this situation persisted until the advent of probabilistic grammars derived from sizable phrase-bracketed corpora (notably the Penn Treebank). The simplest example of this type of grammar is a probabilistic context-free grammar or PCFG. In a PCFG, each phrase structure rule X → Y1 … Yk is assigned a probability, viewed as the probability that a constituent of type X will be expanded into a sequence of (immediate) constituents of types Y1, …, Yk. At the lowest level, the expansion probabilities specify how frequently a given part of speech (such as Det, N, or V) will be realized as a particular word. Such a grammar provides not only a structural but also a distributional model of language, predicting the frequency of occurrence of various phrase sequences and, at the lowest level, word sequences.
However, the simplest models of this type do not model the statistics of actual language corpora very accurately, because the expansion probabilities for a given phrase type (or part of speech) X ignore the surrounding phrasal context and the more detailed properties (such as head words) of the generated constituents. Yet context and detailed properties are very influential; for example, whether the final prepositional phrase in “She detected a star with {binoculars, planets}” modifies detected or planets is very dependent on word choice. Such modeling inaccuracies lead to parsing inaccuracies (see next subsection), and therefore generative grammar models have been refined in various ways, for example (in so-called lexicalized models) allowing for specification of particular phrasal head words in rules, or (in tree substitution grammars) allowing expansion of nonterminals into subtrees of depth 2 or more. Nevertheless, it seems likely that fully accurate distributional modeling of language would need to take account of semantic content, discourse structure, and intentions in communication, not only of phrase structure. Possibly construction grammars (e.g., Goldberg 2003), which emphasize the coupling between the entrenched patterns of language (including ordinary phrase structure, clichés, and idioms) and their meanings and discourse function, will provide a conceptual basis for building statistical models of language that are sufficiently accurate to enable more nearly human-like parsing accuracy.
2.3 Parsing
Natural language analysis in the early days of AI tended to rely on template matching, for example, matching templates such as (X has Y) or (how many Y are there on X) to the input to be analyzed. This of course depended on having a very restricted discourse and task domain. By the late 1960s and early 70s, quite sophisticated recursive parsing techniques were being employed. For example, Woods' lunar system used a top-down recursive parsing strategy interpreting an ATN in the manner roughly indicated in section 2.2 (though ATNs in principle allow other parsing styles). It also saved recognized constituents in a table, much like the class of parsers we are about to describe. Later parsers were influenced by the efficient and conceptually elegant CFG parsers described by Jay Earley (1970) and (separately) by John Cocke, Tadao Kasami, and Daniel Younger (e.g., Younger 1967). The latter algorithm, termed the CYK or CKY algorithm for the three separate authors, was particularly simple, using a bottom-up dynamic programming approach to first identify and tabulate the possible types (nonterminal labels) of sentence segments of length 1 (i.e., words), then the possible types of sentence segments of length 2, and so on, always building on the previously discovered segment types to recognize longer phrases. This process runs in cubic time in the length of the sentence, and a parse tree can be constructed from the tabulated constituents in quadratic time. The CYK algorithm assumes a Chomsky Normal Form (CNF) grammar, allowing only productions of form Np → Nq Nr, or Np → w, i.e., generation of two nonterminals or a word from any given nonterminal. This is only a superficial limitation, because arbitrary CF grammars are easily converted to CNF.
The method most frequently employed nowadays in fully analyzing sentential structure is chart parsing. This is a conceptually simple and efficient dynamic programming method closely related to the algorithms just mentioned; i.e., it begins by assigning possible analyses to the smallest constituents and then inferring larger constituents based on these, until an instance of the top-level category (usually S) is found that spans the given text or text segment. There are many variants, depending on whether only complete constituents are posited or incomplete ones as well (to be progressively extended), and whether we proceed left-to-right through the word stream or in some other order (e.g., some seemingly best-first order). A common variant is a left-corner chart parser, in which partial constituents are posited whenever their “left corner”—i.e., leftmost constituent on the right-hand side of a rule—is already in place. Newly completed constituents are placed on an agenda, and items are successively taken off the agenda and used if possible as left corners of new, higher-level constituents, and to extend partially completed constituents. At the same time, completed constituents (or rather, categories) are placed in a chart, which can be thought of as a triangular table of width n and height n (the number of words processed), where the cell at indices (i, j), with j > i, contains the categories of all complete constituents so far verified reaching from position i to position j in the input. The chart is used both to avoid duplication of constituents already built, and ultimately to reconstruct one or more global structural analyses. (If all possible chart entries are built, the final chart will allow reconstruction of all possible parses.) Chart-parsing methods carry over to PCFGs essentially without change, still running within a cubic time bound in terms of sentence length. An extra task is maintaining probabilities of completed chart entries (and perhaps bounds on probabilities of incomplete entries, for pruning purposes).
Because of their greater expressiveness, TAGs and CCGs are harder to parse in the worst case (O(n6)) than CFGs and projective DGs (O(n3)), at least with current algorithms (see Vijay-Shankar & Weir 1994 for parsing algorithms for TAG, CCG, and LIG based on bottom-up dynamic programming). However, it does not follow that TAG parsing or CCG parsing is impractical for real grammars and real language, and in fact parsers exist for both that are competitive with more common CFG-based parsers.
Finally we mention connectionist models of parsing, which perform syntactic analysis using layered (artificial) neural nets (ANNs, NNs) (see Palmer-Brown et al. 2002; Mayberry and Miikkulainen 2008; and Bengio 2008 for surveys). There is typically a layer of input units (nodes), one or more layers of hidden units, and an output layer, where each layer has (excitatory and inhibitory) connections forward to the next layer, typically conveying evidence for higher-level constituents to that layer. There may also be connections within a hidden layer, implementing cooperation or competition among alternatives. A linguistic entity such as a phoneme, word, or phrase of a particular type may be represented within a layer either by a pattern of activation of units in that layer (a distributed representation) or by a single activated unit (a localist representation).
One of the problems that connectionist models need to confront is that inputs are temporally sequenced, so that in order to combine constituent parts, the network must retain information about recently processed parts. Two possible approaches are the use of simple recurrent networks (SRNs) and, in localist networks, sustained activation. SRNs use one-to-one feedback connections from the hidden layer to special context units aligned with the previous layer (normally the input layer or perhaps a secondary hidden layer), in effect storing their current outputs in those context units. Thus at the next cycle, the hidden units can use their own previous outputs, along with the new inputs from the input layer, to determine their next outputs. In localist models it is common to assume that once a unit (standing for a particular concept) becomes active, it stays active for some length of time, so that multiple concepts corresponding to multiple parts of the same sentence, and their properties, can be simultaneously active. A problem that arises is how the properties of an entity that are active at a given point in time can be properly tied to that entity, and not to other activated entities. (This is the variable binding problem, which has spawned a variety of approaches—see Browne and Sun 1999). One solution is to assume that unit activation consists of pulses emitted at a globally fixed frequency, and pulse trains that are in phase with one another correspond to the same entity (e.g., see Henderson 1994). Much current connectionist research borrows from symbolic processing perspectives, by assuming that parsing assigns linguistic phrase structures to sentences, and treating the choice of a structure as simultaneous satisfaction of symbolic linguistic constraints (or biases). Also, more radical forms of hybridization and modularization are being explored, such as interfacing a NN parser to a symbolic stack, or using a neural net to learn the probabilities needed in a statistical parser, or interconnecting the parser network with separate prediction networks and learning networks. For an overview of connectionist sentence processing and some hybrid methods (see Crocker 2010).
2.4 Coping with syntactic ambiguity
If natural language were structurally unambiguous with respect to some comprehensive, effectively parsable grammar, our parsing technology would presumably have attained human-like accuracy some time ago, instead of levelling off at about 90% constituent recognition accuracy. In fact, however, language is ambiguous at all structural levels: at the level of speech sounds (“recognize speech” vs. “wreck a nice beach”); morphology (“un-wrapped” vs. “unwrap-ped”); word category (round as an adjective, noun, verb or adverb); compound word structure (wild goose chase); phrase category (nominal that-clause vs. relative clause in “the idea that he is entertaining”); and modifier (or complement) attachment (“He hit the man with the baguette”). The parenthetical examples here have been chosen so that their ambiguity is readily noticeable, but ambiguities are far more abundant than is intuitively apparent, and the number of alternative analyses of a moderately long sentence can easily run into the thousands.
Naturally, alternative structures lead to alternative meanings, as the above examples show, and so structural disambiguation is essential. The problem is exacerbated by ambiguities in the meanings and discourse function even of syntactically unambiguous words and phrases, as discussed below (section 4). But here we just mention some of the structural preference principles that have been employed to achieve at least partial structural disambiguation. First, some psycholinguistic principles that have been suggested are Right Association (RA) (or Late Closure, LC), Minimal Attachment (MA), and Lexical Preference (LP). The following examples illustrate these principles:
- (2.1)
- (RA) He bought the book that I had selected for Mary.
- (Note the preference for attaching for Mary to selected rather than bought.)
- (2.2)
- (MA?) She carried the groceries for Mary.
- (Note the preference for attaching for Mary to carried, rather than groceries, despite RA. The putative MA-effect might actually be an LP-like verb modification preference.)
- (2.3)
- (LP) She describes men who have worked on farms as cowboys.
- (Note the preference for attaching as cowboys to describes, rather than worked.)
Another preference noted in the literature is for parallel structure in coordination, as illustrated by the following examples:
- (2.4)
- They asked for tea and coffee with sugar.
- (Note the preference for the grouping [[tea and coffee] with sugar], despite RA.)
- (2.5)
- John decided to buy a novel, and Mary, a biography.
- (The partially elided conjunct is understood as “Mary decided to buy a biography”.)
- (2.6)
- John submitted short stories to the editor, and poems too.
- (The partially elided conjunct is understood as “submitted poems to the editor too”.)
Finally, the following example serves to illustrate the significance of frequency effects, though such effects are hard to disentangle from semantic biases for any single sentence (improvements in parsing through the use of word and phrase frequencies provide more compelling evidence):
- (2.7)
- What are the degrees of freedom that an object in space has?
- (Note the preference for attaching the relative clause to degrees of freedom, rather than freedom, attributable to the tendency of degree(s) of freedom to occur as a “multiword”.)
3. Semantic representation
Language serves to convey meaning. Therefore the analysis of syntactic structure takes us only partway towards mechanizing that central function, and the merits of particular approaches to syntax hinge on their utility in supporting semantic analysis, and in generating language from the meanings to be communicated.
This is not to say that syntactic analysis is of no value in itself—it can provide a useful support in applications such as grammar checking and statistical MT. But for the more ambitious goal of inferring and expressing the meaning of language, an essential requirement is a theory of semantic representation, and how it is related to surface form, and how it interacts with the representation and use of background knowledge. We will discuss logicist approaches, cognitive science approaches, and (more briefly) emerging statistical approaches to meaning representation.
3.1 Logicist approaches to meaning representation
Most linguistic semanticists, cognitive scientists, and anthropologists would agree that in some sense, language is a mirror of mind. But views diverge concerning how literally or non-literally this tenet should be understood. The most literal understanding, which we will term the logicist view, is the one that regards language itself as a logical meaning representation with a compositional, indexical semantics—at least when we have added brackets as determined by parse trees, and perhaps certain other augmentation (variables, lambda-operators, etc.) In itself, such a view makes no commitments about mental representations, but application of Occam's razor and the presumed co-evolution of thought and language then suggest that mentalese is itself language-like. The common objection that “human thinking is not logical” carries no weight with logicists, because logical meaning representations by no means preclude nondeductive modes of inference (induction, abduction, etc.); nor are logicists impressed by the objection that people quickly forget the exact wording of verbally conveyed information, because both canonicalization of inputs and systematic discarding of all but major entailments can account for such forgetting. Also assumption of a language-like, logical mentalese certainly does not preclude other modes of representation and thought, such as imagistic ones, and synergistic interaction with such modes (Paivio 1986; Johnston & Williams 2009).
Relating language to logic
Since Richard Montague (see especially Montague 1970, 1973) deserves much of the credit for demonstrating that language can be logically construed, let us reconsider the sentence structure in figure 1 and the corresponding grammar rules and vocabulary, but this time suppressing features, and instead indicating how logical interpretations expressed in (a variant of) Montague's type-theoretic intensional logic can be obtained compositionally. We slightly “twist” Montague's type system so that the possible-world argument always comes last, rather than first, in the denotation of a symbol or expression. For example, a two-place predicate will be of type (e → (e → (s → t))) (successively applying to an entity, another entity, and finally a possible world to yield a truth value), rather than Montague's type (s → (e → (e → t))), where the world argument is first. This dispenses with numerous applications of Montague's intension (∧) and extension (∨) operators, and also slightly simplifies truth conditions. For simplicity we are also ignoring contextual indices here, and treating nouns and VPs as true or false of individuals, rather than individual concepts (as employed by Montague to account for such sentences as “The temperature is 90 and rising”).
S → NP VP; S′ = NP′(VP′) VP → V NP; VP′ = (λx NP′(λy V′(y)(x))) NP → Det N; NP′ = Det′(N′) NP → Name; NP′ = Name′
Here primed constituents represent the intensional logic translations of the corresponding constituents. (Or we can think of them as metalinguistic expressions standing for the set-theoretic denotations of the corresponding constituents.) Several points should be noted. First, each phrase structure rule is accompanied by a unique semantic rule (articulated as the rule-to-rule hypothesis by Emmon Bach (1976)), where the denotation of each phrase is fully determined by the denotations of its immediate constituents: the semantics is compositional.
Second, in the S′-rule, the subject is assumed to be a second-order predicate that is applied to the denotation of the VP (a monadic predicate) to yield a sentence intension, whereas we would ordinarily think of the subject-predicate semantics as being the other way around, with the VP-denotation being applied to the subject. But Montague's contention was that his treatment was the proper one, because it allows all types of subjects—pronouns, names, and quantified NPs—to be handled uniformly. In other words, an NP always denotes a second-order property, or (roughly speaking) a set of first-order properties (see also Lewis 1970). So for example, Thetis denotes the set of all properties that Thetis (a certain contextually determined individual with that name) has; (more exactly, in the present formulation Thetis denotes a function from properties to sentence intensions, where the intension obtained for a particular property yields truth in worlds where the entity referred to has that property); some woman denotes the union of all properties possessed by at least one woman; and every woman denotes the set of properties shared by all women. Accordingly, the S′-rule yields a sentence intension that is true at a given world just in case the second-order property denoted by the subject maps the property denoted by the VP to such a truth-yielding intension.
Third, in the VP′-rule, variables x and y are assumed to be of type e (they take basic individuals as values), and the denotation of a transitive verb should be thought of as a function that is applied first to the object, and then to the subject (yielding a function from worlds to truth values—a sentence intension). The lambda-abstractions in the VP′-rule can be understood as ensuring that the object NP, which like any NP denotes a second-order property, is correctly applied to an ordinary property (that of being the love-object of a certain x), and the result is a predicate with respect to the (still open) subject position. The following is an interpreted sample vocabulary:
V → loves; V′ = loves Det → a; Det′ = λP λQ(∃x[P(x) ∧ Q(x)]) (For comparison: Det → every; Det′ = λP λQ(∀x[P(x) ⊃ Q(x)]) N → mortal; N′ = mortal Name → Thetis; Name′ = λP(P(Thetis))
Note the interpretation of the indefinite determiner (on line 2) as a generalized quantifier—in effect a second-order predicate over two ordinary properties, where these properties have intersecting truth domains. We could have used an atomic symbol for this second-order predicate, but the above way of expanding it shows the relation of the generalized quantifier to the ordinary existential quantifier. Though it is a fairly self-evident matter, we will indicate in section 4.1 how the sentence “Thetis loves a mortal” yields the following representation after some lambda-conversions:
(∃x [mortal(x) ∧ loves(x)(Thetis)]).
(The English sentence also has a generic or habitual reading, “Thetis loves mortals in general”, which we ignore here.) This interpretation has rather a classical look to it, but only because of the reduction from generalized to ordinary quantifiers that we have built into the lexical semantics of the indefinite a in the above rules, instead of using an atomic symbol for it. Montague was particularly interested in dealing satisfactorily with intensional locutions, such as “John seeks a unicorn.” This does not require the existence of a unicorn for its truth—John has a certain relation to the unicorn-property, rather than to an existing unicorn. Montague therefore treated all predicate arguments as intensions; i.e., he rendered “John seeks a unicorn” as
seeks(λQ ∃x[unicorn(∧x) ∧ Q(∧x)]) (∧john),
which can be reduced to a version where unicorn is extensionalized to unicorn*:
seeks(λQ ∃x[unicorn*(x) ∧ Q(∧x)]) (∧john).
But ultimately Montague's treatment of NPs, though it was in a sense the centerpiece of his proposed conception of language-as-logic, was not widely adopted in computational linguistics. This was in part because the latter community was not convinced that an omega-order logic was needed for NL semantics, found the somewhat complex treatment of NPs in various argument positions and in particular, the treatment of scope ambiguities in terms of multiple syntactic analyses, unattractive, and was preoccupied with other semantic issues, such as adequately representing events and their relationships, and developing systematic nominal and verb “ontologies” for broad-coverage NL analysis. Nonetheless, the construal of language as logic left a strong imprint on computational semantics, generally steering the field towards compositional approaches, and in some approaches such as CCG, providing a basis for a syntax tightly coupled to a type-theoretic semantics (Bach et al. 1987; Carpenter 1997).
An alternative to Montague's syntax-based approach to quantifier scope ambiguity is to regard NPs of form Det+N (or strictly, Det+N-bar) as initially unscoped higher-order predicates in an underspecified logical form, to be subsequently “raised” so as to apply to a first-order predicate obtained by lambda-abstraction of the vacated term position. For example, in the sentence “Everyone knows a poem”, with the object existentially interpreted, we would have the underspecified LF
knows⟨a(poem)⟩⟨every(person)⟩
(without reducing determiners to classical quantifiers) and we can now “raise” ⟨a(poem)⟩ to yield
a(poem)(λy knows(y)⟨every(person)⟩,
and then “raise” ⟨every(person)⟩ to yield either
a(poem)(λy every(person)(λx knows(y)(x))),
or
every(person)(λx a(poem)(λy knows(y)(x))).
Thus we obtain a reading according to which there is a poem that everyone knows, and another according to which everyone knows some poem (not necessarily the same one). (More on scope disambiguation will follow in section 4). A systematic version of this approach, known as Cooper storage (see Barwise & Cooper 1981) represents the meaning of phrases in two parts, namely a sequence of NP-interpretations (as higher-order predicates) and the logical matrix from which the NP-interpretations were extracted.
But one can also take a more conventional approach, where first of all, the use of “curried” (Schönfinkel-Church-Curry) functions in the semantics of predication is avoided in favor of relational interpretations, using lexical semantic formulas such as loves′ = λyλx(loves(x, y)), and second, unscoped NP-interpretations are viewed as unscoped restricted quantifiers (Schubert & Pelletier 1982). Thus the unscoped LF above would be knows(⟨∃poem⟩, ⟨∀person⟩), and scoping of quantifiers, along with their restrictors, now involves “raising” quantifiers to take scope over a sentential formula, with simultaneous introduction of variables. The two results corresponding to the two alternative scopings are then
(∃y: poem(y))(∀x: person(x))knows(x, y),
and
(∀x: person(x))(∃y: poem(y))knows(x, y).
While this strategy departs from the strict compositionality of Montague Grammar, it achieves results that are often satisfactory for the intended purposes and does so with minimal computational fuss. A related approach to logical form and scope ambiguity enjoying some current popularity is minimal recursion semantics (MRS) (Copestake et al. 2005), which goes even further in fragmenting the meaningful parts of an expression, with the goal of allowing incremental constraint-based assembly of these pieces into unambiguous sentential LFs. Another interesting development is an approach based on continuations, a notion taken from programming language theory (where a continuation is a program execution state as determined by the steps still to be executed after the current instruction). This also allows for a uniform account of the meaning of quantifiers, and provides a handle on such phenomena as “misplaced modifiers”, as in “He had a quick cup of coffee” (Barker 2004).
An important innovation in logical semantics was discourse representation theory (DRT) (Kamp 1981; Heim 1982), aimed at a systematic account of anaphora. In part, the goal was to provide a semantic explanation for (in)accessibility of NPs as referents of anaphoric pronouns, e.g., in contrasting examples such as “John doesn't drive a car; *he owns it,” vs. “John drives a car; he owns it”. More importantly, the goal was to account for the puzzling semantics of sentences involving donkey anaphora, e.g., “If John owns a donkey, he beats it.” Not only is the NP a donkey, the object of the if-clause, accessible as referent of the anaphoric it, contrary to traditional syntactic binding theory (based on the notion of C-command), but furthermore we seem to obtain an interpretation of the type “John beats every donkey that he owns”, which cannot be obtained by “raising” the embedded indefinite a donkey to take scope over the entire sentence. There is also a weaker reading of the type, “If John owns a donkey, he beats a donkey that he owns”, and this reading also is not obtainable via any scope analysis. Kamp and Heim proposed a dynamic process of sentence interpretation in which a discourse representation structure (DRS) is built up incrementally. A DRS consists of a set of discourse referents (variables) and a set of conditions, where these conditions may be simple predications or equations over discourse referents, or certain logical combinations of DRS's (not of conditions). The DRS for the sentence under consideration can be written linearly as
[: [x, y: john(x), donkey(y)] ⇒ [u, v: he(u), it(v), beats(u, v), u=x, v=y]]
or diagrammed as
![[a box with a horizontal line
breaking it into two. The top half takes up about one-sixth of the
space and is empty. The bottom half contains two other boxes side by
side with a double right arrow connecting them. The left box is also
divided in two parts horizontally; the top half has ‘x,y’;
the bottom half has three lines containing ‘john(x)’,
‘donkey(y)’, and ‘owns(x,y)’ respectively.
The right box is also divided in two parts horizontally; the top half
has ‘u,v’; the bottom half has five lines containing
‘he(u)’, ‘it(u)’, ‘beats(u,v)’,
‘u=x’, and ‘v=y’ respectively.]](fig2.png)
Figure 2: DRS for “If John owns a donkey, he beats it”
Here x, y, u, v are discourse referents introduced by John, a donkey, he, and it, and the equations u=x, v=y represent the result of reference resolution for he and it. Discourse referents in the antecedent of a conditional are accessible in the consequent, and discourse referents in embedding DRSs are accessible in the embedded DRSs. Semantically, the most important idea is that discourse referents are evaluated dynamically. We think of a variable assignment as a state, and this state changes as we evaluate a DRS outside-to-inside, left-to-right. For example (simplifying a bit), the conditional DRS in figure 4 is true (in a given model) if every assignment with domain {x, y} that makes the antecedent true can be extended to an assignment (new state) with domain {x, y, u, v} that makes the consequent true.
On the face of it, DRT is noncompositional (though DRS construction rules are systematically associated with phrase structure rules); but it can be recast in compositional form, still of course with a dynamic semantics. A closely related approach, dynamic predicate logic (DPL) retains the classical quantificational syntax, but in effect treats existential quantification as nondeterministic assignment, and provides an overtly compositional alternative to DRT (Groenendijk & Stokhof 1991). Perhaps surprisingly, the impact of DRT on practical computational linguistics has been quite limited, though it certainly has been and continues to be actively employed in various projects. One reason may be that donkey anaphora rarely occurs in the text corpora most intensively investigated by computational linguists so far (though it is arguably pervasive and extremely important in generic sentences and generic passages, including those found in lexicons or sources such as Common Sense Open Mind—see sections 4.3 and 8.3). Another reason is that reference resolution for non-donkey pronouns (and definite NPs) is readily handled by techniques such as Skolemization of existentials, so that subsequently occurring anaphors can be identified with the Skolem constants introduced earlier. Indeed, it turns out that both explicit and implicit variants of Skolemization, including functional Skolemization, are possible even for donkey anaphora (e.g., in sentences such as “If every man has a gun, many will use it”—see Schubert 2007). Finally, another reason for the limited impact of DRT and other dynamic semantic theories may be precisely that they are dynamic: The evaluation of a formula in general requires its preceding and embedding context, and this interferes with the kind of knowledge modularity (the ability to use any given knowledge item in a variety of different contexts) desirable for inference purposes. Here it should be noted that straightforward translation procedures from DRT, DPL, and other dynamic theories to static logics exist (e.g., to FOL, for nonintensional versions of the dynamic approaches), but if such a conversion is desirable for practical purposes, then the question arises whether starting with a dynamic representation is at all advantageous.
Thematic roles and (neo-)Davidsonian representations
A long-standing issue in linguistic semantics has been the theoretical status of thematic roles in the argument structure of verbs and other argument-taking elements of language (e.g., Dowty 1991). The syntactically marked cases found in many languages correspond intuitively to such thematic roles as agent, theme, patient, instrument, recipient, goal, and so on, and in English, too, the sentence subject and object typically correspond respectively to the agent and theme or patient of an action, and other roles may be added as an indirect object or more often as prepositional phrase complements and adjuncts. To give formal expression to these intuitions, many computational linguists decompose verbal (and other) predicates derived from language into a core predicate augmented with explicit binary relations representing thematic roles. For example, the sentence
- (3.1)
- John kicked the ball to the fence
might be represented (after referent determination) as
∃e(kick(e) ∧ before(e, Now1) ∧ agent(e, John) ∧ theme(e, Ball2) ∧ goal-loc(e, Fence3)),
where e is thought of as the kicking event. Such a representation is called neo-Davidsonian, acknowledging Donald Davidson's advocacy of the view that verbs tacitly introduce existentially quantified events (Davidson 1967a). The prefix neo- indicates that all arguments and adjuncts are represented in terms of thematic roles, which was not part of Davidson's proposal but is developed, for example, in (Parsons 1990). (Parsons attributes the idea of thematic roles to the 4th century BCE Sanskrit grammarian Pāṇini.) One advantage of this style of representation is that it absolves the writer of the interpretive rules from the vexing task of distinguishing verb complements, to be incorporated into the argument structure of the verb, from adjuncts, to be used to add modifying information. For example, it is unclear in (3.1) whether to the fence should be treated as supplying an argument of kick, or whether it merely modifies the action of John kicking the ball. Perhaps most linguists would judge the latter answer to be correct (because an object can be kicked without the intent of propelling it to a goal location), but intuitions are apt to be ambivalent for at least one of a set of verbs such as dribble, kick, maneuver, move and transport.
However, thematic roles also introduce new difficulties. As pointed out by Dowty (1991), thematic roles lack well-defined semantics. For example, while (3.1) clearly involves an animate agent acting causally upon a physical object, and the PP evidently supplies a goal location, it is much less clear what the roles should be in (web-derived) sentences such as (3.2–3.4), and what semantic content they would carry:
- (3.2)
- The surf tossed the loosened stones against our feet.
- (3.3)
- A large truck in front of him blocked his view of the traffic light.
- (3.4)
- Police used a sniffer dog to smell the suspect's luggage.
As well, the uniform treatment of complements and adjuncts in terms of thematic relations does not absolve the computational linguist from the task of identifying the subcategorized constituents of verb phrases (and similarly, NPs and APs), so as to guide syntactic and semantic expectations in parsing and interpretation. And these subcategorized constituents correspond closely to the complements of the verb, as distinct from any adjuncts. Nevertheless, thematic role representations are widely used, in part because they mesh well with frame-based knowledge representations for domain knowledge. These are representations that characterize a concept in terms of its type (relating this to supertypes and subtypes in an inheritance hierarchy), and a set of slots (also called attributes or roles) and corresponding values, with type constraints on values. For example, in a purchasing domain, we might have a purchase predicate, perhaps with supertype acquire, subtypes like purchase-in-installments, purchase-on-credit, or purchase-with-cash, and attributes with typed values such as (buyer (a person-or-group)), (seller (a person-or-group)), (item (a thing-or-service)), (price (a monetary-amount)), and perhaps time, place, and other attributes. Thematic roles associated with relevant senses of verbs and nouns such as buy, sell, purchase, acquire, acquisition, take-over, pick up, invest in, splurge on, etc., can easily be mapped to standard slots like those above. This leads into the issue of canonicalization, which we briefly discuss below under a separate heading.
Expressivity issues
A more consequential issue in computational semantics has been the expressivity of the semantic representation employed, with respect to phenomena such as event and temporal reference, nonstandard quantifiers such as most, plurals, modification, modality and other forms of intensionality, and reification. Full discussion of these phenomena would be out of place here, but some commentary on each is warranted, since the process of semantic interpretation and understanding (as well as generation) clearly depends on the expressive devices available in the semantic representation.
Event and situation reference are essential in view of the fact that many sentences seem to describe events or situations, and to qualify and refer to them. For example, in the sentences
- (3.5)
- Molly barked last night for several minutes. This woke up the neighbors.
the barking event is in effect predicated to have occurred last night and to have lasted for several minutes, and the demonstrative pronoun this evidently refers directly to it; in addition the past tense places the event at some point prior to the time of speech (and would do so even without the temporal adverbials). These temporal and causal relations are readily handled within the Davidsonian (or neo-Davidsonian) framework mentioned above:
- (3.5′)
- bark(Molly, E) ∧ last-night(E, S) ∧ before(E, S) ∧ duration(E)=minutes(N) ∧ several(N). cause-to-wake-up(E, Neighbors, E′) ∧ before(E′, S).
However, examples (3.6) and (3.7) suggest that events can be introduced by negated or quantified formulas, as was originally proposed by Reichenbach (1947):
- (3.6)
- No rain fell for a month, and this caused widespread crop failures.
- (3.7)
- Each superpower imperiled the other with its nuclear arsenal. This situation persisted for decades.
Barwise and Perry (1983) reconceptualized this idea in their Situation Semantics, though this lacks the tight coupling between sentences and events that is arguably needed to capture causal relations expressed in language. Schubert (2000) proposes a solution to this problem in an extension of FOL incorporating an operator that connects situations or events with sentences characterizing them.
Concerning nonstandard quantifiers such as most, we have already sketched the generalized quantifier approach of Montague Grammar, and pointed out the alternative of using restricted quantifiers; an example might be (Most x: dog(x))friendly(x). Instead of viewing most as a second-order predicate, we can specify its semantics by analogy with classical quantifiers: The sample formula is true (under a given interpretation) just in case a majority of individuals satisfying dog(x) (when used as value of x) also satisfy friendly(x). Quantifying determiners such as few, many, much, almost all, etc., can be treated similarly, though ultimately the problem of vagueness needs to be addressed as well (which of course extends beyond quantifiers to predicates and indeed all aspects of a formal semantic representation). Vague quantifiers, rather than setting rigid quantitative bounds, seem instead to convey probabilistic information, as if a somewhat unreliable measuring instrument had been applied in formulating the quantified claim, and the recipient of the information needs to take this unreliability into account in updating beliefs. Apart from their vagueness, the quantifiers under discussion are not first-order definable (e.g., Landman 1991), so that they cannot be completely axiomatized in FOL. But this does not prevent practical reasoning, either by direct use of such quantifiers in the logical representations of sentences (an approach in the spirit of natural logic), or by reducing them to set-theoretic or mereological relations within an FOL framework.
Plurals, as for instance in
- (3.8)
- People gathered in the town square,
present a problem in that the argument of a predicate can be an entity comprised of multiple basic individuals (those we ordinarily quantify over, and ascribe properties to). Most approaches to this problem employ a plural operator, say, plur, allowing us to map a singular predicate P into a plural predicate plur(P), applicable to collective entities. These collective entities are usually assumed to form a join semilattice with atomic elements (singular entities) that are ordinary individuals (e.g., Scha 1981; Link 1983; Landman 1989, 2000). When an overlap relation is assumed, and when all elements of the semilattice are assumed to have a supremum (completeness), the result is a complete Boolean algebra except for lack of a bottom element (because there is no null entity that is a part of all others). One theoretical issue is the relationship of the semilattice of plural entities to the semilattice of material parts of which entities are constituted. Though there are differences in theoretical details (e.g., Link 1983; Bunt 1985), it is agreed that these semilattices should be aligned in this sense: When we take the join of material parts of which several singular or plural entities are constituted, we should obtain the material parts of the join of those singular or plural entities. Note that while some verbal predicates, such as (intransitive) gather, are applicable only to collections, others, such as ate a pizza, are variously applicable to individuals or collections. Consequently, a sentence such as
- (3.9)
- The children ate a pizza,
allows for both a collective reading, where the children as a group ate a single pizza, and a distributive reading, where each of the children ate a pizza (presumably a different one!) One way of dealing with such ambiguities in practice is to treat plural NPs as ambiguous between a collection-denoting reading and an “each member of the collection” reading. For example the children in (3.9) would be treated as ambiguous between the collection of children (which is the basic sense of the phrase) and each of the children. This entails that a reading of type each of the people should also be available in (3.8) — but we can assume that this is ruled out because (intransitive) gather requires a collective argument. In a sentence such as
- (3.10)
- Two poachers caught three aracaris,
we then obtain four readings, based on the two interpretations of each NP. No readings are ruled out, because both catching and being caught can be individual or collective occurrences. Some theorists would posit additional readings, but if these exist, they could be regarded as derivative from readings in which at least one of the terms is collectively interpreted. But what is uncontroversial is that plurals call for an enrichment in the semantic representation language to allow for collections as arguments. In an expression such as plur(child), both the plur operator, which transforms a predicate into another predicate, and the resulting collective predicate, are of nonstandard types.
Modification is a pervasive phenomenon in all languages, as illustrated in the following sentences:
- (3.11)
- Mary is very smart.
- (3.12)
- Mary is an international celebrity.
- (3.13)
- The rebellion failed utterly.
In (3.11), very functions as a predicate modifier, in particular a subsective modifier, since the set of things that are very(P) is a subset of the things that are P. Do we need such modifiers in our logical forms? We could avoid use of a modifier in this case by supposing that smart has a tacit argument for the degree of smartness, where smart(x, d) means that x is smart to degree d; adding that d > T for some threshold T would signify that x is very smart. Other degree adjectives could be handled similarly. However, such a strategy is unavailable for international celebrity in (3.12). International is again subsective (and not intersective—an international celebrity is not something that is both international and a celebrity), and while one can imagine definitions of the particular combination, international celebrity, in an ordinary FOL framework, requiring such definitions to be available for constructing initial logical forms could create formidable barriers to broad-coverage interpretation. (3.13) illustrates a third type of predicate modification, namely VP-modification by an adverb. Note that the modifier cannot plausibly be treated as an implicit predication utter(E) about a Davidsonian event argument of fail. Taken together, the examples indicate the desirability of allowing for monadic-predicate modifiers in a semantic representation. Corroborative evidence is provided in the immediately following discussion.
Intensionality has already been mentioned in connection with Montague Grammar, and there can be no doubt that a semantic representation for natural language needs to capture intensionality in some way. The sentences
- (3.14)
- John believes that our universe is infinite.
- (3.15)
- John looked happy.
- (3.16)
- John designed a starship.
- (3.17)
- John wore a fake beard.
all involve intensionality. The meaning (and thereby the truth value) of the attitudinal sentence (3.14) depends on the meaning (intension) of the subordinate clause, not just its truth value (extension). The meaning of (3.15) depends on the meaning of happy, but does not require happy to be a property of John or anything else. The meaning of (3.16) does not depend on the actual existence of a starship, but does depend on the meaning of that phrase. And fake beard in (3.17) refers to something other than an actual beard, though its meaning naturally depends on the meaning of beard. A Montagovian analysis certainly would deal handily with such sentences. But again, we may ask how much of the expressive richness of Montague's type theory is really essential for computational linguistics. To begin with, sentences such as (3.14) are expressible in classical modal logics, without committing to higher types. On the other hand (3.16) resists a classical modal analysis, even more firmly than Montague's “John seeks a unicorn,” for which an approximate classical paraphrase is possible: “John tries (for him) to find a unicorn”. A modest concession to Montague, sufficient to handle (3.15)–(3.17), is to admit intensional predicate modifiers into our representational vocabulary. We can then treat look as a predicate modifier, so that look(happy) is a new predicate derived from the meaning of happy. Similarly we can treat design as a predicate modifier, if we are willing to treat a starship as a predicative phrase, as we would in “The Enterprise is a starship”. And finally, fake is quite naturally viewed as a predicate modifier, though unlike most nominal modifiers, it is not intersective (#John wore something that was a beard and was fake) or even subsective (#John wore a particular kind of beard). Note that this form of intensionality does not commit us to a higher-order logic—we are not quantifying over predicate extensions or intensions so far, only over individuals (aside from the need to allow for plural entities, as noted). The rather compelling case for intensional predicate modifiers in our semantic vocabulary reinforces the case made above (on the basis on extensional examples) for allowing predicate modification.
Reification, like the phenomena already enumerated, is also pervasive in natural languages. Examples are seen in the following sentences.
- (3.18)
- Humankind may be on a path to self-destruction.
- (3.19)
- Snow is white.
- (3.20)
- Politeness is a virtue.
- (3.21)
- Driving recklessly is dangerous.
- (3.22)
- For John to sulk is unusual.
- (3.23)
- That our universe is infinite is a discredited notion.
(3.18)–(3.21) are all examples of predicate reification. Humankind in (3.18) may be regarded as the name of an abstract kind derived from the nominal predicate human, i.e., with lexical meaning K(human), where K maps predicate intensions to individuals. The status of abstract kinds as individuals is evidenced by the fact that the predicate “be on a path to self-destruction” applies as readily to ordinary individuals as to kinds. The name-like character of the term is apparent from the fact that it cannot readily be premodified by an adjective. The subjects in (3.19) and (3.20) can be similarly analyzed in terms of kinds K(snow) and K(-ness(polite)). (Here -ness is a predicate modifier that transforms the predicate polite, which applies to ordinary (usually human) individuals, into a predicate over quantities of the abstract stuff, politeness.) But in these cases the K operator does not originate in the lexicon, but in a rule pair of type “NP → N, NP′ = K(N′)”. This allows for modification of the nominal predicate before reification, in phrases such as fluffy snow or excessive politeness. The subject of (3.21) might be rendered logically as something like Ka(-ly(reckless)(drive)), where Ka reifies action-predicates, and -ly transforms a monadic predicate intension into a subsective predicate modifier. Finally (3.22) illustrates a type of sentential-meaning reification, again yielding a kind; but in this case it is a kind of situation—the kind whose instances are characterized by John sulking. Here we can posit a reification operator Ke that maps sentence intensions into kinds of situations. This type of sentential reification needs to be distinguished from that-clause reification, such as appears to be involved in (3.14). We mentioned the possibility of a modal-logic analysis of (3.14), but a predicative analysis, where the predicate applies to a reified sentence intension (a proposition) is actually more plausible, since it allows a uniform treatment of that-clauses in contexts like (3.14) and (3.23). The use of reification operators is a departure from a strict Montgovian approach, but is plausible if we seek to limit the expressiveness of our semantic representation by taking predicates to be true or false of individuals, rather than of objects of arbitrarily high types, and likewise take quantification to be over individuals in all cases, i.e., to be first-order.
Some computational linguists and AI researchers wish to go much further in avoiding expressive devices outside those of standard first-order logic. One strategy that can be used to deal with intensionality within FOL is to functionalize all predicates, save one or two. For example, we can treat predications, such as that Romeo loves Juliet, as values of functions that “hold” at particular times: Holds(loves(Romeo, Juliet), t). Here loves is regarded as a function that yields a reified property, while Holds (or in some proposals, True), and perhaps equality, are the only predicates in the representation language. Then we can formalize (3.14), for example, without recourse to intensional semantics as
Holds(believes(John, infinite(Universe)), t)
(where t is some specific time). Humankind in (3.18) can perhaps be represented as the set of all humans as a function of time:
∀x∀t[Holds(member(x, Humankind), t) ↔ Holds(human(x), t)],
(presupposing some axiomatization of naïve set theory); and, as one more example, (4.22) might be rendered as
Holds(unusual(sulk(John)), t)
(for some specific time t). However, a difficulty with this strategy is encountered for quantification within intensional contexts, as in the sentence “John believes that every galaxy harbors some life-form.” While we can represent the (implausible) wide-scope reading “For every galaxy there is some life-form such that John believes that the galaxy harbors that life-form,” using the Holds strategy, we cannot readily represent the natural narrow-scope reading because FOL disallows variable-binding operators within functional terms (but see McCarthy 1990). An entirely different approach is to introduce “eventuality” arguments into all predicates, and to regard a predication as providing a fact about the actual world only if the eventuality corresponding to that predication has been asserted to “occur” (Hobbs 2003). The main practical impetus behind such approaches is to be able to exploit existing FOL inference techniques and technology. However, there is at present no reason to believe that any inferences that are easy in FOL are difficult in a meaning representation more nearly aligned with the structure of natural language; on the contrary, recent work in implementing natural logic (MacCartney & Manning 2009) suggests that a large class of obvious inferences can be most readily implemented in syntactically analyzed natural language (modulo some adjustments)—a framework closer to Montagovian semantics than an FOL-based approach.
Canonicalization, thematic roles (again), and primitives
Another important issue has been canonicalization (or normalization): What transformations should be applied to initial logical forms in order to minimize difficulties in making use of linguistically derived information? The uses that should be facilitated by the choice of canonical representation include the interpretation of further texts in the context of previously interpreted text (and general knowledge), as well as inferential question answering and other inference tasks.
We can distinguish two types of canonicalization: logical normalization and conceptual canonicalization. An example of logical normalization in sentential logic and FOL is the conversion to clause form (Skolemized, quantifier-free conjunctive normal form). The rationale is that reducing multiple logically equivalent formulas to a single form reduces the combinatorial complexity of inference. However, full normalization may not be possible in an intensional logic with a “fine-grained” semantics, where for instance a belief that the Earth is round may differ semantically from the belief that the Earth is round and the Moon is either flat or not flat, despite the logical equivalence of those beliefs.
Conceptual canonicalization involves more radical changes: We replace the surface predicates (and perhaps other elements of the representational vocabulary) with canonical terms from a smaller repertoire, and/or decompose them using thematic roles or frame slots. For example, in a geographic domain, we might replace the relations (between countries) is next to, is adjacent to, borders on, is a neighbor of, shares a border with, etc., with a single canonical relation, say borders-on. In the domain of physical, communicative, and mental events, we might go further and decompose predicates into configurations of primitive predicates. For example, we might express “x walks” in the manner of Schank as
∃e, e′(ptrans(e, x, x) ∧ move(e′, x, feet-of(x)) ∧ by-means-of(e′, e)),
where ptrans(e, x, y) is a primitive predicate expressing that event e is a physical transport by agent x of object y, move expresses bodily motion by an agent, and by-means-of expresses the instrumental-action relation between the move event and the ptrans event. As discussed earlier, these multi-argument predicates might be further decomposed, with ptrans(e, x, y) rewritten as ptrans(e) ∧ agent(e, x) ∧ theme(e, y), and so on. As in the case of logical normalization, conceptual canonicalization is intended to simplify inference, and to minimize the need for the axioms on which inference is based.
A question raised by canonicalization, especially by the stronger versions involving reduction to primitives, is whether significant meaning is lost in this process. For example, the concept of being neighboring countries, unlike mere adjacency, suggests the idea of side-by-side existence of the populations of the countries, in a way that resembles the side-by-side existence of neighbors in a local community. More starkly, reducing the notion of walking to transporting oneself by moving one's feet fails to distinguish walking from running, hopping, skating, and perhaps even bicycling. Therefore it may be preferable to regard conceptual canonicalization as inference of important entailments, rather than as replacement of superficial logical forms by equivalent ones in a more restricted vocabulary. Another argument for the latter position is computational: If we decompose complex actions, such as dining at a restaurant, into constellations of primitive predications, we will need to match the many primitive parts of such constellations even in answering simple questions such as “Did John dine at a restaurant?”. We will comment further on primitives in the context of the following subsection.
3.2 Psychologically motivated approaches to meaning
While many AI researchers have been interested in semantic representation and inference as practical means for achieving linguistic and inferential competence in machines, others have approached these issues from the perspective of modeling human cognition. Prior to the 1980s, computational modeling of NLP and cognition more broadly were pursued almost exclusively within a representationalist paradigm, i.e., one that regarded all intelligent behavior as reducible to symbol manipulation (Newell and Simon's physical symbol systems hypothesis). In the 1980s, connectionist (or neural) models enjoyed a resurgence, and came to be seen by many as rivalling representationalist approaches. We briefly summarize these developments under two subheadings below.
Representationalist approaches
“A physical symbol system has the necessary and sufficient means for general intelligent action.” –Allen Newell and Herbert Simon (1976: 116)
Some of the cognitively motivated researchers working within a representationalist paradigm have been particularly concerned with cognitive architecture, including the associative linkages between concepts, distinctions between types of memories and types of representations (e.g., episodic vs. semantic memory, short-term vs. long-term memory, declarative vs. procedural knowledge), and the observable processing consequences of such architectures, such as sense disambiguation, similarity judgments, and cognitive load as reflected in processing delays. Others have been more concerned with uncovering the actual internal conceptual vocabulary and inference rules that seem to underlie language and thought. M. Ross Quillian's semantic memory model, and models developed by Rumelhart, Norman and Lindsay (Rumelhart et al. 1972; Norman et al. 1975) and by Anderson and Bower (1973) are representative of the former perspective, while Schank and his collaborators (Schank and Colby 1973; Schank and Abelson 1977; Schank and Riesbeck 1981; Dyer 1983) are representative of the latter. A common thread in cognitively motivated theorizing about semantic representation has been the use of graphical semantic memory models, intended to capture direct relations as well as more indirect associations between concepts, as illustrated in Figure 3:
![[two trees, all parents connect
to their nodes by solid arrowed lines unless otherwise indicated. The
first, on the left, with a boxed parent of the word
‘plant’ and nodes of ‘plant1’ (which itself
has nodes of ‘structure’ [connected by a line labeled
‘isa’], ‘living’ [connected by a line labeled
‘prop’], ‘animal’ [connected by a line labeled
‘-prop’], ‘with3’ [connected with a line
labeled ‘prop’ and with a node ‘leaf’],
‘get2’ [connected with a line labeled ‘prop’
and also a reverse line labeled ‘subj’, it has two nodes,
‘food’ connected with a line labeled ‘obj’ and
‘from’, the latter also has nodes ‘air’,
‘earth’ and a dash boxed ‘water’ {the
connection lines of these three nodes are also connected with a dashed
arc labeled ‘or’}]), ‘plant2’ (which itself
has a node of ‘apparatus’ connected by a line labeled
‘isa’ and two dashed lines going to nowhere), and
‘plant3’ (which itself has three dashed lines going to
nowhere); the connection lines of the three plant nodes are also
connected with a solid arc labeled ‘or’. The second tree
with a boxed parent of the word ‘water’ has two dashed
lines going nowhere and a node ‘supply5’ (which itself has
three nodes, ‘person’ connected with a line labeled
‘subj’, the dash boxed ‘water’ from the first
tree connected with a line labeled ‘obj’, and
‘To2’ [which itself has a node ‘object’]); the
three lines under the top parent are connected by a dashed arc labeled
‘or’]](fig3.png)
Figure 3
This particular example is loosely based on Quillian (1968). Quillian suggested that one of the functions of semantic memory, conceived in this graphical way, was to enable word sense disambiguation through spreading activation. For example, processing of the sentence, “He watered the plants”, would involve activation of the terms water and plant, and this activation would spread to concepts immediately associated with (i.e., directly linked to) those terms, and in turn to the neighbors of those concepts, and so on. The preferred senses of the initially activated terms would be those that led to early “intersection” of activation signals originating from different terms. In particular, the activation signals propagating from sense 1 (the living-plant sense) of plant would reach the concept for the stuff, water, in four steps (along the pathways corresponding to the information that plants may get food from water), and the same concept would be reached in two steps from the term water, used as a verb, whose semantic representation would express the idea of supplying water to some target object. Though the sense of plant as a manufacturing apparatus would probably lead eventually to the water concept as well, the corresponding activation path would be longer, and so the living-plant sense of plant would “win”.
Such conceptual representations have tended to differ from logical ones in several respects. One, as already discussed, has been the emphasis by Schank and various other researchers (e.g., Wilks 1978; Jackendoff 1990) on “deep” (canonical) representations and primitives. An often cited psychological argument for primitives is the fact that people rather quickly forget the exact wording of what they read or are told, recalling only the “gist”; it is this gist that primitive decomposition is intended to derive. However, this involves a questionable assumption that subtle distinctions between, say, walking to the park, ambling to the park, or traipsing to the park are simply ignored in the interpretive process, and as noted earlier it neglects the possibility that seemingly insignificant semantic details are pruned from memory after a short time, while major entailments are retained for a longer time.
Another common strain in much of the theorizing about conceptual representation has been a certain diffidence concerning logical representations and denotational semantics. The relevant semantics of language is said to be the transduction from linguistic utterances to internal representations, and the relevant semantics of the internal representations is said to be the way they are deployed in understanding and thought. For both the external language and the internal (mentalese) representation, it is said to be irrelevant whether or not the semantic framework provides formal truth conditions for them. The rejection of logical semantics has sometimes been summarized in the dictum that one cannot compute with possible worlds.
However, it seems that any perceived conflict between conceptual semantics and logical semantics can be resolved by noting that these two brands of semantics are quite different enterprises with quite different purposes. Certainly it is entirely appropriate for conceptual semantics to focus on the mapping from language to symbolic structures (in the head, realized ultimately in terms of neural assemblies or circuits of some sort), and on the functioning of these structures in understanding and thought. But logical semantics, as well, has a legitimate role to play, both in considering how words (and larger linguistic expressions) relate to the world and how the symbols and expressions of the internal semantic representation relate to the world. This role is metatheoretic in that the goal is not to posit cognitive entities that can be computationally manipulated, but rather to provide a framework for theorizing about the relationship between the symbols people use, externally in language and internally in their thinking, and the world in which they live. It is surely undeniable that utterances are at least sometimes intended to be understood as claims about things, properties, and relationships in the world, and as such are at least sometimes true or false. It would be hard to understand how language and thought could have evolved as useful means for coping with the world, if they were incapable of capturing truths about it.
Moreover, logical semantics shows how certain syntactic manipulations lead from truths to truths regardless of the specific meanings of the symbols involved in these manipulations (and these notions can be extended to uncertain inference, though this remains only very partially understood). Thus, logical semantics provides a basis for assessing the soundness (or otherwise) of inference rules. While human reasoning as well as reasoning in practical AI systems often needs to resort to unsound methods (abduction, default reasoning, Bayesian inference, analogy, etc.), logical semantics nevertheless provides an essential perspective from which to classify and study the properties of such methods. A strong indication that cognitively motivated conceptual representations of language are reconcilable with logically motivated ones is the fact that all proposed conceptual representations have either borrowed deliberately from logic in the first place (in their use of predication, connectives, set-theoretic notions, and sometimes quantifiers) or can be transformed to logical representations without much difficulty, despite being cognitively motivated.
Connectionist approaches
As noted earlier, the 1980s saw the re-emergence of connectionist computational models within mainstream cognitive science theory (e.g., Feldman and Ballard 1982; Rumelhart and McClelland 1986; Gluck and Rumelhart 1990). We have already briefly characterized connectionist models in our discussion of connectionist parsing. But the connectionist paradigm was viewed as applicable not only to specialized functions, but to a broad range of cognitive tasks including recognizing objects in an image, recognizing speech, understanding language, making inferences, and guiding physical behavior. The emphasis was on learning, realized by adjusting the weights of the unit-to-unit connections in a layered neural network, typically by a back-propagation process that distributes credit or blame for a successful or unsuccessful output to the units involved in producing the output (Rumelhart and McClelland 1986).
From one perspective, the renewal of interest in connectionism and neural modeling was a natural step in the endeavor to elaborate abstract notions of cognitive content and functioning to the point where they can make testable contact with brain theory and neuroscience. But it can also be seen as a paradigm shift, to the extent that the focus on subsymbolic processing began to be linked to a growing skepticism concerning higher-level symbolic processing as models of mind, of the sort associated with earlier semantic network-based and rule-based architectures. For example, Ramsay et al. (1991) argued that the demonstrated capacity of connectionist models to perform cognitively interesting tasks undermined the then-prevailing view of the mind as a physical symbol system. But others have continued to defend the essential role of symbolic processing. For example, Anderson (1983, 1993) contended that while theories of symbolic thought need to be grounded in neurally plausible processing, and while subsymbolic processes are well-suited for exploiting the statistical structure of the environment, nevertheless understanding the interaction of these subsymbolic processes required a theory of representation and behavior at the symbolic level.
What would it mean for the semantic content of an utterance to be represented in a neural network, enabling, for example, inferential question-answering? The anti-representationalist (or “eliminativist”) view would be that no particular structures can be or need to be identified as encoding semantic content. The input modifies the activity of the network and the strengths of various connections in a distributed way, such that the subsequent behavior of the network effectively implements inferential question-answering. However, this leaves entirely open how a network would learn this sort of behavior. The most successful neural net experiments have been aimed at mapping input patterns to class labels or to other very restricted sets of outputs, and they have required numerous labeled examples (e.g., thousands of images labeled with the class of the objects depicted) to learn their task. By contrast, humans excel at “one-shot” learning, and can perform complex tasks based on such learning.
A less radical alternative to the eliminativist position, termed the subsymbolic hypothesis, was proposed by Smolensky (1988), to the effect that mental processing cannot be fully and accurately described in terms of symbol manipulation, requiring instead a description at the level of subsymbolic features, where these features are represented in a distributed way in the network. Such a view does not preclude the possibility that assemblies of units in a connectionist system do in fact encode symbols and more complex entities built out of symbols, such as predications and rules. It merely denies that the behavior engendered by these assemblies can be adequately modelled as symbol manipulation. In fact, much of the neural net research over the past two or three decades has sought to understand how neural nets can encode symbolic information (e.g., see Smolensky et al. 1992; Browne and Sun 2001).
Distributed schemes associate a set of units and their activation states with particular symbols or values. For example, Feldman (2006) proposes that concepts are represented by the activity of a cluster of neurons; triples of such clusters representing a concept, a role, and a filler (value) are linked together by triangle nodes to represent simple attributes of objects. Language understanding is treated as a kind of simulation that maps language onto a more concrete domain of physical action or experience, guided by background knowledge in the form of a temporal Bayesian network.
Global schemes encode symbols in overlapping fashion over all units. One possible global scheme is to view the activation states of the units, with each unit generating a real value between −1 and 1, as propositions: State p entails state q (equivalently, p is at least as specific as q) if the activation qi of each unit i in state q satisfies pi ≤ qi ≤ 0, or qi = 0, or 0 ≤ qi ≤ pi depending on whether the activation pi of that unit in state p is negative, zero, or positive respectively. Propositional symbols can then be interpreted in terms of such states, and truth functions in terms of simple max-min operations and sign inversions performed on network states. (See Blutner, 2004; however, Blutner ultimately focuses on a localist scheme in which units represent atomic propositions and connections represent biconditionals.) Holographic neural network schemes (e.g., Manger et al. 1994; Plate 2003) can also be viewed as global; in the simplest cases these use one “giant neuron” that multiplies an input vector whose components are complex numbers by a complex-valued matrix; a component of the resultant complex-valued output vector, written in polar coordinates as reiθ, supplies a classification through the value of θ and a confidence level through the value of r. A distinctive characteristic of such networks is their ability to classify or reconstruct patterns from partial or noisy inputs.
The status of the subsymbolic hypothesis remains an issue for debate and further research. Certainly it is unclear how symbolic approaches could match certain characteristics of neural network approaches, such as their ability to cope with novel instances and their graceful degradation in the face of errors or omissions. On the other hand, some neural network architectures for storing knowledge and performing inference have been shown (or designed) to be closely related to “soft logics” such as fuzzy logic (e.g., Kasabov 1996; Kecman 2001) or “weight-annotated Poole systems” (Blutner 2004), suggesting the possibility that neural network models of cognition may ultimately be characterizable as implementations of such soft logics. Researchers more concerned with practical advances than biologically plausible modeling have also explored the possibility of hybridizing the symbolic and subsymbolic approaches, in order to gain the advantages of both (e.g., Sun 2001). A quite formal example of this, drawing on ideas by Dov Gabbay, is d'Avila Garcez (2004).
Finally, we should comment on the view expressed in some of the cognitive science literature that mental representations of language are primarily imagistic (e.g., Damasio 1994; Humphrey 1992). Certainly there is ample evidence for the reality and significance of mental imagery (Johnson-Laird 1983; Kosslyn 1994). Also creative thought often seems to rely on visualization, as observed early in the 20th century by Poincaré (1913) and Hadamard (1945). But as was previously noted, symbolic and imagistic representations may well coexist and interact synergistically. Moreover, cognitive scientists who explore the human language faculty in detail, such as Steven Pinker (1994, 2007) or any of the representationalist or connectionist researchers cited above, all seem to reach the conclusion that the content derived from language (and the stuff of thought itself) is in large part symbolic—except in the case of the eliminativists who deny representations altogether. It is not hard to see, however, how raw intuition might lead to the meanings-as-images hypothesis. It appears that vivid consciousness is associated mainly with the visual cortex, especially area V1, which is also crucially involved in mental imagery (e.g., Baars 1997: chapter 6). Consequently it is entirely possible that vast amounts of non-imagistic encoding and processing of language go unnoticed, while any evoked imagistic artifacts become part of our conscious experience. Further, the very act of introspecting on what sort of imagery, if any, is evoked by a given sentence may promote construction of imagery and awareness thereof.
3.3 Statistical semantics
In its broadest sense, statistical semantics is concerned with semantic properties of words, phrases, sentences, and texts, engendered by their distributional characteristics in large text corpora. For example, terms such as cheerful, exuberant, and depressed may be considered semantically similar to the extent that they tend to occur flanked by the same (or in turn similar) nearby words. (For some purposes, such as information retrieval, identifying labels of documents may be used as occurrence contexts.) Through careful distinctions among various occurrence contexts, it may also be possible to factor similarity into more specific relations such as synonymy, entailment, and antonymy. One basic difference between (standard) logical semantic relations and relations based on distributional similarity is that the latter are a matter of degree. Further, the underlying abstractions are very different, in that statistical semantics does not relate strings to the world, but only to their contexts of occurrence (a notion similar to, but narrower than, Wittgenstein's notion of meaning as use). However, statistical semantics does admit elegant formalizations. Various concepts of similarity and other semantic relations can be captured in terms of vector algebra, by viewing the occurrence frequencies of an expression as values of the components of a vector, with the components corresponding to the distinct contexts of occurrence. In this way, one arrives at a notion of semantics based on metrics and operators in vector spaces, where vector operators can mimic Boolean operators in various ways (Gärdenfors 2000; Widdows 2004; Clarke 2012).
But how does this bear on meaning representation of natural language sentences and texts? In essence, the representation of sentences in statistical semantics consists of the sentences themselves. The idea that sentences can be used directly, in conjunction with distributional knowledge, as objects enabling inference is a rather recent and surprising one, though it was foreshadowed by many years of work on question answering based on large text corpora. The idea has gained traction as a result of recent efforts to devise statistically based algorithms for determining textual entailment, a program pushed forward by a series of Recognizing Textual Entailment (RTE) Challenges initiated in 2005, organized by the PASCAL Network of Excellence, and more recently by the National Institute of Standards and Technology (NIST). Recognizing textual entailment requires judgments as to whether one given linguistic string entails a second one, in a sense of entailment that accords with human intuitions about what a person would naturally infer (with reliance on knowledge about word meanings, general knowledge such as that any person who works for a branch of a company also works for that company, and occasional well-known specific facts). For example, “John is a fluent French speaker” textually entails “John speaks French”, while “The gastronomic capital of France is Lyon” does not entail that “The capital of France is Lyon”. Some examples are intermediate; e.g., “John was born in France” is considered to heighten the probability that John speaks French, without fully entailing it (Glickman and Dagan 2005). Initial results in the annual competitions were poor (not far above the random guessing mark), but have steadily improved, particularly with the injection of some reasoning based on ontologies and on some general axioms about the meanings of words, word classes, relations, and phrasal patterns (e.g., de Salvo Braz et al. 2005).
It is noteworthy that the conception of sentences as meaning representations echoes Montague's contention that language is logic. Of course, Montague understood “sentences” as unambiguous syntactic trees. But research in textual entailment seems to be moving towards a similar conception, as exemplified in the work of Dagan et al. (2008), where statistical entailment relations are based on syntactic trees, and these are generalized to templates that may replace subtrees by typed variables. Also Clarke (2012) proposes a very general vector-algebraic framework for statistical semantics, where “contexts” for sentences might include (multiple) parses and even (multiple) logical forms for the sentences, and where statistical sentence meanings can be built up compositionally from their proper parts. One way of construing degrees of entailment in this framework is in terms of the entailment probabilities relating each possible logical form of the premise sentence to each possible logical form of the hypothesis in question.
3.4 Which semantics in practice?
Having surveyed three rather different brands of semantics, we are left with the question of which of these brands serves best in computational linguistic practice. It should be clear from what has been said above that the choice of semantic “tool” will depend on the computational goals of the practitioner. If the goal, for example, is to create a dialogue-based problem-solving system for circuit fault diagnosis, emergency response, medical contingencies, or vacation planning, then an approach based on logical (or at least symbolic) representations of the dialogue, underlying intentions, and relevant constraints and knowledge is at present the only viable option. Here it is of less importance whether the symbolic representations are based on some presumed logical semantics for language, or some theory of mental representation—as long as they are representations that can be reasoned with. The most important limitations that disqualify subsymbolic and statistical representations of meaning for such purposes are their very limited inferential reach and response capabilities. They provide classifications or one-shot inferences rather than reasoning chains, and they do not generate plans, justifications, or extended linguistic responses. However, both neural net techniques and statistical techniques can help to improve semantic processing in dialogue systems, for example by disambiguating word senses, or recognizing which of several standard plans is being proposed or followed, on the basis of observed utterances or actions.
On the other hand, if the computational goal is to demonstrate human-like performance in a biologically plausible (or biologically valid!) model of some form of language-related behavior, such as learning to apply words correctly to perceived objects or relationships, or learning to judge concept similarity, or to assess the tone (underlying sentiment) of a discourse segment, then symbolic representations need not play any role in the computational modeling. (However, to the extent that language is symbolic, and is a cognitive phenomenon, subsymbolic theories must ultimately explain how language can come about.) In the case of statistical semantics, practical applications such as question-answering based on large textual resources, retrieval of documents relevant to a query, or machine translation are at present greatly superior to logical systems that attempt to fully understand both the query or text they are confronted with and the knowledge they bring to bear on the task. But some of the trends pointed out above in trying to link subsymbolic and statistical representations with symbolic ones indicate that a gradual convergence of the various approaches to semantics is taking place.
4. Semantic interpretation
4.1 Mapping syntactic trees to logical forms
For the next few paragraphs, we shall take semantic interpretation to refer to the process of deriving meaning representations from a word stream, taking for granted the operation of a prior or concurrent parsing phase. In other words, we are mapping syntactic trees to logical forms (or whatever our meaning representation may be). Thus, unlike interpretation in the sense of assigning external denotations to symbols, this is a form of “syntactic semantics” (Rapaport 1995).
In the heyday of the proceduralist paradigm, semantic interpretation was typically accomplished with sets of rules that matched patterns to parts of syntactic trees and added to or otherwise modified the semantic representations of input sentences. The completed representations might either express facts to be remembered, or might themselves be executable commands, such as formal queries to a database or high-level instructions placing one block on another in a robot's (simulated or real) world.
When it became clear in the early 1980s, however, that syntactic trees could be mapped to semantic representations by using compositional semantic rules associated with phrase structure rules in one-to-one fashion, this approach became broadly favored over pure proceduralist ones. In our earlier discussion in section 3.1) of meaning representations within logicist frameworks, we already foreshadowed the essentials of logical form computation. There we saw sample interpretive rules for a small number of phrase structure rules and vocabulary. The semantic rules, such as NP′ = Det′(N′), clearly indicate how logical forms of lower-level constituents should be combined to yield those of higher-level constituents. In the following figure, the sentence “Thetis loves a mortal” has been interpreted by applying the earlier set of lexical and interpretive rules to the nodes of the phrase structure tree in a bottom-up, left-to-right sweep:
Figure 4: Semantic interpretation of the parse tree of Figure 1
![[a tree. Parent is S-prime =
NP-prime(VP) = ∃z[mortal(z) ∧ loves(z)(Thetis)]. First node is
NP-prime = Name-prime = λPP(Thetis) with a node of Name-prime =
λPP(Thetis) which has a node Thetis (in bold). Second node is
VP-prime = λxNP-prime(λyV-prime(y)(x)) = λx(∃z[mortal(z) ∧
loves(z)(x)]) with first a node of V-prime = loves which has a node
loves (in bold) and with second a node of NP-prime =
Det-prime(N-prime) λQ(∃z[mortal(z) ∧ Q(z)]) which itself has a left
node of Def-prime = λP λQ(∃z[P(z) ∧ Q(z)]) which has a node of a (in
bold) and a right node of N-prime = mortal which has a node of mortal
(in bold)]](fig4.png)
The interpretive rules are repeated at the tree nodes from section 3.1, and the result of applying the combinatory rules (with lambda-conversions where possible) are shown as well. As can be seen, the Montagovian treatment of NPs as second-order predicates leads to some complications, and these are exacerbated when we try to take account of quantifier scope ambiguity. We mentioned Montague's use of multiple parses, the Cooper-storage approach, and the unscoped-quantifier approach to this issue in section 3.1. In the unscoped-quantifier approach, with a relational interpretation of the verb, the respective interpretations of the leaf nodes (words) in Figure 4 would become Thetis, λyλx(loves(x, y), λP <⟨∃P⟩>), and mortal, and S′ at the root would become loves(Thetis, ⟨∃mortal⟩), to be scoped uniquely to (∃x: mortal(x) loves(Thetis, x)). It is easy to see that multiple unscoped quantifiers will give rise to multiple permutations of quantifier order when the quantifiers are brought to the sentence level. Thus we will have multiple readings in sentences such as “Every man loves a certain woman”.
4.2 Subordinating the role of syntax
At this point we should pause to consider some interpretive methods that do not conform with the above very common but not universally employed syntax-driven approach. First, Schank and his collaborators emphasized the role of lexical knowledge, especially primitive actions used in verb decomposition, and knowledge about stereotyped patterns of behavior in the interpretive process, nearly to the exclusion of syntax. For example, a sentence beginning “John went …” would lead to the generation of a ptrans conceptualization (since go is lexically interpreted in terms of ptrans), where John fills the agent role and where a phrase interpretable as a location is expected, as part of the configuration of roles that attach to a ptrans act. If the sentence then continues as “… to the restaurant”, the expectation is confirmed, and at this point instantiation of a restaurant script is triggered, creating expectations about the likely sequence of actions by John and other agents in the restaurant (e.g., Schank and Abelson 1977). These ideas had considerable appeal, and led to unprecedented successes in machine understanding of some paragraph-length stories. Another approach to interpretation that subordinates syntax to semantics is one that employs domain-specific semantic grammars (Brown and Burton 1975). While these resemble context-free syntactic grammars (perhaps procedurally implemented in ATN-like manner), their constituents are chosen to be meaningful in the chosen application domain. For example, an electronics tutoring system might employ categories such as measurement, hypothesis, or transistor instead of NP, and fault-specification or voltage-specification instead of VP. The importance of these approaches lay in their recognition of the fact that knowledge powerfully shapes our ultimate interpretation of text and dialogue, enabling understanding even in the presence of noisy, flawed, and partial linguistic input. Nonetheless, most of the NL understanding community since the 1970s has treated syntactic parsing as an important aspect of the understanding process, in part because modularization of this complex process is thought to be crucial for scalability, and in part because of the very plausible Chomskian contention that human syntactic intuitions operate reliably even in the absence of clear meaning, as in his famous sentence “Colorless green ideas sleep furiously”.
Statistical NLP has only recently begun to be concerned with deriving interpretations usable for inference and question answering (and as pointed out in the previous subsection, some of the literature in this area assumes that the NL text itself can and should be used as the basis for inference). However, there have been some noteworthy efforts to build statistical semantic parsers that learn to produce LFs after training on a corpus of LF-annotated sentences, or a corpus of questions and answers (or other exchanges) where the learning is “grounded” in a database or other supplementary models. We will mention examples of this type of work, and comment on its prospects, in section 8.
4.3 Coping with semantic ambiguity and underspecification
We noted earlier that language is potentially ambiguous at all levels of syntactic structure, and the same is true of semantic content, even for syntactically unambiguous words, phrases and sentences. For example, words like bank, recover, and cool have multiple meanings even as members of the same lexical category; nominal compounds such as ice bucket, ice sculpture, olive oil, or baby oil leave unspecified the underlying relation between the nominals (such as constituency or purpose). At the sentential level, even for a determinate parse there may be quantifier scope ambiguities (“Every man admires a certain woman”—Rosa Parks vs. his mother); and habitual and generic sentences often involve temporal/atemporal ambiguities (“Racehorses are (often) skittish”), among others.
Many techniques have been proposed for dealing with the various sorts of semantic ambiguities, ranging from psychologically motivated principles, to knowledge-based methods, heuristics, and statistical approaches. Psychologically motivated principles are exemplified by Quillian's spreading activation model (described earlier) and the use of selectional preferences in word sense disambiguation. For example, in “The job took five hours,” took might be disambiguated to the sense of taking up time because that sense of the verb prefers a temporal complement, and job might be disambiguated to task (rather than, say, occupation) because of the direct associative link between the concept of a task and its time demands. Examples of knowledge-based disambiguation would be the disambiguation of ice sculpture to a constitutive relation based on the knowledge that sculptures may be carved or constructed from solid materials, or the disambiguation of a man with a hat to a wearing-relation based on the knowledge that a hat is normally worn on the head. (The possible meanings may first be narrowed down using heuristics concerning the limited types of relations typically indicated by nominal compounding or by with-modification.) Heuristic principles used in scope disambiguation include island constraints (quantifiers such as every and most cannot expand their scope beyond their local clause) and differing wide-scoping tendencies for different quantifiers (e.g., each is apt to assume wider scope than some). Statistical approaches typically extract various features in the vicinity of an ambiguous word or phrase that are thought to influence the choice to be made, and then make that choice with a classifier that has been trained on an annotated text corpus. The features used might be particular nearby words or their parts of speech or semantic categories, syntactic dependency relations, morphological features, etc.. Such techniques have the advantage of learnability and robustness, but ultimately will require supplementation with knowledge-based techniques. For example, the correct scoping of quantifiers in contrasting sentence pairs such as
- (4.1)
- Every child at the picnic was roasting a wiener.
- (4.2)
- Every child at the picnic was watching a hot air balloon overhead,
seems to depend on world knowledge in a way unlikely to be captured as a word-level statistical regularity.
Habitual and generic sentences present particularly challenging disambiguation problems, as they may involve temporal/atemporal ambiguities (as noted), and in addition may require augmentation with quantifying adverbs and constraints on quantificational domains missing from the surface form. For example,
- (4.3)
- Racehorses are (often) skittish when they are purebred
without the quantifying adverb often is unambiguously atemporal, ascribing enduring skittishness to purebred racehorses in general. (Thus in general appears to be the implicit default adverbial.) But when the quantifying adverb is present, the sentence admits both an atemporal reading according to which many purebred racehorses are characteristically skittish, as well as a temporal reading to the effect that purebred racehorses in general are subject to frequent episodes of skittishness. If we replace purebred by at the starting gate, then only the episodic reading of skittish remains available, while often may quantify over racehorses, implying that many are habitually skittish at the starting gate, or it may quantify over starting-gate situations, implying that racehorses in general are often skittish in such situations; furthermore, making formal sense of the phrase at the starting gate evidently depends on knowledge about horse racing scenarios.
The interpretive challenges presented by such sentences are (or should be) of great concern in computational linguistics, since much of people's general knowledge about the world is most naturally expressed in the form of generic and habitual sentences. Systematic ways of interpreting and disambiguating such sentences would immediately provide a way of funneling large amounts of knowledge into formal knowledge bases from sources such as lexicons, encyclopedias, and crowd-sourced collections of generic claims such as those in Open Mind Common Sense (e.g., Singh et al. 2002; Lieberman et al. 2004; Havasi et al. 2007). Many theorists assume that the logical forms of such sentences should be tripartite structures with a quantifier that quantifies over objects or situations, a restrictor that limits the quantificational domain, and a nuclear scope (main clause) that makes an assertion about the elements of the domain (e.g., see Carlson 2011; Cohen 2002; or Carlson & Pelletier 1995). The challenge lies in specifying a mapping from surface structure to such a logical form. While many of the principles underlying the ambiguities illustrated above are reasonably well understood, general interpretive algorithms are still lacking. It appears that such algorithms will involve stepwise elaboration of an initially incomplete, ambiguous logical form, rather than a straightforward syntax-semantics transduction, since the features on which the correct formalization depends transcend syntax: They include ones such as Carlson's individual-level/stage-level distinction among verb phrases and his object-level/kind-level distinction among verb arguments (Carlson 1977, 1982), as well as pragmatic features such as the given/new distinction (influenced by phrasal accent), lexical presuppositions, linguistic context, and background knowledge.
5. Making sense of text
The dividing line between semantic interpretation (computing and disambiguating logical forms) and discourse understanding—making sense of text—is a rather arbitrary one. However, heavily context- and knowledge-dependent aspects of the understanding process, such as resolving anaphora, interpreting context-dependent nominal compounds, filling in “missing” material, determining implicit temporal and causal relationships (among other “coherence relations”), interpreting loose or figurative language and certainly, integrating linguistically derived information with preexisting knowledge are generally counted as aspects of discourse processing.
5.1 Dealing with reference and various forms of “missing material”
Language has evolved to convey information as efficiently as possible, and as a result avoids lengthy identifying descriptions and other lengthy phrasings where shorter ones will do. One aspect of this tendency towards “shorthand” is seen in anaphora, the phenomenon of coreference between an earlier, potentially more descriptive NP and a later anaphoric pronoun or definite NP (with a determiner like the or these). (The reverse sequencing, cataphora, is seen occasionally as well.) Coreference is yet another source of ambiguity in language, scarcely noticeable by human language users (except in ambivalent cases such as “When Flight 77 hit the Pentagon's wall, it disintegrated”), but problematic for machines.
Determining the (co)referents of anaphors can be approached in a variety of ways, as in the case of semantic disambiguation. Linguistic and psycholinguistic principles that have been proposed include gender and number agreement of coreferential terms, C-command principles (e.g., an anaphor must be a pronoun if its referent is a sibling of one of its ancestors in the parse tree), (non)reflexive constraints (e.g., the subject and object cannot be coreferential in a simple clause such as “John blamed him for the accident”), recency/salience (more recent/salient referents are preferred), and centering (the most likely term to be pronominalized in an utterance is the “center of attention”). An early heuristic algorithm that employed several features of this type to interpret anaphors was that of Hobbs (1979). But selectional preferences are important as well. For example, in the sentence “He bumped against the sauce boat containing the raspberry syrup, spilling it,” the pronoun can be determined to be coreferential with the raspberry syrup rather than the sauce boat because spill prefers a liquid (or loose aggregate) as its object. With the alternative continuation, “… knocking it over,” the choice of coreferent would be reversed, because knock over prefers something solid and upright as its object. More subtle world knowledge may be involved as well, as in Terry Winograd's well-known example, “The city council refused the women a parade permit because they feared/advocated violence,” where they may refer to the city council or the women, depending on the choice of verb and the corresponding stereotypes that are evoked. Another complication concerns reference to collections of entities, related entities (such as parts), propositions, and events that can become referents of pronouns (such as they, this, and that) or of definite NPs (such as this situation or the door (of the house)) without having appeared explicitly as a noun phrase. Like other sorts of ambiguity, coreference ambiguity has been tackled with statistical techniques. These typically take into account factors like those mentioned, along with additional features such as antecedent animacy and prior frequency of occurrence, and use these as probabilistic evidence in making a choice of antecedent (e.g., Haghighi & Klein 2010). Parameters of the model are learned from a corpus annotated with coreference relations and the requisite syntactic analyses.
Coming back briefly to nominal compounds of form N N, note that unlike conventional compounds such as ice bucket or ice sculpture—ones approachable using an enriched lexicon, heuristic rules, or statistical techniques—some compounds can acquire a variety of meanings as a function of context. For example, rabbit guy could refer to entirely different things in a story about a fellow wearing a rabbit suit, or one about a rabbit breeder, or one about large intelligent leporids from outer space. Such examples reveal certain parallels between compound nominal interpretation and anaphora resolution: At least in the more difficult cases, N N interpretation depends on previously seen material, and on having understood crucial aspects of that previous material (in the current example, the concepts of wearing a rabbit suit, being a breeder of rabbits, or being a rabbit-like creature). In other words N N interpretation, like anaphora resolution, is ultimately knowledge-dependent, whether that knowledge comes from prior text, or from a preexisting store of background knowledge. A strong version of this view is seen in the work of Fan et al. (2009), where it is assumed that in technical contexts, even many seemingly conventional compounds require knowledge-based elaboration. For example, in a chemistry context, HCL solution is assumed to require elaboration into something like: solution whose base is a chemical whose basic structural constituents are HCL molecules. Algorithms are provided (and tested empirically) that search for a relational path (subject to certain general constraints) from the modified N to the modifying N, selecting such a relational path as the meaning of the N N compound. As the authors note, this is essentially a spreading-activation algorithm, and they suggest more general application of this method (see section 5.3 on integrated interpretive methods).
While anaphors and certain nominal compounds can be regarded as abbreviated encodings of semantic content, other forms of “shorthand” leave out semantically essential material altogether, requiring the reader or hearer to fill it in. One pervasive phenomenon of this type is of course ellipsis, as illustrated earlier in sentences (2.5) and (2.6), or by the following examples.
- (5.1)
- Shakespeare made up words, and so can you.
- (5.2)
- Felix is under more pressure than I am.
In (5.1), so is a place-holder for the VP make up words (in an inverted sentence), and (5.2) tacitly contains a final predicate something like under amount x of pressure, where that amount x needs to be related to the (larger) amount of pressure experienced by Felix. Interpreting ellipsis requires filling in of missing material; this can often be found at the surface level as a sequence of consecutive words (as in the gapping and bare ellipsis examples 2.5 and 2.6), but as seen in (5.1) and (5.2), may instead (or in addition) require adaptation of the imported material to fit semantically into the new context. Further complications arise when the imported material contains referring expressions, as in the following variant of (5.2):
- (5.2′)
- Felix is under more pressure from his boss than I am.
Here the missing material may refer either to Felix's boss or my boss (called the strict and sloppy reading respectively), a distinction that can be captured by regarding the logical form of the antecedent VP as containing only one, or two, occurrences of the lambda-abstracted subject variable, i.e., schematically,
λx[x is under more pressure from Felix's boss],
versus
λx[x is under more pressure from x's boss].
The two readings can be thought of as resulting respectively from scoping his boss first, then filling in the elided material, and the reverse ordering of these operations (Dalrymple et al. 1991; see also Crouch 1995; Gregory and Lappin 1997). Other challenging forms of ellipsis are event ellipsis, as in (5.3) (where forgot stands for forgot to bring), entirely verbless sentences such as (5.4) and (5.5), and subjectless, verbless ones like (5.6) and (5.7):
- (5.3)
- I forgot the keys
- (5.4)
- Hence this proposal
- (5.5)
- Flights from Rochester to Orlando, May 28?
- (5.6)
- What a pity.
- (5.7)
- How about the Delta flight instead?
In applications these and some other forms of ellipsis are handled, where possible, by (a) making strong use of domain-dependent expectations about the types of information and speech acts that are likely to occur in the discourse, such as requests for flight information in an air travel adviser; and (b) interpreting utterances as providing augmentations or modifications of domain-specific knowledge representations built up so far. Corpus-based approaches to ellipsis have so far focused mainly on identifying instances of VP ellipsis in text, and finding the corresponding antecedent material, as problems separate from that of computing correct logical forms (e.g., see Hardt 1997; Nielsen 2004).
Another refractory missing-material phenomenon is that of implicit arguments. For example, in the sentence
- (5.8)
- Some carbon monoxide leaked into the car from the exhaust, but its concentration was too low to pose any hazard,
the reader needs to conceptually expand its concentration into its concentration in the air in the interior of the car, and hazard into hazard for occupants of the car. In this example, lexical knowledge to the effect that concentration (in the chemical sense) refers to the concentration of some substance in some medium could at least provide the “slots” that need to be filled, and a similar comment applies in the case of hazard. However, not all of the fillers for those slots are made explicitly available by the text—the carbon monoxide referred to provides one of the fillers, but the air in the interior of the car, and potential occupants of the car (and that they rather than, say, the upholstery would be at risk) are a matter of inference from world knowledge.
Finally, another form of shorthand that is common in certain contexts is metonymy, where a term saliently related to an intended referent stands for that referent. For example, in an airport context,
- (5.9)
- Is this flight 574?
might stand for “Is this the departure lounge for flight 574?” Similarly, in appropriate contexts cherry can stand for cherry ice cream, and BMW can stand for BMW's stock market index:
- (5.10)
- I'd like two scoops of cherry.
- (5.11)
- BMW rose 4 points.
Like other types of underspecification, metonymy has been approached both from knowledge-based and corpus-based perspectives. Knowledge that can be brought to bear includes selectional preferences (e.g., companies in general do not literally rise), lexical concept hierarchies (e.g., as provided by WordNet), generic knowledge about the types of metonymy relations commonly encountered, such as part-for-whole, place-for-event, object-for-user, producer-for-product, etc. (Lakoff and Johnson 1980), rules for when to conjecture such relations (e.g., Weischedel and Sondheimer 1983), named-entity knowledge, and knowledge about related entities (e.g., a company may have a stock market index, and this index may rise or fall) (e.g., Bouaud et al. 1996; Onyshkevych 1998). Corpus-based methods (e.g., see Markert and Nissim 2007) often employ many of these knowledge resources, along with linguistic and statistical features such as POS tags, dependency paths and collocations in the vicinity of a potential metonym. As for other facets of the interpretive process (including parsing), use of deep domain knowledge for metonym processing can be quite effective in sufficiently narrow domains, while corpus-based, shallow methods scale better to broader domains, but are apt to reach a performance plateau falling well short of human standards.
5.2 Making connections
Text and spoken language do not consist of isolated sentences, but of connected, interrelated utterances, forming a coherent whole—typically, a temporally and causally structured narrative, a systematic description or explanation, a sequence of instructions, or a structured argument for a conclusion (or in dialogue, as discussed later, question-answer exchanges, requests followed by acknowledgments, mixed-initiative planning, etc.).
This structure is already apparent at the level of pairs of consecutive clauses, such as
- (5.12)
- John looked out at the sky. It was dark with thunderclouds.
- (5.13)
- John looked out at the sky, and decided to take along his umbrella.
In (5.12), we understand that John's looking at the sky temporally overlaps the presence of the dark clouds in the sky (i.e., the dark-cloud situation at least contains the end of the looking event). At a deeper level, we also understand that John perceived the sky to be dark with thunderclouds, and naturally assume that John took the clouds to be harbingers of an impending storm, as we ourselves would. In (5.13), the two clauses appear to report successive events and furthermore, the first event is understood to have led causally to the second—John's decision was driven by whatever he saw upon looking at the sky; and based on our knowledge of weather and the function of umbrellas, and the fact that “everyone” possesses that knowledge, we further infer that John perceived potential rainclouds, and intended to fend off any rain with his umbrella in an imminent excursion.
The examples show that interpreting extended multi-clausal discourses depends on both narrative conventions and world knowledge; (similarly for descriptive, instructional or argumentative text) . In particular, an action sentence followed by a static observation, as in (5.12), typically suggests the kind of action-situation overlap we noted, and successively reported actions or events, as in (5.13), typically suggest temporal sequencing and perhaps a causal connection, especially if one of the two clauses is not a volitional action. These suggestive inferences presumably reflect the narrator's adherence to a Gricean principle of orderliness, though such an observation is little help from a computational perspective. The concrete task is to formulate coherence principles for narrative and other forms of discourses and to elucidate, in a usable form, the particular syntactico-semantic properties at various levels of granularity that contribute to coherence.
Thus various types of rhetorical or coherence relations (between clauses or larger discourse segments) have been proposed in the literature, e.g., by Hobbs (1979), Grosz & Sidner (1986), and Mann & Thompson (1988). Proposed coherence relations are ones like elaboration, exemplification, parallelism, and contrast. We defer further discussion of rhetorical structure to section 6 (on language generation).
5.3 Dealing with figurative language
“[I'm] behind the eight ball, ahead of the curve, riding the wave, dodging the bullet and pushing the envelope. I'm on point, on task, on message and off drugs… I'm in the moment, on the edge, over the top and under the radar. A high-concept, low-profile, medium-range ballistic missionary.” –George Carlin (“Life is worth losing”, first broadcast on HBO, November 5, 2005)
We have already commented on processing metonymy, which is conventionally counted as a figure of speech—a word or phrase standing for something other than its literal meaning. However, while metonymy is essentially an abridging device, other figurative modes, such as metaphor, simile, idioms, irony, personification, or hyperbole (overstatement) convey meanings, especially connotative ones, not easily conveyed in other ways. We focus on metaphor here, as it is in a sense a more general form of several other tropes. Moreover, it has received the most attention from computational linguists, because the argument can be made that metaphor pervades language, with no sharp demarcation between literal and metaphorical usage (e.g., Wilks 1978; Carbonell 1980; Lakoff and Johnson 1980; Barnden 2006). For example, while “The temperature dropped” can be viewed as involving a sense of drop that is synonymous with decrease, it can also be viewed as a conventional metaphor comparing the decreasing temperature to a falling object. As a way of allowing for examples of this type, Wilks offered a processing paradigm in which selectional constraints (such as a physical-object constraint on the subject of drop) are treated as mere preferences rather than firm requirements.
However, processing metaphor requires more than relaxation of preferences; it is both context-dependent and profoundly knowledge-dependent. For example,
- (5.14)
- He threw in the towel
can be a literal description of a mundane act in a laundromat setting, a literal description of a symbolic act by a boxer's handler, or a stock metaphor for conceding defeat in any difficult endeavor. But to grasp the metaphorical meaning fully, including the connotation of a punishing, doomed struggle, requires a vivid conception of what a boxing match is like.
In approaching metaphor computationally, some authors, e.g., Dedre Gentner (see Falkenhainer et al. 1989), have viewed it as depending on shared properties and relational structure (while allowing for discordant ones), directly attached to the concepts being compared. For example, in comparing an atom to the solar system, we observe a revolves-around relation between electrons and the nucleus on the one hand and between planets and the sun on the other. But others have pointed out that the implicit comparison may hinge on properties reached only indirectly. In this view, finding a metaphor for a concept is a process of moving away from the original concept in a knowledge network in a series of steps, each of which transforms some current characteristic into a related one. This is the process termed “slippage” by Hofstadter et al. (1995). Others (e.g., Martin 1990, drawing on Lakoff and Johnson 1980) emphasize preexisting knowledge of conventional ways of bridging metaphorically from one concept to another, such as casting a nonliving thing as a living thing.
In view of the dependence of metaphor on context and extensive knowledge, and the myriad difficulties still confronting all aspects of language understanding, it is not surprising that no general system for processing metaphor in context exists, let alone for using metaphor creatively. Still, Martin's MIDAS program was able to interpret a variety of metaphors in the context of a language-based Unix adviser, relying on knowledge about the domain and about metaphorical mapping, hand-coded in the KODIAK knowledge representation language. Also, several other programs have demonstrated a capacity to analyze or generate various examples of metaphors, including the Structure Mapping Engine (SME) (Falkenhainer et al. 1989), Met* (Fass 1991), ATT-Meta (Barnden 2001), KARMA (Narayanan 1997) and others. More recently, Veale and Hao (2008) undertook an empirical study of a slippage-based approach to metaphor, using attributes collected from WordNet and the web. In a similar spirit, but taking SME as his inspiration, Turney (2008) implemented a “Latent Relation Mapping Engine” (LRME) to find the best mapping between the elements of two potentially comparable descriptions (of equal size); the idea is to use web-based co-occurrence statistics to gauge not only the attribute similarity of any two given concepts (such as electron and planet) but also the relational similarity of any two given pairs of concepts (such as electron:nucleus and planet:sun), using these as metrics in optimizing the mapping.
5.4 Integrated methods
Obviously, the many forms of syntactic, semantic, and pragmatic ambiguity and underspecification enumerated in the preceding sections interact with one another and with world knowledge. For example, word sense disambiguation, reference resolution, and metaphor interpretation are interdependent in the sentence
- (5.15)
- The Nebraska Supreme Court threw out the chair because it deemed electrocution to be a cruel form of capital punishment.
Note first of all that it could refer syntactically to the Nebraska Supreme Court or to the chair, but world knowledge rules out the possibility of a neuter-gendered chair manifesting a mental attitude. Note as well that if it is replaced by he, then the chair is reinterpreted as a person and becomes the referent of the pronoun; at the same time, threw out is then reconstrued as a metaphor meaning removed from office (with an implication of ruthlessness).
Thus it seems essential to find a uniform framework for jointly resolving all forms of ambiguity and underspecification, at least to the extent that their resolution impacts inference. Some frameworks that have been proposed are weighted abduction, constraint solving, and “loose-speak” interpretation. Weighted abduction (Hobbs et al. 1993) is based on the idea that the task of the hearer or reader is to explain the word sequence comprising a sentence by viewing the meaning of that sentence as a logical consequence of general and contextual knowledge along with some assumptions, to be kept as “lightweight” as possible. The constraint-solving approach views syntax, semantics, pragmatics, context, and world knowledge as supplying constraints on interpretations that need to be satisfied simultaneously. Often constraints are treated as defeasible, or ranked, in which case the goal is to minimize constraint violations, particularly of relatively strong constraints. (There is a connection here to Optimality Theory in cognitive language modeling.) Loose-speak interpretation (Fan et al. 2009, cited previously in connection with nominal compound interpretation) sets aside syntactic ambiguity but tries to deal with pervasive semantic looseness in the meanings of nominal compounds, metonymy, and other linguistic devices. It does so by expanding semantic triples (from the preliminary logical form) of type ⟨Class1, relation, Class2⟩, where the relation cannot properly relate the specified classes, into longer chains containing that relation and terminating at those classes. Finding such chains depends on background knowledge about the relations that are possible in the domain of interest.
Prospects
The methods just mentioned have been applied in restricted tasks, but have not solved the problem of comprehensive language interpretation. They all face efficiency problems, and—since they all depend on a rich base of linguistic and world knowledge—the knowledge acquisition bottleneck. We comment on the efficiency issue here, but leave the discussion of knowledge acquisition to section 8.
In view of the speed with which people disambiguate and comprehend language, one may surmise that these processes more closely resemble fitting the observed texts or utterances to familiar patterns, than solving complex inference or constraint satisfaction problems. For example, in a sentence such as
- (5.16)
- He dropped the cutting board on the glass and it didn't break,
the pronoun is understood to refer to the glass, even though world knowledge would predict that the glass broke, whereas the cutting board did not. (The idea that communication focuses on the unexpected is of no help here, because the referent remains unchanged if we change didn't break to broke.) This would be expected if the interpretive process simply found a match between the concept of a fragile object breaking and the glass breaking (regardless of the exact logical structure), and used that match in choosing a referent. The processing of the example from Winograd, in section 5.1, concerning refusal of a parade permit to a group of women, may similarly depend in part on the familiarity of the idea that people who (seek to) parade may advocate some cause. Note that in
- (5.17)
- The city council granted the women a parade permit because they did not advocate violence
the women are still preferred as the referent of they, even though it is generally true that stalwarts of society, such as city councillors, do not advocate violence.
If disambiguation and (at least preliminary) interpretation in language understanding turn out to be processes guided more by learned patterns than by formalized knowledge, then methods similar to those used in feature-based statistical NLP may be applicable to their effective mechanization.
6. Language generation
Because language generation is a purposeful activity motivated by internal goals, it is difficult to draw a boundary between goal-directed thinking and the ensuing production of linguistic output. Often the process is divided into content planning, microplanning, surface realization, and physical presentation. While the last three of these stages can be thought of as operating (in the order stated) on relatively small chunks of information (e.g., resulting in one or two sentences or other utterance types), content planning is often regarded as a continual process of goal-directed communicative planning, which successively hands over small clusters of ideas to the remaining stages for actual generation when appropriate. We discuss the latter transduction first, in order to highlight its relationship to understanding.
The transduction of a small set of internally represented ideas into written or oral text is in an obvious sense the inverse of the understanding process, as we have outlined it in the preceding sections 2–5. In other words, starting from a few internally represented ideas to be communicated, we need to proceed to an orderly linear arrangement of these ideas, to a surface-oriented logical form that is concise and nonrepetitive and appropriately indexical (e.g., in the use of I, you, here, now, and referring expressions), and finally to an actual surface realization and physical presentation of that realization as spoken or written text. Most or all of the kinds of knowledge involved in understanding naturally come into play in generation as well—whether the knowledge is about the structure of words and phrases, about the relationship between structure and meaning representation, about conventional (or creative) ways of phrasing ideas, about discourse structure and relations, or about the world.
Despite this inverse relationship, language generation has traditionally received less attention from computational linguists than language understanding, because if the content to be verbalized is available in an unambiguous, formal representation, standard output templates can often be used for generation, at least in sufficiently narrow domains. Even for unrestricted domains, the transduction from an explicit, unambiguous internal semantic representation to a word sequence is much less problematic than reconstruction of an explicit semantic representation from an ambiguous word sequence. A similar asymmetry holds at the level of speech recognition and generation, accounting for the fact that serviceable speech generators (e.g., reading machines for the blind) have been available much longer (since about 1976) than serviceable speech recognizers (appearing around 1999).
The microplanning process that leads from a few internal ideas to a surface-oriented, indexical representation typically starts by identifying “chunks” expected to be verbalized as particular types of syntactic constituents, such as NPs, VPs or PPs. This is often followed by making choices of more surface-oriented concepts (or directly, lexical heads) in terms of which the chunks will be expressed. The nature of these processes depends very much on the internal representation. For example, if the representation is framed in terms of very abstract primitives, thematic relations, and attribute-value descriptions of entities, then the chunks might be sets of thematic relations centered around an action, and sets of salient attributes of entities to be referred to. If the internal representation is instead more language-like, then chunks will be relatively small, often single propositions, and the lexical choice process will resemble internal paraphrasing of the logical forms. If more than one idea is being verbalized, ordering decisions will need to be made. For example, reporting that a bandit brandishing a gun entered a local liquor store might be reported in that order, or as “A bandit entered a local liquor store, brandishing a gun”. In dialogue, if a contribution involves both supplying and requesting information, the request should come last. In other cases transformations to more concise forms may be needed to bring the represented ideas stylistically closer to surface form. For example, from logical forms expressing that John ate a burrito containing chicken meat and Mary ate a burrito containing chicken meat, a more compact surface-oriented LF might be generated to the effect that John and Mary each had a chicken burrito. More subtle stylistic choices might be made as well—for example, in casual discourse, eating might be described as polishing off (assuming that the internal representation allows for such surface-oriented distinctions). Furthermore, as already mentioned, a surface-oriented LF needs to introduce contextually appropriate referring expressions such as definite descriptions and pronouns, in conformity with pragmatic constraints on the usage of such expressions.
The above outline is simplified in that it neglects certain subtleties of discourse and context. A sentence or other utterance type generally involves both new and old (given, presupposed) information, and furthermore, some of the concepts involved may be more strongly focused than others. For example, in the sentence “The item you ordered costs ninety dollars, not nine,” the existence and identity of the item, and the fact that it was ordered, are presumed to be part of the common ground in the current context (old), and so is the addressee's belief that the cost of the item is $9; only the corrected cost of $90 is new information. The emphasis on ninety draws attention to the part of the presumed belief that is being corrected. Thus it is not only conceptual content that needs to be available to the microplanning stage, but also indications as to what is new and what is old, and what aspects are to be stressed or focused. The planner needs at least to apply knowledge about the phrasing of new and old information (e.g., the use of indefinite vs. definite NPs), about the lexical presuppositions and implicatures of the items used (e.g., that succeeding presupposes trying, that regretting that φ presupposes that φ, or that some implicates not all), about the presuppositions of stress patterns, and about focusing devices (such as stress and topicalization). The effect of applying these sorts of pragmatic knowledge will be to appropriately configure the surface-oriented LFs that are handed off to the surface realizer, or, for pragmatic features that cannot be incorporated into the LFs, to annotate the LFs with these features (e.g., stress marking).
The penultimate step is surface realization, using knowledge about the syntax-semantics interface. In systems for restricted domains, this knowledge might consist of heuristic rules and templates (perhaps tree schemas) for verbalizing LFs. More broadly-aimed generators might make use of invertible grammars, ones formulated in rule-to-rule fashion and allowing transduction from logical forms to surface forms in much the same way as the “forward” transduction from surface phrase structure to logical form. Sophisticated generators also need to take account of pragmatic annotations, such as stress, mentioned above. Finally, the linguistically expressed content needs to be physically presented as spoken or written text, with due attention to articulation, stress, and intonation, or, for written text, punctuation, capitalization, choice of a or an as indefinite article, italics, line breaks, and so on.
Returning now to content planning, this process may be expansive or very limited in scope; for example, it may be aimed at providing details of a complex object, set of events, or argument, or it may seek to present no more than a single fact, greeting or acknowledgment. We leave discussion of the strongly interactive type of content planning needed for dialogue to the following section, while we comment here on the more expansive sorts of text generation. In this case the organization of the information to be presented is the central concern. For example, the events of a narrative or the steps of a procedure would generally be arranged chronologically; arguments for a conclusion might be arranged so that any subarguments intended to buttress the presumptions of that step (immediately) precede it; descriptions of objects might proceed from major characteristics and parts to details.
An early method of producing well-organized, paragraph-length descriptions and comparisons was pioneered in the TEXT system of McKeown (1985), which used ATN-like organizational schemas to sequence sections of the description of a type of object, such as the object's more general type, its major parts and distinctive attributes, and illustrative examples. Later work by Hovy (1988) and Moore and Paris (1988) tied content planning more closely to communicative goals by relying on rhetorical structure theory (RST) (Mann and Thompson 1987). RST posits over 20 possible coherence relations between spans of text (usually adjacent). For example, a statement of some claim may be followed by putative evidence for the claim, thus establishing an evidence relation between the claim (called the nucleus, because it is the main point) and the cited evidence (called a satellite because of its subsidiary role). Another example is the volitional result relation, where the nuclear text span describes a situation or event of interest, and the satellite describes a deliberate action that caused the situation or event. Often these relations are signalled by discourse markers (cue words and phrases), such as but, when, yet, or after all, and it is important in text generation to use these markers appropriately. For example, the use of when in the following sentence enhances coherence,
- (6.1)
- John hung up the phone when the caller asked for his social security number,
by signalling a possible volitional result relation. Text spans linked by rhetorical relations may consist of single or multiple sentences, potentially leading to a recursive (though not necessarily strictly nested) structure. Rhetorical relations can serve communicative goals such as concept comprehension (e.g., via elaboration of a definition), belief (via presentation of evidence), or causal understanding (e.g., via a volitional result relation, as in (6.1)), and in this way tighten the connection between content planning and communicative goals.
7. Making sense of, and engaging in, dialogue
“We can ask just how it is that rhetoric somehow moves us … Aristotle locates the essential nature of rhetorical undertakings in the ends sought rather than in the purely formal properties.” –Daniel N. Robinson, Consciousness and Mental Life, (2007: 171–2)
Dialogue is interactive goal-directed (purposive) behavior, and in that sense the most natural form of language. More than in narrative or descriptive language, the flow of surface utterances and speaker alternation reflect the interplay of underlying speaker goals and intentions. By themselves, however, utterances in a dialogue are ambiguous as to their purpose, and an understanding of the discourse context and the domain of discourse are required to formulate or understand them. For example,
- (7.1)
- Do you know what day this is?
could be understood as a request for an answer such as “Thursday, June 24”, as a reminder of the importance of the day, or as a test of the addressee's mental alertness.
The immediate goal of such an utterance is to change the mental state (especially beliefs, desires and intentions) of the hearer(s), and speech act theory concerns the way in which particular types of speech acts effect such changes, directly or indirectly (Austin 1962; Grice 1968; Searle 1969). To choose speech acts sensibly, each participant also needs to take account of the mental state of the other(s); in particular, each needs to recognize the other's beliefs, desires and intentions. Discourse conventions in cooperative conversation are adapted to facilitate this process: The speakers employ locutions that reveal their intended effects, and their acknowledgments and turn-taking consolidate mutual understanding. In this way mixed-initiative dialogue and potentially, cooperative domain action are achieved.
In the previous discussion of content planning in language generation, we said little about the formation of communicative intentions in this process. But in the context of purposive dialogue, it is essential to consider how a dialogue agent might arrive at the intention to convey certain ideas, such as episodic, instructional or descriptive information, a request, an acknowledgment and/or acceptance of a request, an answer to a question, an argument in support of a conclusion, etc.
As in the case of generating extended descriptions, narrative, arguments, etc., using RST, a natural perspective here is one centered around goal-directed planning. In fact, the application of this perspective to dialogue historically preceded its application to extended discourses. In particular, Cohen and Perreault (1979) proposed a reasoning, planning, and plan recognition framework that represents speech acts in terms of their preconditions and effects. For example, a simple INFORM speech act might have the following preconditions (formulated for understandability from a first-person speaker perspective):
- The hearer (my dialogue partner) does not know whether a certain proposition X is true;
- the hearer wants to be told by me whether X is true; and
- I do in fact know whether X is true.
The effect of implementing the INFORM as an utterance is then that the hearer knows whether X is true. An important feature of such a framework is that it can account for indirect speech acts (Allen and Perreault 1980). For example, question (7.1), as an indirect request for the date or day of the week, can be viewed as indicating the speaker's awareness that the hearer can perform the requested information-conveying act only if the knowledge-precondition of that act is satisfied. Furthermore, since the hearer recognizes that questioning a precondition of a potential act is one indirect way of requesting the act, then (unless the context provides evidence to the contrary) the hearer will make the inference that the speaker wants the hearer to perform the information-conveying speech act. Note that the reasoning and planning framework must allow for iterated modalities such as “I believe that you want me to tell you what today's date is”, or “I believe (because of the request I just made) that you know that I want you to pass the salt shaker to me”. Importantly, there must also be allowance for mutual beliefs and intentions, so that a common ground can be maintained as part of the context and collaboration can take place. A belief is mutual if each participant holds the belief, and the participants mutually believe that they mutually hold the belief. The mutual knowledge of the participants in a dialogue can be assumed to include the overt contents of their utterances and common general knowledge, including knowledge of discourse conventions.
Since the ultimate purpose of a dialogue may be to accomplish something in the world, not only in the minds of the participants, reasoning, goal-directed planning, and action need to occur at the domain level as well. The goals of speech acts are then not ends in themselves, but means to other ends in the domain, perhaps to be accomplished by physical action (such as equipment repair). As a result, task-oriented dialogues are apt to be structured in a way that follows or “echoes” the structure of the domain entities and the way they can be purposefully acted upon. Such considerations led to Grosz and Sidner's theory of dialogue structure in task-oriented dialogues (Grosz and Sidner 1986). Their theory centers around the idea of shifts of attention mediated by pushing and popping of “focus spaces” on a stack. Focus spaces hold in them structured representations of the domain actions under consideration. For example, setting a collaborative goal of attaching a part to some device would push a corresponding focus space onto the stack. As dictated by knowledge about the physical task, the participants might next verbally commit to the steps of using a screwdriver and some screws to achieve the goal, and this part of the dialogue would be mediated by pushing corresponding subspaces onto the focus stack. When a subtask is achieved, the corresponding focus space is popped from the stack.
Implementation of reasoning and planning frameworks covering both the iterated modalities needed for plan-based dialogue behavior and the realities of a task domain has proved feasible for constrained dialogues in restricted domains (e.g., Smith et al. 1995), but quickly comes up against a complexity barrier when the coverage of language and the scope of the domain of discourse are enlarged. Planning is in general NP-hard, indeed PSPACE-complete even in propositional planning formalisms (Bylander 1994), and plan recognition can be exponential in the number of goals to be recognized, even if all plans available for achieving the goals are known in advance (Geib 2004).
In response to this difficulty, researchers striving to build usable systems have experimented with a variety of strategies. One is to pre-equip the dialogue system with a hierarchy of carefully engineered plans suitable for the type of dialogue to be handled (such as tutoring, repair, travel planning or schedule maintenance), and to choose the logical vocabulary employed in NLU/NLG so that it meshes smoothly with both the planning operators and with the surface realization schemas aimed at the target domain. (As a noteworthy example of this genre, see Moore & Paris 1993.) In this way domain and text planning and surface realization become relatively straightforward, at least in comparison with systems that attempt to synthesize plans from scratch, or to reason extensively about the world, the interlocutor, the context, and the best way to express an idea at the surface level. But while such an approach is entirely defensible for an experimental system intended to illustrate the role of plans and intentions in a specialized domain, it leaves open the question of how large amounts of linguistic knowledge and world knowledge could be incorporated into a dialogue system, and used inferentially in planning communicative (and other) actions.
Another strategy for achieving more nearly practical performance has been to precode (and to some extent learn) more “reactive” (as opposed to deliberative) ways of participating in dialogue. Reactive techniques include (i) formulaic, schema-based responses (reminiscent of ELIZA) where such responses are likely to be appropriate; (ii) rule-based intention and plan recognition; e.g., an automated travel agent confronted with the elliptical input “Flights to Orlando” can usually assume that the user wishes to be provided with flight options from the user's current city to Orlando, in a time frame that may have been established previously; (iii) statistical domain plan recognition based on probabilistic modeling of the sequences of steps typically taken in pursuit of the goals characteristic of the domain; and (iv) discourse state modeling by classifying speech acts (or utterance acts) and dialogue states into relatively small numbers of types, and viewing transitions between dialogue states as events determined by the current state and current type of speech act. For example, in a state where the dialogue system has no immediate obligation, and the user asks a question, the system assumes the obligation of answering the question, and transitions to a state where it will try to discharge that obligation.
However, systems that rely primarily on reactive techniques tend to lack deep understanding and behavioral flexibility. Essentially, knowledge-based inference and planning are replaced by rote behavior, conditioned by miscellaneous features of the current discourse state and observations in the world. Furthermore, deliberate reasoning and plan synthesis seem necessary for an agent that can acquire effective goal-directed plans and behaviors autonomously. Although random trial and error (as in reinforcement learning), supervised learning, and learning by imitation are other learning options, their potential is limited. Random trial and error is apt to be impractical in the enormously large state space of linguistic and commonsense behavior; supervised learning (of appropriate choices based on contextual features) seems at best able to induce rote plan recognition and discourse state transitions (reactive behaviors of types (iii) and (iv) above); and imitation is possible only when relevant, readily observable exemplary behaviors can be presented to the learner—and by itself, it can lead only to rote, rather than reasoned, behavior.
Integrating reactive methods with deliberate reasoning and planning may be enabled in future by treating intentions and actions arrived at by reactive methods as tentative, to be verified and potentially modified by more deliberate reasoning if time permits. Excessive reasoning with iterated modalities could also be avoided with stronger assumptions about the attainment of mutual belief. For example, we might assume that both speaker and hearer spontaneously perform forward inferences about the world and about each other's mental states based on discourse events and common knowledge, and that such forward inferences directly become mutual knowledge (on a “likemindedness” assumption), thus shortcutting many modally nested inferences.
8. Acquiring knowledge for language
We have noted the dependence of language understanding and use on vast amounts of shallow and deep knowledge, about the world, about lexical and phrasal meaning, and about discourse and dialogue structure and conventions. If machines are to become linguistically competent, we need to impart this knowledge to them.
Ideally, the initial, preprogrammed knowledge of a machine would be restricted to the kinds of human knowledge thought to be innate (e.g., object persistence, motion continuity, basic models of animacy and mind, linguistic universals, means of classifying/taxonomizing the world, of organizing events in time, of abstracting from experience, and other such knowledge and know-how). The rest would be learned in human-like fashion. Unfortunately, we do not have embodied agents with human-like sensory and motor equipment or human-like innate mental capabilities; so apart from the simplest sort of verbal learning by robots such as verbal labeling of objects or actions, or using spatial prepositions or two-word sentences (e.g., Fleischman and Roy 2005; McClain and Levinson 2007; Cour et al. 2008), most current work on knowledge acquisition uses either (1) hand-coding, (2) knowledge extraction from text corpora, or (3) crowdsourcing coupled with some method of converting collected, verbally expressed “facts” to a usable format. We focus in this section on the acquisition of general background knowledge needed to support language understanding and production, leaving discussion of linguistic knowledge acquisition to section 9.
8.1 Manual knowledge encoding
The best-known manually created body of commonsense knowledge is the Cyc or ResearchCyc knowledge base (KB) (Lenat 1995). This contains an ontology of a few hundred thousand concepts and several million facts and rules, backed up by an inference engine. It has been applied to analysis, decision support and other types of projects in business, education and military domains. However, the Cyc ontology and KB contents have been motivated primarily by knowledge engineering considerations (often for specific projects) rather than by application to language understanding, and this is reflected in its heavy reliance on very specific predicates expressed as concatenations of English words, and on higher-order operators. For example, the relation between killing and dying is expressed using the predicates lastSubEvents, KillingByOrganism-Unique, and Dying, and relies on a higher-order relation relationAllExists that can be expanded into a quantified conditional statement. This remoteness from language makes it difficult to apply the Cyc KB to language understanding, especially if the goal is to extract relevant concepts and axioms from this KB and integrate them with concepts and axioms formalized in a more linguistically oriented representation (as opposed to adopting the CycL language, Cyc KB, axioms about English, and inference mechanisms wholesale) (e.g., Conesa et al. 2010).
Other examples of hand-coded knowledge bases are the Component Library (CLib) (Barker et al. 2001), and a collection of commonsense psychological axioms by Hobbs and Gordon (2005). CLib provides a broad upper (i.e., high-level) ontology of several hundred concepts, and axioms about basic actions (conveying, entering, breaking, etc.) and resultant change. However, the frame-based Kleo knowledge representation used in CLib is not close to language, and the coverage of the English lexicon is sparse. The psychological axioms of Hobbs and Gordon are naturally narrow in focus (memories, beliefs, plans, and goals), and it remains to be seen whether they can be used effectively in conjunction with language-derived logical forms (of the “flat” type favored by Hobbs) for inference in discourse contexts.
Knowledge adaptation from semi-formalized sources can, for example, consist of extracting part-of-speech and subcategorization information as well as stock phrases and idioms from appropriate dictionaries. It may also involve mapping hypernym hierarchies, meronyms (parts), or antonyms, as catalogued in sources like WordNet, into some form usable for disambiguation and inference. The main limitations of manually coded lexical knowledge are its grounding in linguistic intuitions without direct consideration of its role in language understanding, and its inevitable incompleteness, given the ever-expanding and shifting vocabulary, jargon, and styles of expression in all living languages.
Besides these sources of lexical knowledge, there are also sources of world knowledge in semi-formalized form, such as tabulations and gazetteers of various sorts, and “info boxes” in online knowledge resources such as Wikipedia (e.g., the entries for notable personages contain a box with summary attributes such as date of birth, date of death, residence, citizenship, ethnicity, fields of endeavor, awards, and others). But to the extent that such sources provide knowledge in a regimented, and thus easily harvested form, they do so only for named entities (such as people, organizations, places, and movies) and a few entity types (such as biological species and chemical compounds). Moreover, much of our knowledge about ordinary concepts, such as that of a tree or that of driving a car, is not easily captured in the form of attribute-value pairs, and is generally not available in that form.
8.2 Knowledge extraction from text
Knowledge extraction from unconstrained text has in recent years been referred to as learning by reading. The extraction method may be either direct or indirect. A direct method takes sentential information from some reliable source, such as word sense glosses in WordNet or descriptive and narrative text in encyclopedias such as Wikipedia, and maps this information into a (more) formal syntax for expressing generic knowledge. Indirect methods abstract (more or less) formal generic knowledge from the patterns of language found in miscellaneous reports, stories, essays, weblogs, etc.
Reliably extracting knowledge by the direct method requires relatively deep language understanding, and consequently is far from a mature technology. Ide and Véronis (1994) provide a survey of early work on deriving knowledge from dictionary definitions, and the difficulties faced by that enterprise. For the most part knowledge obtained in this way to date has been either low in quantity or in quality (from an inference perspective). More recent work that shows promise is that of Moldovan and Rus (2001), aimed at interpreting WordNet glosses for nominal artifact concepts, and that of Allen et al. (2013), aimed at forming logical theories of small clusters of related verbs (e.g., sleeping, waking up, etc.) by interpreting their WordNet glosses.
The most actively researched approach to knowledge extraction from text in the last two decades has been the indirect one, beginning with a paper by Marti Hearst demonstrating that hyponymy relations could be rather simply and effectively discovered by the use of lexicosyntactic extraction patterns (Hearst 1992). For example, extraction patterns that look for noun phrases separated by “such as” or “and other” will match word sequences like “seabirds such as penguins and albatrosses” or “beans, nuts, and other legumes”, leading to hypotheses that seabird is a hypernym of penguin and albatross, and that beans and nuts are hyponyms of legumes. By looking for known hyponym-hypernym pairs in close proximity, Hearst was able to expand the initial set of extraction patterns and hence the set of hypotheses. Many variants have been developed since then, with improvements such as automation of the bootstrapping and pattern discovery methods, often with machine learning techniques applied to selection, weighting and combination of local features in the immediate vicinity of the relata of interest. Relations other than hyponymy that have been targeted, of relevance to language understanding, include part-of relations, causal relations, and telic relations (such as that the use of milk is to drink it).
While knowledge extraction using Hearst-like patterns is narrowly aimed at certain predetermined types of knowledge, other approaches are aimed at open information extraction (OIE). These seek to discover a broad range of relational knowledge, in some cases including entailments (in a rather loose sense) between different relations. An early and quite successful system of this genre was Lin and Pantel's DIRT system (Discovery of Inference Rules from Text), which used collocational statistics to build up a database of “inference rules” (Lin and Pantel 2001). An example of a rule might be “X finds a solution to Y ≈ X solves Y.” The statistical techniques used included clustering of nominals into similarity groups based on their tendency to occur in the same argument positions of the same verbs, and finding similar relational phrases (such as “finds a solution to” and “solves”), based their tendency to connect the same, or similar, pairs of nominals. Many of the rules were later refined by addition of type constraints to the variables, obtained by abstracting from particular nominals via WordNet (Pantel et al. 2007).
An approach to OIE designed for maximum speed is exemplified by the TextRunner system (Banko et al. 2007). TextRunner is extraction pattern-based, but rather than employing patterns tuned to a few selected relations, it uses a range of patterns obtained automatically from a syntactically parsed training corpus, weighted via Bayesian machine learning methods to extract miscellaneous relations sentence-by-sentence from text. A rather different approach, termed “open knowledge extraction” (OKE), derives logical forms from parsed sentences, and simplifies and abstracts these so that they will tend to reflect general properties of the world. This is exemplified by the Knext system (KNowledge EXtraction from Text) (e.g., Schubert and Tong 2003). For example, the sentence “I read a very informative book about China” allows KNEXT to abstract “factoids” to the effect that a person may occasionally read a book, and that books may occasionally be informative, and may occasionally be about a country. (Note that the specific references to the speaker and China have been abstracted to classes.) Another interesting development has been the extraction of script-like sequences of relations from large corpora by collocational methods (see Chambers and Jurafsky 2009). For example, the numerous newswire reports about arrest and prosecution of criminals can be mined to abstract typical event types involved, in chronological order, such as arrest, arraignment, plea, trial, and so on. A difficulty in all of this work is that most of the knowledge obtained is too ambiguously and incompletely formulated to provide a basis for inference chaining (but see for example Van Durme et al. 2009; Gordon and Schubert 2010; Schoenmackers et al. 2010).
8.3 Crowdsourcing
The crowdsourcing approach to the acquisition of general knowledge consists of soliciting verbally expressed information, or annotations of such information, from large numbers of web users, sometimes using either small financial rewards or the challenge of participating in simple games as inducements (Havasi et al. 2007; von Ahn 2006). Crowdsourcing has proved quite reliable for simple annotation/classification tasks (e.g., Snow et al. 2008; Hoffmann et al. 2009). However, general knowledge offered by non-expert users is in general much less carefully formulated than, say, encyclopedia entries or word sense glosses in lexicons, and still requires natural language processing if formal statements are to be abstracted. Nevertheless, the Open Mind Common Sense project has produced a relational network of informal commonsense knowledge (ConceptNet), based on simple English statements from worldwide contributors, that proved useful for improving interpretation in speech recognition and other domains (Lieberman et al. 2004; Faaborg et al. 2005).
The overall picture that emerges is that large-scale resources of knowledge for language, whether lexical or about the world, still remain too sparse and too imprecise to allow scaling up of narrow-domain NLU and dialogue systems to broad-coverage understanding. But such knowledge is expected to prove crucial eventually in general language understanding, and so the quest for acquiring this general knowledge remains intensely active.
9. Statistical NLP
“All the thousands of times you've heard clause-final auxiliary verbs uncontracted strengthen the probability that they're not allowed to contract.” –Geoff Pullum (2011)
We have already referred to miscellaneous statistical models and techniques used in various computational tasks, such as (in section 2) HMMs in POS tagging, probabilistic grammar modeling and parsing, statistical semantics, semantic disambiguation (word senses, quantifier scope, etc.), plan recognition, discourse modeling, and knowledge extraction from text. Here we try to provide a brief, but slightly more systematic taxonomy of the types of tasks addressed in statistical NLP, and some sense of the modeling techniques and algorithms that are most commonly used and have made statistical NLP so predominant in recent years, challenging the traditional view of computational linguistics.
This traditional view focuses on deriving meaning, and rests on the assumption that the syntactic, semantic, pragmatic, and world knowledge employed in this derivation is “crisp” as opposed to probabilistic; i.e., the distributional properties of language are a mere byproduct of linguistic communication, rather than an essential factor in language understanding, use, or even learning. Thus the emphasis, in this view, is on formulating nonprobabilistic syntactic, semantic, pragmatic, and KR theories to be deployed in language understanding and use. Of course, the problem of ambiguity has always been a focal issue in building parsers and language understanding systems, but the prevailing assumption was that ambiguity resolution could be accomplished by supplementing the interpretive routines with some carefully formulated heuristics expressing syntactic and semantic preferences.
However, experience has revealed that the ambiguities that afflict the desired mappings are far too numerous, subtle, and interrelated to be amenable to heuristic arbitration. Instead, linguistic phenomena need to be treated as effectively stochastic, and the distributional properties resulting from these stochastic processes need to be systematically exploited to arrive at reasonably reliable hypotheses about underlying structure. (The Geoff Pullum quote above is relevant to this point: The inadmissiblity of contracting the first occurrence of I am to I'm in “I'd rather be hated for who I am, than loved for who I am not” is not easily ascribed to any grammatical principle, yet—based on positive evidence alone—becomes part of our knowledge of English usage.) Thus the emphasis has shifted, at least for the time being, to viewing NLP as a problem of uncertain inference and learning in a stochastic setting.
This shift is significant from a philosophical perspective, not just a practical one: It suggests that traditional thinking about language may have been too reliant on introspection. The limitation of introspection is that very little of what goes on in our brains when we comprehend or think about language is accessible to consciousness (see for example the discussion of “two-channel experiments” in Baars 1997). We consciously register the results of our understanding and thinking, apparently in symbolic form, but not the understanding and thinking processes themselves; and these symbolic abstractions, to the extent that they lack quantitative or probabilistic dimensions, can lead us to suppose that the underlying processing is nonquantitative as well. But the successes of statistical NLP, as well as recent developments in cognitive science (e.g., Fine et al. 2013; Tenenbaum et al. 2011; Chater and Oaksford 2008) suggest that language and thinking are not only symbolic, but deeply quantitative and in particular probabilistic.
For the first twenty years or so, the primary goals in statistical NLP have been to assign labels, label sequences, syntax trees, or translations to linguistic inputs, using statistical language models trained on large corpora of observed language use. More fully, the types of tasks addressed can be grouped roughly as follows (where the appended keywords indicate typical applications):
- text/document classification: authorship, Reuters news category, sentiment analysis;
- classification of selected words or phrases in sentential or broader contexts: word sense disambiguation, named entity recognition, multiword expression recognition;
- sequence labeling: acoustic features → phones → phonemes → words → POS tags;
- structure assignment to sentences: parsing, semantic role labeling, quantifier scoping;
- sentence transduction: MT, LF computation;
- structure assignment to multi-sentence texts: discourse relations, anaphora, plan recognition;
- large-scale relation extraction: knowledge extraction, paraphrase and entailment relations.
These groups may seem to differ haphazardly, but as we will further discuss, certain techniques and distinctions are common to many of them, notably
- in modeling: numeric and discrete features, vector models, log-linear models, Markov models; generative versus discriminative models, parametric versus non-parametric models;
- in learning from data: maximum likelihood estimation, maximum entropy, expectation maximization, dynamic programming; supervised versus unsupervised learning; and
- in output computation: dynamic programming; unique outputs versus distributions over outputs.
We now try to provide some intuitive insight into the most important techniques and distinctions involved in the seven groups of tasks above. For this purpose, we need not comment further on quantifier scoping (in the fourth group) or any of the items in the sixth and seventh groups, as these are for the most part covered elsewhere in this article. In all cases, the two major requirements are the development (aided by learning) of a probabilistic model relating linguistic inputs to desired outputs, and the algorithmic use of the model in assigning labels or structures to previously unseen inputs.
Text and document classification: In classifying substantial documents, the features used might be normalized occurrence frequencies of particular words (or word classes) and punctuation. Especially for shorter texts, various discrete features may be included as well, such as 0, 1-valued functions indicating the presence or absence of certain key words or structural features. In this way documents are represented as numerical vectors, with values in a high-dimensional space, with separate classes presumably forming somewhat separate clusters in that space. A variety of classical pattern recognition techniques are applicable to the problem of learning to assign new documents (as vectors) to the appropriate class (e.g., Sebestyen 1962; Duda and Hart 1973). Perhaps the simplest approach (most easily applied when features are binary) is a naïve Bayesian one, which assumes that each class generates feature values that are independent of one another. The generative frequencies are estimated from the training data, and class membership probabilities for an unknown document (vector) are computed via Bayes' rule (which can be done using successive updates of the prior class probabilities). Choosing the class with the highest resultant posterior probability then provides a decision criterion. A common generative model for real-valued features, allowing for feature interactions, views the known members of any given class as a sample of a multivariate normal (Gaussian) random variable. Learning in this case consists of estimating the mean and covariance matrix of each class (an example of maximum likelihood estimation).
A traditional discriminative approach, not premised on any generative model, involves the computation of hyperplanes that partition the clusters of known class instances from one another (optimizing certain metrics involving in-class and between-class variance); new instances are assigned to the class into whose partition they fall. Perceptrons provide a related technique, insofar as they decide class membership on the basis of a linear combination of feature values; their particular advantage is that they can learn incrementally (by adjusting feature weights) as more and more training data become available. Another durable discriminative approach—not dependent on linear separability of classes—is the k nearest neighbors (kNN) method, which assigns an unknown text or document to the class that is most prevalent among its k (e.g., 1–5) nearest neighbors in vector space. While all the previously mentioned methods depended on parameter estimation (e.g., generative probabilities, Gaussian parameters, or coefficients of separating planes), kNN uses no such parameters—it is nonparametric; however, finding a suitable measure of proximity or similarity can be challenging, and errors due to haphazard local data point configurations in feature space are hard to avoid. Another nonparametric discriminative method worth mentioning is the use of decision trees, which can be learned using information-theoretic techniques; they enable choice of a class by following a root-to-leaf path, with branches chosen via tests on features of a given input vector. A potentially useful property is that learned decision trees can provide insight into what the most important features are (such insight can also be provided by dimensionality reduction methods). However, decision trees tend to converge to nonglobal optima (global optimization is NP-hard), and by splitting data, tend to block modeling of feature interactions; this defect can be alleviated to some extent through the use of decision forests.
Having mentioned some of the traditional classification methods, we now sketch two techniques that have become particularly prominent in statistical NLP since the 1990s. The first, with mathematical roots dating to the 1950s, is maximum entropy (MaxEnt), also called (multinomial) logistic regression (e.g., Ratnaparkhi 1997). Features in this case are any desired 0, 1-valued (binary) functions of both a given linguistic input and a possible class. (For continuous features, supervised or unsupervised discretization methods may be applied, such as entropy-based partitioning into some number of intervals.) Training data provide occurrence frequencies for these features, and a distribution is derived for the conditional probability of a class, given a linguistic input. (As such, it is a discriminative method.) As its name implies, this conditional probability function is a maximum-entropy distribution, constrained to conform with the binary feature frequencies observed in the training data. Its form (apart from a constant multiplier) is an exponential whose exponent is a linear combination of the binary feature values for a given input and given class. Thus it is a log-linear model (a distribution whose logarithm is linear in the features)—a type of model now prevalent in many statistical NLP tasks. Note that since its logarithm is a linear combination of binary feature values for any given input and any given class, choosing the maximum-probability class for a given input amounts to linear decision-making, much as in some of the classical methods; however, MaxEnt generally provides better classification performance, and the classification probabilities it supplies can be useful in further computations (e.g., expected utilities).
Another method important in the emergence and successes of statistical NLP is the support vector machine (SVM) method (Boser et al. 1992; Cortes and Vapnik 1995). The great advantage of this method is that it can in principle distinguish arbitrarily configured classes, by implicitly projecting the original vectors into a higher- (or infinite-) dimensional space, where the classes are linearly separable. The projection is mediated by a kernel function—a similarity metric on pairs of vectors, such as a polynomial in the dot product of the two vectors. Roughly speaking, the components of the higher-dimensional vector correspond to terms of the kernel function, if it were expanded out as a sum of products of the features of the original, unexpanded pair of vectors. But no actual expansion is performed, and moreover the classification criterion obtained from a given training corpus only requires calculation of the kernel function for the given feature vector (representing the document to be classified) paired with certain special “support vectors”, and comparison of a linear combination of the resulting values to a threshold. The support vectors belong to the training corpus, and define two parallel hyperplanes that separate the classes in question as much as possible (in the expanded space). (Hence this is a “max-margin” discriminative method.) SVMs generally provide excellent accuracy, in part because they allow for nonlinear feature interaction (in the original space), and in part because the max-margin method focuses on class separation, rather than conditional probability modeling of the classes. On the other hand, MaxEnt classifiers are more quickly trainable than SVMs, and often provide satisfactory accuracy. General references covering the classification methods we have sketched are (Duda et al. 2001; Bishop 2006).
Classification of selected words or phrases in sentential or broader contexts: As noted earlier, examples include WSD, named entity recognition, and sentence boundary detection. The only point of distinction from text/document classification is that it is not a chunk of text as a whole, but rather a word or phrase in the context of such a chunk that is to be classified. Therefore features are chosen to reflect both the features of the target word or phrase (such as morphology) and the way it relates to its context, in terms of, e.g., surrounding words or word categories, (likely) local syntactic dependency relations, and features with broader scope such as word frequencies or document class. Apart from this difference in how features are chosen, the same (supervised) learning and classification methods discussed above can be applied. However, sufficiently large training corpora may be hard to construct. For example, in statistical WSD (e.g., Yarowsky 1992; Chen et al. 2009), since thousands of words have multiple senses in sources such as WordNet, it is difficult to construct a sense-annotated training corpus that contains sufficiently many occurrences of all of these senses to permit statistical learning. Thus annotations are typically restricted to the senses of a few polysemous words, and statistical WSD has been shown to be feasible for the selected words, but broad-coverage WSD tools remain elusive.
Sequence labeling: There is a somewhat arbitrary line between the preceding task and sequence labeling. For example, it is quite possible to treat POS tagging as a task of classifying words in a text in relation to their context. However, such an approach fails to exploit the fact that the classifications of adjacent words are interdependent. For example, in the sentence (from the web) “I don't fish like most people”, the occurrence of don't should favor classification of fish as a verb, which in turn should favor classification of like as a preposition. (At least such preferences make sense for declarative sentences; replacing ‘I’ by ‘why’ would change matters—see below.) Such cascaded influences are not easily captured through successive independent classifications, and they motivate generative sequence models such as HMMs. For POS tagging, a labeled training corpus can supply estimates of the probability of any POS for the next word, given the POS of the current word. If the corpus is large enough, it can also supply estimates of word “emission” probabilities for a large proportion of words generally seen in text, i.e., their probability of occurring, given the POS label. (Smoothing techniques are used to fill in non-zero probabilities for unknown words, given a POS.) We previously mentioned the Viterbi algorithm as an efficient dynamic programming algorithm for applying an HMM (trained as just mentioned) to the task of assigning a maximum-probability POS tag sequence to the words of a text. Two related algorithms, the forward and backward algorithms, can be used to derive probabilities of the possible labels at each word position i, which may be more useful than the “best” label sequence for subsequent higher-level processing. The forward algorithm in effect (via dynamic programming) sums the probabilities of all label sequences up to position i that end with a specified label X at word position i and that generate the input up to (and including) that word. The backward algorithm sums the probabilities of all label sequences that begin with label X at position i, and generate the input from position i+1 to the end. The product of the forward and backward probabilities, normalized so that the probabilities of the alternative labels at position i sum to 1, give the probability of X at i, conditioned on the entire input.
All learning methods referred to so far have been supervised learning methods—a corpus of correctly labeled texts was assumed to be available for inferring model parameters. But methods have been developed for unsupervised (or semi-supervised) learning as well. An important unsupervised method of discovering HMM models for sequence labeling is the forward-backward (or Baum-Welch) algorithm. A simple version of this algorithm in the case of POS tagging relies on a lexicon containing the possible tags for each word (which are easily obtained from a standard lexicon). Some initial, more or less arbitrarily chosen values of the HMM transition and emission probabilities are then iteratively refined based on a training corpus. A caricature of the iterative process would be this: We use the current guesses of the HMM parameters to tag the training corpus; then we re-estimate those parameters just as if the corpus were hand-tagged. We repeat these two steps till convergence. The actual method used is more subtle in the way it uses the current HMM parameters. (It is a special case of EM—Expectation Maximization.) Rather than re-estimating the parameters based on occurrence frequencies in the current “best” tag sequence, it uses the expected number of occurrences of particular pairs of successive states (labels), dividing this by the expected number of occurrences of the first member of the pair. These expected values are determined by the conditional probability distribution over tag sequences, given the training corpus and the current HMM parameters, and can be obtained using the forward and backward probabilities as described above (and thus, conditioned on the entire corpus). Revised emission probabilities for any X → w can be computed as the sum of probabilities of X-labels at all positions where word w occurs in the corpus, divided by the sum of probabilities of X-labels at all positions, again using (products of) forward and backward probabilities.
Unfortunately EM is not guaranteed to find a globally optimal model. Thus good results can be achieved only by starting with a “reasonable” initial HMM, for example assigning very low probabilities to certain transitions (such as determiner → determiner, determiner → verb, adjective → verb). Semi-supervised learning might start with a relatively small labeled training corpus, and use the corresponding HMM parameter estimates as a starting point for unsupervised learning from further, unlabeled texts.
A weakness of HMMs themselves is that the Markov assumption (independence of non-neighbors, given the neighbors) is violated by longer-range dependencies in text. For example, in the context of a relative clause (signaled by a noun preceding that clause), a transitive verb may well lack an NP complement ( “I collected the money he threw down on the table.”), and as a result, words following the verb may be tagged incorrectly (down as a noun). A discriminative approach that overcomes this difficulty is the use of conditional random fields (CRFs). Like HMMs (which they subsume), these allow for local interdependence of hidden states, but employ features that depend not only on adjacent pairs of these states, but also on any desired properties of the entire input. Mathematically, the method is very similar to MaxEnt (as discussed above). The feature coefficients can be learned from training data either by gradient ascent or by an incremental dynamic programming method related to the Baum-Welch algorithm, called improved iterative scaling (IIS) (Della Pietra et al. 1997; Lafferty et al. 2001). CRFs have been successful in many applications other than POS tagging, such as sentence and word boundary detection (e.g., for Chinese), WSD, extracting tables from text, named entity recognition, and—outside of NLP—in gene prediction and computer vision.
Structure assignment to sentences: The use of probabilistic context-free grammars (PCFGs) was briefly discussed in section 2. Supervised learning of PCFGs can be implemented much like supervised learning of HMMs for POS tagging. The required conditional probabilities of phrase expansion are easily estimated if a large corpus annotated with phrase bracketings (a treebank) is available (though estimates of POS → word expansion probabilities are best supplemented with additional data). Once learned, a PCFG can be used to assign probabilistically weighted phrase structures to sentences using the chart parsing method mentioned in section 2—again a dynamic programming method.
Also, unsupervised learning of PCFGs is possible using the EM approach. This is important, since it amounts to grammar discovery. The only assumption we start with, theoretically, is that there is some maximum number of nonterminal symbols, and each can be expanded into any two nonterminals or into any word (Chomsky normal form). Also we associate some more or less arbitrary initial expansion probabilities with these rules. The probabilities are iteratively revised using expected values of the frequency of occurrence of the possible expansions, based on the current PCFG model, conditioned on the corpus. The analogue of the forward-backward algorithm for computing these expectations is the inside-outside algorithm. Inside probabilities specify the probability that a certain proper segment of a given sentence will be derived from a specified nonterminal symbol. Outside probabilities specify the probability that all but a certain segment of the given sentence will be derived from the start (sentence) symbol, where that “missing” segment remains to be generated from a specified nonterminal symbol. The inside and outside probabilities play roles analogous to the backward and forward probabilities in HMM learning respectively. Conceptually, they require summations over exponentially many possible parse trees for a given sentence, but in fact inside probabilities can be computed efficiently by the CYK algorithm (section 2), and outside probabilities can also be computed efficiently, using a top-down recursive “divide and conquer” algorithm that makes use of previously computed inside probabilities.
Modest successes have been achieved in learning grammars in this way. The complexity is high (cubic-time in the size of the training corpus as well as in the number of nonterminals), and as noted, EM does not in general find globally optimal models. Thus it is important to place some constraints on the initial grammar, e.g., allowing nonterminals to generate either pairs of nonterminals or words, but not both, and also severely limiting the number of allowed nonterminals. A method of preferring small rule sets over large ones, without setting a fixed upper bound, is the use of a Dirichlet process that supplies a probability distribution over the probabilities of an unbounded number of rules. (This method is nonparametric, in the sense that it does not commit to any fixed number of building blocks or parameters in the modeling.) Whatever method of bounding the rules is used, the initial PCFG must be carefully chosen if a reasonably good, meaningful rule set is to be learned. One method is to start with a linguistically motivated grammar and to use “symbol splitting” (also called “state splitting”) to generate variants of nonterminals that differ in their expansion rules and probabilities. Recent spectral algorithms offer a relatively efficient, and globally optimal, alternative to EM (Cohen et al. 2013), and they can be combined with symbol splitting.
Like HMMs, PCFGs are generative models, and like them suffer from insufficient sensitivity of local choices to the larger context. CRFs can provide greater context-sensitivity (as in POS tagging and other types of sequence labeling); though they are not directly suited to structure assignment to text, they can be used to learn shallow parsers, which assign phrase types only to nonrecursive phrases (core NPs, PPs, VPs, etc.) (Sha and Pereira 2003).
In the current grammar-learning context, we should also mention connectionist models once more. Such models have shown some capacity for learning to parse from a set of training examples, but achieving full-scale parsing in this way remains a challenge. Also a controversial issue is the capacity of nonsymbolic NNs to exhibit systematicity in unsupervised learning, i.e., demonstrating a capacity to generalize from unannotated examples. This requires, for example, the ability to accept or generate sentences wherein verb arguments appear in positions different from those seen in the training set. According to Brakel and Frank (2009), systematicity can be achieved with simple recurrent networks (SRNs). However, computational demonstrations have generally been restricted to very simple, English-like artificial languages, at least when inputs were unannotated word streams.
A structure assignment task that can be viewed as a step towards semantic interpretation is semantic role labeling (Palmer et al. 2010). The goal is to assign thematic roles such as agent, theme, recipient, etc. to core phrases or phrasal heads in relation to verbs (and perhaps other complement-taking words). While this can be approached as a sequence labeling problem, experimental evidence shows that computing parse trees and using resulting structural features for role assignment (or jointly computing parse trees and roles) improves precision. A frequently used training corpus for such work is PropBank, a version of the Penn Treebank annotated with “neutral” roles arg0, arg1, arg2, etc.
Sentence transduction: The most intensively studied type of statistical sentence transduction to date has been statistical MT (SMT) (e.g., Koehn 2010; May 2012). Its successes beginning in the late 1980s and early 90s came as something of a surprise to the NLP community, which had been rather pessimistic about MT prospects ever since the report by Bar-Hillel (1960) and the ALPAC report (Pierce et al. 1966), negatively assessing the results of a major post-WW2 funding push in MT by the US government. MT came to be viewed as a large-scale engineering enterprise that would not have broad impacts until it could be adequately integrated with semantics and knowledge-based inference. The statistical approach emerged in the wake of successful application of “noisy channel” models to speech recognition in the late 1970s and during the 80s, and was propelled forward by new developments in machine learning and the increasing availability of large machine-readable linguistic corpora, including parallel texts in multiple languages.
The earliest, and simplest type of translation method was word-based. This was grounded in the following sort of model of how a foreign-language sentence f (say, in French) is generated from an English sentence e (which we wish to recover, if the target language is English): First, e is generated according to some simple model of English, for instance one based on bigram frequencies. Individual words of e are then assumed to generate individual words of f with some probability, allowing for arbitrary word-order scrambling (or biased in some way). In learning such a model, the possible correspondences and word-translation probabilities can be estimated from parallel English-French corpora, whose sentences and words have been aligned by hand or by statistical techniques. Such a model can then be used for “decoding” a given French sentence f into an English sentence e by Bayesian inference—we derive e as the English sentence with highest posterior probability, given its French “encoding” as f. This is accomplished with dynamic programming algorithms, and might use an intermediate stage where the n best choices of e are computed (for some predetermined n), and subsequently re-ranked discriminatively using features of e and f ignored by the generative model.
However, the prevailing SMT systems (such as Google Translate or Yahoo! Babel Fish) are phrase-based rather than word-based. Here “phrase” refers to single words or groups of words that tend to occur adjacent to each other. The idea is that phrases are mapped to phrases, for example, the English word pair red wine to French phrases vin rouge, du vin rouge, or le vin rouge. Also, instead of assuming arbitrary word order scrambling, reordering models are used, according to which a given phrase may tend to be swapped with the left or right neighboring phrase or displaced from the neighbors, in the translation process. Furthermore, instead of relying directly on a Bayesian model, as in the word-based approach, phrase-based approaches typically use a log-linear model, allowing for incorporation of features reflecting not only the language model (such as trigram frequencies), the phrase translation model (such as phrase translation frequencies), and the reordering model, but also miscellaneous features such as the number of words created, the number of phrase translations used, and the number of phrase reorderings (with larger penalties for larger displacements).
While phrase-based SMT models have been quite successful, they are nonetheless prone to production of syntactically disfluent or semantically odd translations, and much recent research has sought to exploit linguistic structure and patterns of meaning to improve translation quality. Two major approaches to syntactic transfer are hierarchical phrase-based translation and tree-to-string (TTS) transduction models. Hierarchical phrase-based approaches use synchronous grammar rules, which simultaneously expand partial derivations of corresponding sentences in two languages. These are automatically induced from an aligned corpus, and the lowest hierarchical layer corresponds to phrase-to-phrase translation rules like those in ordinary phrase-based translation. While quite successful, this approach provides little assurance that “phrases” in the resulting synchronous grammars are semantically coherent units, in the linguistic sense. TTS models obtain better coherency through use of parsers trained on phrase-bracketed text corpora (treebanks). The encoding of English sentences into French (in keeping with our previously assumed language pair) is conceptualized as beginning with a parsed English sentence, which is then transformed by (learned) rules that progressively expand the original or partially transformed pattern of phrases and words until all the leaves are French words.
Apart from MT, another important type of sentence transduction is semantic parsing, in the sense of mapping sentences in some domain to logical forms usable for question answering. (Note that semantic role labeling, discussed above, can also be viewed as a step towards semantic parsing.) Several studies in this relatively recent area have employed supervised learning, based on training corpora annotated with LFs (e.g., Mooney 2007; Zettlemoyer & Collins 2007) or perhaps syntactic trees along with LFs (e.g., Ge and Mooney 2009). Typical domains have been QA about geography (where LFs are database queries), about Robocup soccer, or about travel reservations. Even unsupervised learning has been shown to be possible in restricted domains, such as QA based on medical abstracts (Poon and Domingos 2009) or the travel reservation domain (Poon 2013). Ideas used in this work include forming synonym clusters of nominal terms and verbal relations much as in Lin and Pantel's DIRT system, with creation of logical names (reflecting their word origins) for these concepts and relations; and learning (via Markov logic, a generalization of Markov networks) to annotate the nodes of dependency parse trees with database entities, types, and relations on the basis of a travel reservation dialogue corpus (where the data needed for the travel agent's answers are known to lie in the database). Whether such methods can be generalized to less restricted domains and forms of language remains to be seen. The recent creation of a general corpus annotated with an “abstract meaning representation”, AMR, is likely to foster progress in that direction (Banarescu et al. 2013).
The topics we have touched on in this section are technically complex, so that our discussion has necessarily been shallow. General references for statistical language processing are Manning and Schütze 1999 and Jurafsky and Martin 2009. Also the statistical NLP community has developed remarkably comprehensive toolkits for researchers, such as MALLET (MAchine Learning for LanguagE Toolkit), which includes brief explanations of many of the techniques.
What are the prospects for achieving human-like language learning in machines? There is a growing recognition that statistical learning will have to be linked to perceptual and conceptual modeling of the world. Recent work in the area of grounded language learning is moving in that direction. For example, Kim and Mooney (2012) describe methods of using sentences paired with graph-based descriptions of actions and contexts to hypothesize PCFG rules for parsing NL instructions into action representations, while learning rule probabilities with the inside-outside algorithm. However, they assumed a very restricted domain, and the question remains how far the modeling of perception, concept formation, and of semantic and episodic memory needs to be taken to support unrestricted language learning. As in the case of world knowledge acquisition by machines (see the preceding section), the modeling capabilities may need to achieve equivalence with those of a newborn, allowing for encoding percepts and ideas in symbolic and imagistic languages of thought, for taxonomizing entity types, recognizing animacy and intentionality, organizing and abstracting spatial relations and causal chains of events, and more. Providing such capabilities is likely to require, along with advances in our understanding of cognitive architecture, resolution of the very issues concerning the representation and use of linguistic, semantic, and world knowledge that have been the traditional focus in computational linguistics.
10. Applications
As indicated at the outset, applications of computational linguistics techniques range from those minimally dependent on linguistic structure and meaning, such as document retrieval and clustering, to those that attain some level of competence in comprehending and using language, such as dialogue agents that provide help and information in limited domains like personal scheduling, flight booking, or help desks, and intelligent tutoring systems. In the following we enumerate some of these applications. In several cases (especially machine translation) we have already provided considerable detail, but the intent here is to provide a bird's eye view of the state of the art, rather than technical elucidations.
With the advent of ubiquitous computing, it has become increasingly difficult to provide a systematic categorization of NLP applications: Keyword-based retrieval of documents (or snippets) and database access are integrated into some dialogue agents and many voice-based services; animated dialogue agents interact with users both in tutoring systems and games; chatbot techniques are incorporated into various useful or entertaining agents as a backends; and language-enabled robots, though distinctive in combining vision and action with language, are gradually being equipped with web access, QA abilities, tutorial functions, and no doubt eventually with collaborative problem solving abilities. Thus the application categories in the subsections that follow, rather than being mutually exclusive, are ever more interwined in practice.
10.1 Machine translation (again)
One of the oldest MT systems is SYSTRAN, which was developed as a rule-based system beginning in the 1960s, and has been extensively used by US and European government agencies, and also in Yahoo! Babel Fish and (until 2007) in Google Translate. In 2010, it was hybridized with statistical MT techniques. As mentioned, Google Translate currently uses phrase-based MT, with English serving as an interlingua for the majority of language pairs. Microsoft's Bing Translator employs dependency structure analysis together with statistical MT. Other very comprehensive translation systems include Asia Online and WorldLingo. Many systems for small language groups exist as well, for instance for translating between Punjabi and Hindi (the Direct MT system), or between a few European languages (e.g., OpenLogos, IdiomaX, and GramTrans).
Translations remain error-prone, but their quality is usually sufficient for readers to grasp the general drift of the source contents. No more than that may be required in many cases, such as international web browsing (an application scarcely anticipated in decades of MT research). Also, MT applications on hand-held devices, designed to aid international travellers, can be sufficiently accurate for limited purposes such as asking directions or emergency help, interacting with transportation personnel, or making purchases or reservations, When high-quality translations are required, automatic methods can be used as an aid to human translators, but subtle issues may still absorb a large portion of a translator's time.
10.2 Document retrieval and clustering applications
Information retrieval has long been a central theme of information science, covering retrieval of both structured data such as are found in relational databases as well as unstructured text documents (e.g., Salton 1989). Retrieval criteria for the two types of data are not unrelated, since both structured and unstructured data often require content-directed retrieval. For example, while users of an employee database may wish at times to retrieve employee records by the unique name or ID of employees, at other times they may wish to retrieve all employees in a certain employment category, perhaps with further restrictions such as falling into a certain salary bracket. This is accomplished with the use of “inverted files” that essentially index entities under their attributes and values rather than their identifiers. In the same way, text documents might be retrieved via some unique label, or they might instead be retrieved in accord with their relevance to a certain query or topic header. The simplest notion of relevance is that the documents should contain the terms (words or short phrases) of the query. However, terms that are distinctive for a document should be given more weight. Therefore a standard measure of relevance, given a particular query term, is the tf–idf (term frequency–inverse document frequency) for the term, which increases (e.g., logarithmically) with the frequency of occurrences of the term in the document but is discounted to the extent that it occurs frequently in the set of documents as a whole. Summing the tf-idf's of the query terms yields a simple measure of document relevance.
Shortcomings of this method are first, that it underrates term co-occurrences if each term occurs commonly in the document collection (for instance, for the query “rods and cones of the eye”, co-occurrences of rods, cones, and eye may well characterize relevant documents, even though all three terms occur quite commonly in non-physiological contexts), and second, that relevant documents might have few occurrences of the query terms, while containing many semantically related terms. Some of the vector methods mentioned in connection with document clustering can be used to alleviate these shortcomings. We may reduce the dimensionality of the term-based vector space using LSA, obtaining a much smaller “concept space” in which many terms that tend to co-occur in documents will have been merged into the same dimensions (concept). Thus sharing of concepts, rather than sharing of specific terms, becomes the basis for measuring relevance.
Document clustering is useful when large numbers of documents need to be organized for easy access to topically related items, for instance in collections of patent descriptions, medical histories or abstracts, legal precedents, or captioned images, often in hierarchical fashion. Clustering is also useful in exploratory data analysis (e.g., in exploring token occurrences in an unknown language), and indirectly supports various NLP applications because of its utility in improving language models, for instance in providing word clusters to be used for backing off from specific words in cases of data sparsity.
Clustering is widely used in other areas, such as biological and medical research and epidemiology, market research and grouping and recommendation of shopping items, educational research, social network analysis, geological analysis, and many others.
Document retrieval and clustering often serve as preliminary steps in information extraction (IE) or text mining, two overlapping areas concerned with extracting useful knowledge from documents, such as the main features of named entities (category, roles in relation to other entities, location, dates, etc.) or of particular types of events, or inferring rule-like correlations between relational terms (e.g., that purchasing of one type of product correlates with purchasing another).
We will not attempt to survey IE/text mining applications comprehensively, but the next two subsections, on summarization and sentiment analysis, are subareas of particular interest here because of their emphasis on the semantic content of texts.
10.3 Knowledge extraction and summarization
Extracting knowledge or producing summaries from unstructured text are ever more important applications, in view of the deluge of documents issuing forth from news media, organizations of every sort, and individuals. This unceasing stream of information makes it difficult to gain an overview of the items relevant to some particular purpose, such as basic data about individuals, organizations and consumer products, or the particulars of accidents, earthquakes, crimes, company take-overs, product maintenance and repair activities, medical research results, and so on.
One commonly used method in both knowledge extraction and certain types of “rote” summarization relies on the use of extraction patterns; these are designed to match the kinds of conventional linguistic patterns typically used by authors to express the information of interest. For example, text corpora or newswire might be mined for information about companies, by keying in on known company names and terms such as “Corp.”, “.com”, “headquartered at”, and “annual revenue of”, as well as parts of speech and dependency relations, and matching regular-expression patterns against local text segments containing key phrases or positioned close to them. As another example, summarization of earthquake reports might extract expected information such as the epicenter of the quake, its magnitude on the Richter scale, the time and duration of the event, affected population centers, extent of death tolls, injuries, and property damage, consequences such as fires and tsunamis, etc. Extraction patterns can usually be thought of as targeting particular attributes in predetermined attribute-value frames (e.g., a frame for company information or a frame for facts about an earthquake), and the filled-in frames may themselves be regarded as summaries, or may be used to generate natural-language summaries. Early systems of this type were FRUMP (DeJong 1982) and JASPER (Andersen et al. 1992). Among the hundreds of more modern extraction systems, a particularly successful one in competitions has been SRI's “Fastus” (Hobbs et al. 1997).
Note that whether a pattern-based system is viewed as a knowledge extraction system or summarization system depends on the text it is applied to. If all the information of interest is bundled together in a single, extended text segment (as in the case of earthquake reports), then the knowledge extracted can be viewed as a summary of the segment. If instead the information is selectively extracted from miscellaneous sentences scattered through large text collections, with most of the material being ignored as irrelevant to the purposes of extraction, then we would view the activity of the system as information extraction rather than summarization.
When a document to be summarized cannot be assumed to fall into some predictable category, with the content structured and expressed in a stereotyped way, summarization is usually performed by selecting and combining “central sentences” from the document. A sentence is central to the extent that many other sentences in the document are similar to it, in terms of shared word content or some more sophisticated similarity measure such as one based on the tf-idf metric for terms, or a cosine metric in a dimensionality-reduced vector space (thus it is as if we were treating individual sentences as documents, and finding a few sentences whose “relevance” to the remaining sentences is maximal). However, simply returning a sequence of central sentences will not in general yield an adequate summary. For example, such sentences may contain unresolved pronouns or other referring expressions, whose referents may need to be sought in non-central sentences. Also, central “sentences” may actually be clauses embedded in lengthier sentences that contain unimportant supplementary information. Heuristic techniques need to be applied to identify and excise the extra material, and extracted clauses need to be fluently and coherently combined. In other cases, complex descriptions should be more simply and abstractly paraphrased. For example, an appropriate condensation of a sentence such as “The tornado carried off the roof of a local farmhouse, and reduced its walls and contents to rubble” might be “The tornado destroyed a local farmhouse.” But while some of these issues are partially addressed in current systems, human-like summarization will require much deeper understanding than is currently attainable. Another difficulty in this area (even more so than in machine translation) is the evaluation of summaries. Even human judgments differ greatly, depending, for instance, on the sensitivity of the evaluator to grammatical flaws, versus inadequacies in content.
10.4 Sentiment analysis
Sentiment analysis refers to the detection of positive or negative attitudes (or more specific attitudes such as belief or contempt) on the part of authors of articles or blogs towards commercial products, films, organizations, persons, ideologies, etc. This has become a very active area of applied computational linguistics, because of its potential importance for product marketing and ranking, social network analysis, political and intelligence analysis, classification of personality types or disorders based on writing samples, and other areas. The techniques used are typically based on sentiment lexicons that classify the affective polarity of vocabulary items, and on supervised machine learning applied to texts from which word and phrasal features have been extracted and that have been hand-labeled as expressing positive or negative attitudes towards some theme. Instead of manual labeling, existing data can sometimes be used to provide a priori classification information. For example, average numerical ratings of consumer products or movies produced by bloggers may be used to learn to classify unrated materials belonging to the same or similar genres. If fact, affective lexical categories and contrast relations may be learnable from such data; for example, frequent occurrences of phrases such as great movie or pretty good movie or terrible movie in blogs concerning movies with high, medium, and low average ratings may well suggest that great, pretty good, and terrible belong to a contrast spectrum ranging from a very positive to a very negative polarity. Such terminological knowledge can in turn boost the coverage of generic sentiment lexicons. However, sentiment analysis based on lexical and phrasal features has obvious limitations, such as obliviousness to sarcasm and irony ( “This is the most subtle and sensitive movie since The Texas Chainsaw Massacre”), quotation of opinions contrasting with the author's (“According to the ads, Siri is the greatest app since iTunes, but in fact …”), and lack of understanding of entailments (“You'll be much better off buying a pair of woolen undies for the winter than purchasing this item”). Thus researchers are attempting to integrate knowledge-based and semantic analysis with superficial word- and phrase-based sentiment analysis.
10.5 Chatbots and companionable dialogue agents
Current chatbots are the descendants of Weizenbaum's ELIZA (see section 1.2), and are typically used (often with an animated “talking head” character) for entertainment, or to engage the interest of visitors to the websites of certain “dotcoms”. They may be equipped with large hand-crafted scripts (keyword-indexed input-response schemas) that enable them to answer simple inquiries about the company and their products, with some ability to respond to miscellaneous topics and to exchange greetings and pleasantries. A less benign application is the use of chatbots posing as visitors to social network sites, or interactive game sites, with the aim of soliciting private information from unwitting human participants, or recommending websites or products to them. As a result, many social networking sites have joined other bot-targeted sites in using CAPTCHAS to foil bot entry.
Companionable dialogue agents (also called relational agents) have so far relied rather heavily on chatbot techniques, i.e., authored input patterns and corresponding outputs. But the goal is to transcend these techniques, creating agents (often with talking heads or other animated characters) with personality traits and capable of showing emotion and empathy; they should have semantic and episodic memory, learning about the user over the long term and providing services to the user. Those services might include, besides companionship and support: advice in some areas of life, health and fitness, schedule maintenance, reminders, question answering, tutoring (e.g., in languages), game playing, and internet services. Yorick Wilks has suggested that ideally such characters would resemble “Victorian companions”, with such characteristics as politeness, discretion, modesty, cheerfulness, and well-informedness (Wilks 2010).
However, such goals are far from being achieved, as speech recognition, language understanding, reasoning and learning are not nearly far enough advanced. As a noteworthy example of the state of the art, we might mention the HWYD (“How Was Your Day”) system of Pulman et al. (2010), which won a best demonstration prize at an autonomous agents conference. The natural language processing in this system is relatively sophisticated. Shallow syntactic and semantic processing is used to find instantiations of some 30 “event templates”, such as ones for “argument at work between X and Y,” or “meeting with X about Y”. The interpretation process includes reference and ellipsis resolution, relying on an information state representation maintained by the dialogue manager. Goals generated by the dialogue manager lead to responses via planning, which involves instantiation and sequencing of response paradigms. The authors report the system's ability to maintain consistent dialogues extending over 20 minutes.
Systems of a rather different sort, aimed at clinically well-founded health counseling, have been under development as well. For example, the systems described in (Bickmore et al. 2011) rely on an extensive, carefully engineered formalization of clinically proven counseling strategies and knowledge, expressed within a description logic (OWL) and a goal-directed task description language. Such systems have proved to perform in a way comparable to human counselors. However, though dialogues are plan-driven, they ultimately consist of scripted system utterances paired with multiple-choice lists of responses offered to the client.
Thus companionable systems remain very constrained in the dialogue themes they can handle, their understanding of language, and their ability to bring extensive general knowledge to a conversation, let alone to use such knowledge inferentially.
10.6 Virtual worlds, games, and interactive fiction
Text-based adventure (quest) games, such as Dungeons and Dragons, Hunt the Wumpus (in its original version), and Advent began to be developed in the early and middle 1970s, and typically featured textual descriptions of the setting and challenges confronting the player, and allowed for simple command-line input from the player to select available actions (such as “open box”, “take sword” or “read note”). While the descriptions of the settings (often accompanied by pictures) could be quite elaborate, much as in adventure fiction, the input options available to the player were, and have largely remained, restricted to simple utterances of the sort that can be anticipated or collected in pre-release testing by the game programmers, and for which responses can be manually prepared. Certainly more flexible use of NL ( “fend off the gremlin with the sword!”, “If I give you the gold, will you open the gate for me?”) would enliven the interaction between player and the game world and the characters in it. In the 1980s and 90s text-based games declined in favor of games based primarily on graphics and animation, though an online interactive fiction community grew over the years that drove the evolution of effective interactive fiction development software. A highly touted program (in the year 2000) was Emily Short's ‘Galatea’, which enabled dialogue with an animated sculpture. However, this is still an elaborately scripted program, allowing only for inputs that can be heuristically mapped to one of various preprogrammed responses. Many games in this genre also make use of chatbot-like input-output response patterns in order to gain a measure of robustness for unanticipated user inputs.
The most popular PC video games in the 1990s and beyond were Robyn and Rand Miller's Myst, a first-person adventure game, and Maxis Software's The Sims, a life-simulation game. Myst, though relying on messages in books and journals, was largely nonverbal, and The Sims' chief developer, Will Wright, finessed the problem of natural language dialogue by having the inhabitants of SimCity babble in Simlish, a nonsense language incorporating elements of Ukrainian, French and Tagalog.
Commercial adventure games and visual novels continue to rely on scripted dialogue trees—essentially branching alternative directions in which the dialogue can be expected to turn, with ELIZA-like technology supporting the alternatives. More sophisticated approaches to interaction between users and virtual characters are under development in various research laboratories, for example at the Center for Human Modeling and Simulation at the University of Pennsylvania, and the USC-affiliated Institute for Creative Technologies. While the dialogues in these scenarios are still based on carefully designed scripts, the interpretation of the user's spoken utterances exploits an array of well-founded techniques in speech recognition, dialogue management, and reasoning. Ongoing research can be tracked at venues such as IVA (Intelligent Virtual Agents), AIIDE (AI and Interactive Digital Entertainment), and AAMAS (Autonomous Agents and Multiagent Systems).
10.7 Natural language user interfaces
The topic of NL user interfaces subsumes a considerable variety of NL applications, ranging from text-based systems minimally dependent on understanding to systems with significant comprehension and inference capabilities in text- or speech-based interactions. The following subsections briefly survey a range of traditional and current applications areas.
Text-based question answering
Text-based QA is practical to the extent that the types of questions being asked can be expected to have ready-made answers tucked away somewhere in the text corpora being accessed by the QA system. This has become much more feasible in this age of burgeoning internet content than a few decades ago, though questions still need to be straightforward, factual ones (e.g., “Who killed President Lincoln?”) rather than ones requiring inference (e.g., “In what century did Catherine the Great live?”, let alone “Approximately how many 8-foot 2-by-4s do I need to build a 4-foot high, 15-foot long picket fence?”).
Text-based QA begins with question classification (e.g., yes-no questions, who-questions, what-questions, when-questions, etc.), followed by information retrieval for the identified type of question, followed by narrowing of the search to paragraphs and finally sentences that may contain the answer to the question. The successive narrowing typically employs word and other feature matching, and ultimately dependency and role matching, and perhaps limited textual inference to verify answer candidates. Textual inference may, for instance, use WordNet hypernym knowledge to try to establish that a given candidate answer sentence supports the truth of the declarative version of the question. Since the chosen sentence(s) may contain irrelevant material and anaphors, it remains to extract the relevant material (which may also include supporting context) and generate a well-formed, appropriate answer. Many early text-based QA systems up to 1976 are discussed in Bourne & Hahn 2003. Later surveys (e.g., Maybury 2004) have tended to include the full spectrum of QA methods, but TREC conference proceedings (https://trec.nist.gov/) feature numerous papers on implemented systems for text-based QA.
In open-domain QA, many questions are concerned with properties of named entities, such as birth date, birth place, occupation, and other personal attributes of well-known present and historical individuals, locations, ownership, and products of various companies, facts about consumer products, geographical facts, and so on. For answering such questions, it makes sense to pre-assemble the relevant factoids into a large knowledge base, using knowledge acquisition methods like those in section 8. Examples of systems containing an abundance of factoids about named entities are several developed at the University of Washington, storing factoids as text fragments, and various systems that map harvested factoids into RDF (Resource Description Framework) triples (see references in Other Internet Resources). Some of these systems obtain their knowledge not only from open information extraction and targeted relation extraction, but also from such sources as Wikipedia “infoboxes” and (controlled) crowdsourcing. Here we are also stretching the notion of question answering, since several of the mentioned systems require the use of key words or query patterns for retrieval of factoids.
From a general user perspective, it is unclear how much added benefit can be derived from such constructed KBs, given the remarkable ability of Google and other search engines to provide rapid answers even to such questions as “Which European countries are landlocked?” (typed without quotes—with quotes, Google finds the top answer using True Knowledge), or “How many Supreme Court justices did Kennedy appoint?” Nonetheless, both Google and Microsoft have recently launched vast “knowledge graphs” featuring thousands of relations among hundreds of millions of entities. The purpose is to provide direct answers (rather then merely retrieved web page snippets) to query terms and natural language questions, and to make inferences about the likely intent of users, such as purchasing some type of item or service.
Database front-ends
Natural-language front ends for databases have long been considered an attractive application of NLP technology, beginning with such systems as LUNAR (Woods et al. 1972) and REL (Thompson et al. 1969; Thompson & Thompson 1975). The attractiveness lies in the fact that retrieval and manipulation of information from a relational (or other uniformly structured) database can be assumed to be handled by an existing db query language and process. This feature sharply limits the kinds of natural language questions to be expected from a user, such as questions aimed at retrieving objects or tuples of objects satisfying given relational constraints, or providing summary or extremal properties (longest rivers, lowest costs, and the like) about them. It also greatly simplifies the interpretive process and question-answering, since the target logical forms—formal db queries—have a known, precise syntax and are executed automatically by the db management system, leaving only the work of displaying the computed results in some appropriate linguistic, tabular or graphical form.
Numerous systems have been built since then, aimed at applications such as navy data on ships and their deployment (Ladder: Hendrix et al. 1978), land-use planning (Damerau 1981), geographic QA (Chat-80: Pereira & Warren 1982), retrieval of company records and product records for insurance companies, oil companies, manufacturers, retailers, banks, etc. (Intellect: Harris 1984), compilation of statistical data concerning customers, services, assets, etc., of a company (Cercone et al. 1993), and many more (e.g., see Androutsopoulos & Ritchie 2000). However, the commercial impact of such systems has remained scant, because they have generally lacked the reliability and some of the functionalities of traditional db access.
Inferential (knowledge-based) question answering
We have noted certain limited inferential capabilities in text-based QA systems and NL front ends for databases, such as the ability to confirm entailment relations between candidate answers and questions, using simple sorts of semantic relations among the terms involved, and the ability to sort or categorize data sets from databases and compute averages or even create statistical charts.
However, such limited, specialized inference methods fall far short of the kind of general reasoning based on symbolic knowledge that has long been the goal in AI question answering. One of the earliest efforts to create a truly inferential QA system was the ENGLAW project of L. Stephen Coles (Coles 1972). ENGLAW was intended as a prototype of a kind of system that might be used by scientists and engineers to obtain information about physical laws. It featured a KB of axioms (in first-order logic) for 128 important physical laws, manually coded with the aid of a reference text. Questions (such as “In the Peltier Effect, does the heat developed depend on the direction of the electric current?”) were rendered into logic via a transformational grammar parser, and productions (aided by various Lisp functions) that map phrase patterns to logical expressions. The system was not developed to the point of practical usefulness, but its integration of reasoning and NLP technologies and its methods of selectively retrieving axioms for inferential QA were noteworthy contributions.
An example of a later larger-scale system aimed at practical goals was BBN's JANUS system (Ayuso et al. 1990). This was intended for naval battle management applications, and could answer questions about the locations, readiness, speed and other attributes of ships, allowing for change with the passage of time. It mapped English queries to a very expressive initial representation language with an “intension” operator to relate formulas to times and possible worlds, and this was in turn mapped into the NIKL description logic, which proved adequate for the majority of inferences needed for the targeted kinds of QA.
Jumping forward in time, we take note of the web-based Wolfram|Alpha (or WolframAlpha) answer engine, developed by Wolfram Research and consisting of 15 million lines of Mathematica code grounded in curated data bases, models, and algorithms for thousands of different domains. (Mathematica is a mathematically oriented high-level programming language developed by the British scientist Stephen Wolfram.) The system is tilted primarily towards quantitative questions (e.g., “What is the GDP of France?”, or “What is the surface area of the Moon?”) and often provides charts and graphics along with more direct answers. The interpretation of English queries into functions applied to various known objects is accomplished with the pattern matching and symbol manipulation capabilities of Mathematica. However, the comprehension of English is not particularly robust at the time of writing. For example “How old was Lincoln when he died?”, “At what age did Lincoln die?” and other variants were not understood, though in many cases of misunderstanding, Wolfram|Alpha displays enough retrieved information to allow inference of an answer. A related shortcoming is that Wolfram|Alpha's quantitative skills are not supplemented with significant qualitative reasoning skills. For example, “Was Socrates a man?” (again, at the time of writing) prompts display of summary information about Socrates, including an image, but no direct answer to the question. Still, Wolfram|Alpha's quantitative abilities are not only interesting in stand-alone mode, but also useful as augmentations of search engines (such as Microsoft Bing) and of voice-based personal assistants such as Apple's Siri (see below).
Another QA system enjoying wide recognition because of its televised victory in the Jeopardy! quiz show is IBM's “Watson” (Ferrucci 2012; Ferrucci et al. 2010; Baker 2011). Like Wolfram|Alpha, this is in a sense a brute force program, consisting of about a million lines of code in Java, C++, Prolog and other languages, created by a core team of 20 researchers and software engineers over the course of three years. The program runs 3000 processes in parallel on ninety IBM Power 750 servers, and has access to 200 million pages of content from sources such as Wordnet, Wikipedia (and its structured derivatives YAGO and DBpedia), thesauri, newswire articles, and literary texts, amounting to several terabytes of human knowledge. (This translates into roughly 1010 clausal chunks—a number likely to be around 2 orders of magnitude greater than the number of basic facts over which any one human being disposes.)
Rather than relying on any single method of linguistic or semantic analysis, or method of judging relevance of retrieved passages and textual “nuggets” therein, Watson applies multiple methods to the questions and candidate answers, including methods of question classification, focal entity detection, parsing, chunking, lexical analysis, logical form computation, referent determination, relation detection, temporal analysis, and special methods for question-answer pairs involving puns, anagrams, and other twists common in Jeopardy!. Different question analyses are used separately to retrieve relevant documents, and to derive, analyze and score potential answers from passages and sentences in those documents. In general, numerous candidate answers to a question are produced, and their analyses provide hundreds of features whose weights for obtaining ranked answers with corresponding confidence levels are learned by ML methods applied to a corpus of past Jeopardy! questions and answers (or officially, answers and questions, according to the peculiar conceit of the Jeopardy! protocol). Watson's wagers are based on the confidence levels of its potential answers and a complex regression model.
How well does Watson fit under our heading of inferential, knowledge-based QA? Does it actually understand the questions and the answers it produces? Despite its impressive performance against Jeopardy! champions, Watson reasons, and understands English in only very restricted senses. The program exploits the fact that the target of a Jeopardy! question is usually a named entity, such as Jimmy Carter, Islamabad, or Black Hole of Calcutta, though other types of phrases are occasionally targeted. Watson is likely to find multiple sentences that mention a particular entity of the desired type, and whose syntactic and semantic features are close to the features of the question, thereby making the named entity a plausible answer without real understanding of the question. For example, a “recent history” question asking for the president under whom the US gave full recognition to Communist China (Ferrucci 2012) might well zero in on such sentences as
Although he was the president who restored full diplomatic relations with China in 1978, Jimmy Carter has never visited that country … (New York Times, June 27, 1981)
or
Exchanges between the two countries' nuclear scientists had begun soon after President Jimmy Carter officially recognized China in 1978. (New York Times, Feb. 2, 2001)
While the links between such sentences and the correct answer are indirect (e.g., dependent on resolving he and who to Jimmy Carter, and associating restored diplomatic relations with recognized, and Communist China with China), correct analysis of those links is not a requirement for success—it is sufficient for the cluster of sentences favoring the answer Jimmy Carter (in virtue of their word and phrasal content and numerous other features) to provide a larger net weight to that answer than any competing clusters. This type of statistical evidence combination based on stored texts seems unlikely to provide a path to the kind of understanding that even first-graders betray in answering simple commonsense questions, such as “How do people keep from getting wet when it rains?”, or “If you eat a cookie, what happens to the cookie?” At the same time, vast data banks utilized in the manner of Watson can make up for inferential weakness in various applications, and IBM is actively redeveloping Watson as a resource for physicians, one that should be able to provide diagnostic and treatment possibilities that even specialists may not have at their fingertips. In sum, however, the goal of open-domain QA based on genuine understanding and knowledge-based reasoning remains largely unrealized.
Voice-based web services and assistants
Voice-based services, especially on mobile devices, are a rapidly expanding applications area. Services range from organizers (for grocery lists, meeting schedules, reminders, contact lists, etc.), to in-car “infotainment” (routing, traffic conditions, hazard warnings, iTunes selection, finding nearby restaurants and other venues, etc.), to enabling use of other miscellaneous apps such as email dictation, dialing contacts, financial transactions, reservations and placement of orders, Wikipedia access, help-desk services, health advising, and general question answering. Some of these services (such as dialing and iTunes selection) fall into the category of hands-free controls, and such controls are becoming increasingly important in transport (including driverless or pilotless vehicles), logistics (deployment of resources), and manufacturing. Also chatbot technology and companionable dialogue agents (as discussed in section 10.5) are serving as general backends to more specific voice-based services.
The key technology in these services is of course speech recognition, whose accuracy and adaptability has been gradually increasing. The least expensive, narrowly targeted systems (e.g., simple organizers) exploit strong expectations about user inputs to recognize, interpret and respond to those inputs; as such they resemble menu-driven systems. More versatile systems, such as car talkers that can handle routing, musical requests, searches for venues, etc., rely on more advanced dialogue management capabilities. These allow for topic switches and potentially for the attentional state of the user (e.g., delaying answering a driver's question if the driver needs to attend to a turn). The greatest current “buzz” surrounds advanced voice-based assistants, notably iPhone's Siri (followed by Android's Iris, True Knowledge's Evi, Google Now, and others). While previous voice control and dictation systems, like Android's Vlingo, featured many of the same functionalities, Siri adds personality and improved dialogue handling and service integration—users feel that they are interacting with a lively synthetic character rather than an app. Besides Nuance SR technology, Siri incorporates complex techniques that were to some extent pushed forward by the Calo (Cognitive Assistant that Learns and Organizes) project carried out by SRI International and multiple universities from 2003–2008 (Ambite et al. 2006; CALO [see Other Internet Resources]). These techniques include aspects of NLU, ML, goal-directed and uncertain inference, ontologies, planning, and service delegation. But while delegation to web services, including Wolfram|Alpha QA, or chatbot technology provides considerable robustness, and there is significant reasoning about schedules, purchasing and other targeted services, general understanding is still very shallow, as users soon discover. Anecdotal examples of serious misunderstandings are “Call me an ambulance” eliciting the response “From now on I will call you ‘an ambulance’”. However, the strong interest and demand in the user community generated by these early (somewhat) intelligent, quite versatile assistants is likely to intensify and accelerate research towards ever more life-like virtual agents, with ever more understanding and common sense.
10.8 Collaborative problem solvers and intelligent tutors
We discuss collaborative problem solving systems (also referred to as “mixed-initiative” or “task-oriented” dialogue systems) and tutorial dialogue systems (i.e., tutorial systems in which dialogue plays a pivotal role) under a common heading because both depend on rather deep representations or models of the domains they are aimed at as well as the mental state of the users they interact with.
However, we should immediately note that collaborative problem solving systems typically deal with much less predictable domain situations and user inputs than tutorial systems, and accordingly the former place much greater emphasis on flexible dialogue handling than the latter. For example, collaborators in emergency evacuation (Ferguson and Allen 1998, 2007) need to deal with a dynamically changing domain, at the same time handling the many dialogue states that may occur, depending on the participants' shared and private beliefs, goals, plans and intentions at any given point. By contrast, in a domain such as physics tutoring (e.g., Jordan et al. 2006; Litman and Silliman 2004), the learner can be guided through a network of learning goals with authored instructions, and corresponding to those goals, finite-state dialogue models can be designed that classify student inputs at each point in a dialogue and generate a prepared response likely to be appropriate for that input.
It is therefore not surprising that tutorial dialogue systems are closer to commercial practicality, with demonstrated learning benefits relative to conventional instruction in various evaluations, than collaborative problem solving systems for realistic applications. Tutorial dialogue systems have been built for numerous domains and potential clienteles, ranging from K-12 subjects to computer literacy and novice programming, qualitative and quantitative physics, circuit analysis, operation of machinery, cardiovascular physiology, fire damage control on ships, negotiation skills, and more (e.g., see Boyer et al. 2009; Pon-Barry et al. 2006). Among the most successful tutorial systems are reading tutors (e.g., Mostow and Beck 2007; Cole et al. 2007), since the materials presented to the learner (in a “scaffolded” manner) are relatively straightforward to design in this case, and the responses of the learner, especially when they consist primarily of reading presented text aloud, are relatively easy to evaluate. For the more ambitious goal of fostering reading comprehension, the central problem is to design dialogues so as to make the learner's contributions predictable, while also making the interaction educationally effective (e.g., Aist and Mostow 2009).
Some tutoring systems, especially ones aimed at children, use animated characters to heighten the learner's sense of engagement. Such enhancements are in fact essential for systems aimed at learners with disabilities like deafness (where mouth and tongue movements of the virtual agent observed by the learner can help with articulation), autism, or aphasia (Massaro et al. 2012; Cole et al. 2007). As well, if tutoring is aimed specifically at training interpersonal skills, implementation of life-like characters (virtual humans) becomes an indispensable part of system development (e.g., Core et al. 2006; Campbell et al. 2011).
Modeling the user's state of mind in tutoring systems is primarily a matter of determining which of the targeted concepts and skills have, or have not yet, been acquired by the user, and diagnosing misunderstandings that are likely to have occurred, given the session transcript so far. Some recent experimental systems can also adapt their strategies to the user's apparent mood, such as frustration or boredom, as might be revealed by the user's inputs, tone of voice, or even facial expressions or gestures analyzed via computer vision. Other prototype systems can be viewed as striving towards more general mental modeling, by incorporating ideas and techniques from task-oriented dialogue systems concerning dialogue states, dialogue acts, and deeper language understanding (e.g., Callaway et al. 2007).
In task-oriented dialogue systems, as already noted, dialogue modeling is much more challenging, since such systems are expected not only to contribute to solving the domain problem at hand, but to understand the user's utterances, beliefs, and intentions, and to hold their own in a human-like, mixed-initiative dialogue. This requires domain models, general incremental collaborative planning methods, dialogue management that models rational communicative interaction, and thorough language understanding (especially intention recognition) in the chosen domain. Prototype systems have been successfully built for domains such as route planning, air travel planning, driver and pedestrian guidance, control and operation of external devices, emergency evacuation, and medication advising (e.g., Allen et al. 2006; Rich and Sidner 1998; Bühler and Minker 2011; Ferguson and Allen 1998, 2007), and these hold very significant practical promise. However, systems that can deal with a variety of reasonably complex problems, especially ones requiring broad commonsense knowledge about human cognition and behavior, still seem out of reach at this time.
10.9 Language-enabled robots
As noted at the beginning of section 10, robots are beginning to be equipped with web services, question answering abilities, chatbot techniques (for fall-back and entertainment), tutoring functions, and so on. The transfer of such technologies to robots has been slow, primarily because of the very difficult challenges involved in just equipping a robot with the hardware and software needed for basic visual perception, speech recognition, exploratory and goal-directed navigation (in the case of mobile robots), and object manipulation. However, the keen public interest in intelligent robots and their enormous economic potential (for household help, eldercare, medicine, education, entertainment, agriculture, industry, search and rescue, military missions, space exploration, and so on) will surely continue to energize the drive towards greater robotic intelligence and linguistic competence.
A good sense of the state of the art and difficulties in human-robot dialogue can be gained from (Scheutz et al. 2011). Some of the dialogue examples presented there, concerning boxes and blocks, are reminiscent of Winograd's shrdlu, but they also exhibit the challenges involved in real interaction, such as the changing scenery as the robot moves, speech recognition errors, disfluent and complex multi-clause utterances, perspective-dependent utterances ( “Is the red box to the left of the blue box?”), and deixis (“Go down there”). In addition, all of this must be integrated with physical action planned so as to fulfill the instructions as understood by the robot. While the ability of recent robots to handle these difficulties to some degree is encouraging, many open problems remain, such as the problems of speech recognition in the presence of noise, better, broader linguistic coverage, parsing, and dialogue handling, adaptation to novel problems, mental modeling of the interlocutor and other humans in the environment, and greater general knowledge about the world and the ability to use it for inference and planning (both at the domain level and the dialogue level).
While task-oriented robot dialogues involve all these challenges, we should note that some potentially useful interactions with “talking” robots require little in the way of linguistic skills. For example, the Rubi robot described in (Movellan et al. 2009), displayed objects on its screen-equipped “chest” to toddlers, asking them to touch and name the objects. This resulted in improved word learning by the toddlers, despite the simplicity of the interaction. Another example of a very successful talking robot with no real linguistic skills was the “museum tour guide” Rhino (Burgard et al. 1999). Unlike Rubi it was able to navigate among unpredictably moving humans, and kept its audience engaged with its prerecorded messages and with a display of its current goals on a screen. In the same way, numerous humanoid robots (for example, Honda's Asimo) under past and present development across the world still understand very little language and rely mostly on scripted output. No doubt their utility and appeal will continue to grow, thanks to technologies like those mentioned above—games, companionable agent systems, voice-based apps, tutors, and so on; and these developments will also fuel progress on the deeper aspects of perception, motion, manipulation, and meaningful dialogue.
Bibliography
- Aist, G. & J. Mostow, 2009, “Predictable and educational spoken dialogues: Pilot results,” in Proceedings of the 2009 ISCA Workshop on Speech and Language Technology in Education (SLaTE 2009). Birmingham, UK: University of Birmingham. [Aist & Mostow 2009 available online (pdf)]
- Allen, J.F., 1995, Natural Language Understanding, Redwood City: Benjamin/Cummings.
- Allen J., W. de Beaumont, L. Galescu, J. Orfan, M. Swift, and C.M. Teng, 2013, “Automatically deriving event ontologies for a commonsense knowledge base,” in Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013), University of Potsdam, Germany, March 19–22. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Allen et al. 2013 available online (pdf)]
- Allen, J., G. Ferguson, N. Blaylock, D. Byron, N. Chambers, M. Dzikovska, L. Galescu, and M. Swift, 2006, “Chester: Towards a personal medical advisor,” Biomedical Informatics, 39(5): 500–513.
- Allen, J.F. and C.R. Perreault, 1980, “A plan-based analysis of indirect speech acts,” Computational Linguistics, 6(3–4): 167–182.
- Ambite, J.-L., V.K. Chaudhri, R. Fikes, J. Jenkins, S. Mishra, M. Muslea, T. Uribe, and G. Yang, 2006, “Design and implementation of the CALO query manager,” 21st National Conference on Artificial Intelligence (AAAI-06), July 16–20, Boston, MA; Menlo Park, CA: AAAI Press, 1751–1758.
- Andersen, P.M., P.J. Hayes, A.K. Huettner, L.M. Schmandt, I.B. Nirenburg, and S.P. Weinstein, 1992, “Automatic extraction of facts from press releases to generate news stories,” in Proceedings of the 3rd Conference on Applied Natural Language Processing (ANLC '92), Trento, Italy, March 31–April 3. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 170–177. [Andersen et al. 1992 available online (pdf)]
- Anderson, J., 1983, The Architecture of Cognition, Mahwah, NJ: Lawrence Erlbaum.
- –––, 1993, Rules of the Mind, Hillsdale, NJ: Lawrence Erlbaum.
- Anderson, J. & G. Bower, 1973, Human Associative Memory, Washington, DC: Winston.
- Androutsopoulos, I. and G. Ritchie, 2000, “Database Interfaces,” R. Dale, H. Somers, and H. Moisl (eds.), Handbook of Natural Language Processing, Chapter 9, Boca Raton, FL: CRC Press.
- Asher, N. and A. Lascarides, 2003, Logics of Conversation (Studies in Natural Language Processing), New York: Cambridge University Press.
- Auer, S., C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Zachary Ives, 2007, “DBpedia: a nucleus for a web of open data,” in Proceedings of the 6th International Semantic Web Conference (ISWC 2007), Nov. 11–15, Busan, Korea. [Auer et al. 2007 available online (pdf)
- Austin, J.L., 1962, How to Do Things with Words: The William James Lectures Delivered at Harvard University in 1955, J.O. Urmson (ed.), Oxford: Clarendon Press.
- Ayuso, D., M. Bates, R. Bobrow, M. Meteer, L. Ramshaw, V. Shaked, and R. Weischedel, 1990, “Research and development in natural language understanding as part of the strategic computing program,” BBN Report No. 7191, BBN Systems and Technologies, Cambridge, MA.
- Baars, B.J., 1997, In the Theater of Consciousness: The Workspace of the Mind, New York: Oxford University Press.
- Bach, E., 1976, “An extension of classical transformational grammar,” in Proceedings of the 1976 Conference on Linguistic Metatheory, Michigan State University, 183–224. [Bach 1976 available online]
- Bach, E., R. Oehrle, and D. Wheeler (eds.), 1987, Categorial Grammars and Natural Language Structures, Dortrecht: D. Reidel.
- Baker, S., 2011, Final Jeopardy, Boston: Houghton Mifflin Harcourt.
- Banarescu, L., C. Bonial, S. Cai, M. Georgescu, K. Griffitt, U. Hermjakob, K. Knight, K. Koehn, M. Palmer, and N. Schneider, 2013, “Abstract Meaning Representation for Sembanking”, in Proceedings of the 7th Linguistic Annotation Workshop & Interoperability with Discourse, Sofia, Bulgaria, Aug. 8–9. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Banarescu et al. 2013 available online (pdf)]
- Banko, M., M.J. Cafarella, S. Soderland, M. Broadhead, and O. Etzioni, 2007. “Open information extraction from the Web,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-07), Hyderabad, India, January 6–12. [Banko et al. 2007 available online (pdf)]
- Bar-Hillel, Y., 1960, “The present status of automatic translation of languages,” Advances in Computers, 1: 91–163.
- Barker, C., 2004, “Continuations in natural language”, in Hayo Thielecke (ed.), Proceedings of the 4th ACM SIGPLAN Continuations Workshop (CW'04), Venice, Italy, Jan. 17. Birmingham, UK: University of Birmingham. [Barker 2004 available online]
- Barker, K., B. Porter, and P. Clark, 2001, “A library of generic concepts for composing knowledge bases,” in Proceedings of the 1st International Conference on Knowledge Capture, Victoria, B.C., Canada, October 21–23. New York, NY: ACM, pp. 14–21. [Barker, Porter, and Clark 2001 preprint available online]
- Barnden, J.A., 2001, “Uncertainty and conflict handling in the ATT-Meta context-based system for metaphorical reasoning,” in Proceedings of the 3rd International Conference on Modeling and Using Context, V. Akman, P. Bouquet, R. Thomason, and R.A. Young (eds.), Lecture Notes in Artificial Intelligence, Vol. 2116, Berlin: Springer, pp. 15–29.
- –––, 2006, “Artificial intelligence, figurative language, and cognitive linguistics,” in G. Kristiansen et al. (eds.), Cognitive Linguistics: Current Applications and Future Perspectives, Berlin: Mouton de Gruyter, 431–459.
- Barwise, J. and R. Cooper, 1981, “Generalized quantifiers and natural language,” Linguistics and Philosophy, 4(2): 159–219.
- Barwise, J., and J. Perry, 1983, Situations and Attitudes, Chicago: University of Chicago Press.
- Bengio, Y., 2008, “Neural net language models,” Scholarpedia, 3(1): 3881. [Bengio 2008 available online]
- Bickmore, T., D. Schulman, and C. Sidner, 2011, “Modeling the intentional structure of health behavior change dialogue,” Journal of Biomedical Informatics, 44: 183–197.
- Bishop, C.M., 2006, Pattern Recognition and Machine Learning, New York: Springer.
- Blutner, R., 2004, “Nonmonotonic inferences and neural networks”, Synthese, 141(2): 143–174.
- Bobrow, D.G., 1968, “Natural language input for a computer problem-solving system,” in M. Minsky (ed.), Semantic Information Processing, Cambridge, MA: MIT Press, 146–226.
- Boser, B.E., I.M. Guyon, and V.N. Vapnik, 1992, “A training algorithm for optimal margin classifiers,” in D. Haussler (ed.), 5th Annual ACM Workshop on COLT, Pittsburgh, PA: ACM Press, 144–152.
- Bouaud, J., B. Bachimont, and P. Zweigenbaum, 1996, “Processing metonymy: a domain-model heuristic graph traversal approach,” in Proceedings of the 16th International Conference on Computational Linguistics (COLING'96), Center for Sprogteknologi Copenhagen, Denmark, Aug. 5–9. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 137–142. [Bouaud, Bachimont, and Zweigenbaum 1996 available online (pdf)]
- Bourne, C.P. and T.B. Hahn, 2003, A History of Online Information Services, 1963–1976, Cambridge, MA: MIT Press.
- Boyer, K.E., E.Y. Ha, M.D. Wallis, R. Phillips, M.A. Vouk, and J.C. Lester, 2009, “Discovering tutorial dialogue strategies with Hidden Markov Models”, in Proceedings of the 14th International Conference on Artificial Intelligence in Education (AIED 2009), Brighton, U.K.: IOS Press, pp. 141–148.
- Brakel, P. and S.L. Frank, 2009, “Strong systematicity in sentence processing by simple recurrent networks,” in N.A. Taatgen and H. van Rijn (eds.), Proceedings of the 31st Annual Conference of the Cognitive Science Society, July 30 – Aug. 1, VU University Amsterdam; Red Hook, NY: Curran Associates, Inc., pp. 1599–1604.
- Brown, J.S. and R.R. Burton, 1975, “Multiple representations of knowledge for tutorial reasoning,” in D.G. Bobrow and A. Collins (eds.), Representation and Understanding, Academic Press, New York, 311–349.
- Browne, A. and R. Sun, 2001, “Connectionist inference models”, Neural Networks, 14: 1331–1355.
- Browne, A. and R. Sun, 1999, “Connectionist variable binding”, Expert Systems, 16(3): 189–207.
- Bühler, D. and W. Minker, 2011, Domain-Level Reasoning for Spoken Dialogue Systems, Boston, MA: Springer.
- Bunt, H.C., 1985, Mass Terms and Model-Theoretic Semantics, Cambridge, UK and New York: Cambridge University Press.
- Burgard, W., A.B. Cremers, D. Fox, D. Hahnel, G. Lakemeyer, D. Schulz, W. Steiner, and S. Thrun, 1999, “Experiences with an interactive museum tour-guide robot,” Articial Intelligence, 114(1–2): 3–55.
- Bylander, T., 1994, “The computational complexity of propositional STRIPS planning,” Artificial Intelligence, 69: 165–204.
- Callaway, C., M. Dzikovska, E. Farrow, M. Marques-Pita, C. Matheson, and J. Moore, 2007, “The Beetle and BeeDiff tutoring systems,” in Proceedings of the 2007 Workshop on Spoken Language Technology for Education (SLaTE), Farmington, PA, Oct. 1–3. Carnegie Mellon University and ISCA Archive. [Callaway et al. 2007 available online]
- Campbell, J., M. Core, R. Artstein, L. Armstrong, A. Hartholt, C. Wilson, K. Georgila, F. Morbini, E. Haynes, D. Gomboc, M. Birch, J. Bobrow, H.C. Lane, J. Gerten, A. Leuski, D. Traum, M. Trimmer, R. DiNinni, M. Bosack, T. Jones, R.E. Clark, and K.A. Yates, 2011, “Developing INOTS to support interpersonal skills practice,” in Proceedings of the 32nd Annual IEEE Aerospace Conference (IEEEAC), Big Sky, MT, March 5–12, Institute of Electrical and Electronics Engineers (IEEE), 3222–3235.
- Carbonell, J., 1980, “Metaphor—a key to extensible semantic analysis,” in N.K. Sondheimer (ed.), Proceedings of the 18th Meeting of the Association for Computational Linguistics (ACL'80), University of Pennsylvania, PA, June 19–22. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 17–21. [Carbonell 1980 available online (pdf)]
- Carlson, G.N., 1977, Reference to Kinds in English, Doctoral Dissertation, University of Massachusetts, Amherst, MA. Also New York: Garland Publishing, 1980.
- –––, 1982, “Generic terms and generic sentences,” Journal of Philosophical Logic, 11: 145–181.
- –––, 2011, “Generics and habituals,” in C. Maienborn, K. von Heusinger, and P. Portner (eds.), Semantics: An International Handbook of Natural Language Meaning, Berlin: Mouton de Gruyter.
- Carlson, G.N. and F.J. Pelletier 1995, The Generic Book, Chicago: University of Chicago Press.
- Carpenter, B., 1997, Type-Logical Semantics, Cambridge, MA: MIT Press.
- Cercone, N., P. McFetridge, F. Popowich, D. Fass, C. Groeneboer, and G. Hall, 1993, “The systemX natural language interface: design, implementation, and evaluation,” Tech. Rep. CSS-IS TR 93-03, Centre for Systems Science, Simon Fraser University, Burnaby, BC, Canada.
- Chambers, N. and D. Jurafsky, 2009, “Unsupervised learning of narrative schemas and their participants,” in Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics (ACL-09), Singapore, Aug. 2–7. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Chambers and Jurafsky 2009 available online (pdf)]
- Chater, N. and M. Oaksford (Eds.), 2008, The Probabilistic Mind: Prospects for Rational Models of Cognition, Oxford University Press.
- Chen, P., W. Ding, C. Bowes, and D. Brown, 2009, “A fully unsupervised word sense disambiguation method using dependency knowledge,” in Proceedings of the Annual Conference of the North American Chapter of the ACL (NAACL'09), Boulder, CO, June. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 28–36. [Chen et al. 2009 available online (pdf)]
- Chomsky, N., 1956, “Three models for the description of language,” IRE Transactions on Information Theory, 2: 113–124. [Chomsky 1956 available online (pdf)]
- –––, 1957, Syntactic Structures, Paris: Mouton.
- Clark, A., C. Fox, and S. Lappin (eds), 2010, The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
- Clarke, Daoud, 2012, “A context-theoretic framework for compositionality in distributional semantics,” Computational Linguistics, 38(1): 41–71.
- Cohen, A., 2002, “Genericity”, in F. Hamm and T.E. Zimmermann (eds.), Semantics, vol. 10, Hamburg: H. Buske Verlag, 59–89.
- Cohen, S.B., K. Stratos, M. Collins, D.P. Foster, and L. Ungar, 2013, “Experiments with spectral learning of Latent-Variable PCFGs,” Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2013), June 9–13, Atlanta, GA. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Cohen et al. 2013 available online (pdf)]
- Cohen, P.R. and R. Perreault, 1979, “Elements of a plan based theory of speech acts,” Cognitive Science, 3(3): 177–212.
- Cole, R., B. Wise, and S. van Vuuren, 2007, “How Marni teaches children to read,” Educational Technology, 47(1): 14–18.
- Coles, L.S., 1972, “Techniques for Information Retrieval Using an Inferential Question-Answering System with Natural-Language Input”, Technical Note 74, SRI Project 8696, SRI International.
- Conesa, J., V.C. Storey, and V. Sugumaran, 2010, “Usability of upper-level ontologies: the case of ResearchCyc,” Data & Knowledge Engineering, 69(4): 343–356.
- Copestake, A., D. Flickinger, I. Sag, and C. Pollard, 2005, “Minimal Recursion Semantics: An introduction,” Research in Language and Computation, 3(2–3): 281–332.
- Core, M., D. Traum, H.C. Lane, W. Swartout, S. Marsella, J. Gratch, and M. van Lent, 2006, “Teaching negotiation skills through practice and reflection with virtual humans,” Simulation: Transactions of the Society for Modeling and Simulation, 82: 685–701.
- Cortes, C. and V.N. Vapnik, 1995, “Support-vector networks”, Machine Learning, 20(3): 273–297.
- Cour, T., C. Jordan, E. Miltsakaki, and B. Taskar, 2008, “Movie/Script: alignment and parsing of video and text transcription,” European Conference on Computer Vision (ECCV), October, Marseille, France.
- Crocker, M.W., 2010, “Computational Psycholinguistics”, in A. Clark, C. Fox, and S. Lappin (eds), The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
- Crouch, R., 1995, “Ellipsis and quantification: a substitutional approach,” in Proceedings of the European Chapter of the Association for Computational Linguistics (EACL'95), University College Dublin, March 27–31. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 229–236. [Crouch 1995 available online (pdf)]
- Dagan, I., R. Bar-Haim, I. Szpektor, I. Greental, and E. Shnarch, 2008, “Natural language as the basis for meaning representation and inference,” in A. Gelbukh (ed.), Computational Linguistics and Intelligent Text Processing, Lecture Notes in Computer Science 4919, Berlin: Springer, 151–170.
- Dalrymple, M., S.M. Shieber, and F.C.N. Pereira, 1991, “Ellipsis and higher-order unification,” Linguistics and Philosophy, 14: 399–452.
- Damásio, A.R., 1994, Descartes' Error: Emotion, Reason, and the Human Brain, Kirkwood, NY: Putnam Publishing.
- Damerau, F.J., 1981, “Operating statistics for the Transformational Question Answering System,” American Journal of Computational Linguistics, 7(1): 30–42.
- Davidson, D., 1967a, “The logical form of action sentences”, in N. Rescher (ed.), The Logic of Decision and Action, Pittsburgh, PA: University of Pittsburgh Press.
- d'Avila Garcez, A.S., 2004. “On Gabbay's fibring methodology for Bayesian and neural networks”, in D. Gillies (ed.), Laws and Models in Science, workshop sponsored by the European Science Foundation (ESF), King's College Publications.
- DeJong, G.F., 1982, “An overview of the FRUMP system,” in W.G. Lehnert and M.H. Ringle (eds.), Strategies for Natural Language Processing, Erlbaum, 149–176.
- Della Pietra, S., V. Della Pietra, and J. Lafferty, 1997, “Inducing features of random fields,” Machine Intelligence, 19(4): 380–393.
- de Salvo Braz, R., R. Girju, V. Punyakanok, D. Roth, and M. Sammons, 2005, “An inference model for semantic entailment and question answering,” in Proceedings of the American Association for Artificial Intelligence (AAAI-05), Pittsburgh, PA, July 9–13. Menlo Park, CA: AAAI Press, pp. 1043–1049.
- Dowty, D., 1991, “Thematic proto-roles and argument selection,” Language, 67(3): 547–619.
- Duda, R.O. and P.E. Hart, 1973, Pattern Classification and Scene Analysis, New York: Wiley.
- Duda, R.O., P.E. Hart, and D.G. Stork, 2001, Pattern Classification, New York: Wiley.
- Dyer, M.G., 1983, In-Depth Understanding, Cambridge, MA: MIT Press.
- Earley, J., 1970, “An efficient context-free parsing algorithm,” Communications of the ACM, 13(2): 94–102.
- Faaborg, A., W. Daher, H. Lieberman, and J. Espinosa, 2005, “How to wreck a nice beach you sing calm incense,” in R.St. Amant, J. Riedl, and A. Jameson (eds.), Proceedings of the International Conference on Intelligent User Interfaces (IUI-05), San Diego, CA, January 10–13. ACM Press. [Faaborg et al. 2005 preprint available (pdf)]
- Falkenhainer, B., K.D. Forbus, and D. Gentner, 1989, “The Structure-Mapping Engine: algorithm and examples,” Artificial Intelligence, 41: 1–63.
- Fan, J., K. Barker, and B. Porter, 2009, “Automatic interpretation of loosely encoded input,” Artificial Intelligence 173(2): 197–220.
- Fass, D., 1991, “Met*: a method for discriminating metonymy and metaphor by computer,” Computational Linguistics, 17(1): 49–90.
- Feldman, J.A., 2006, From Molecule to Metaphor: A Neural Theory of Language, Cambridge, MA: Bradford Books, MIT Press.
- Feldman, J.A. and D.H. Ballard ,1982, “Connectionist models and their properties,” Cognitive Science, 6: 205–254.
- Ferguson, G. and J.F. Allen, 1998, “TRIPS: An integrated intelligent problem-solving assistant,” in Proceedings of the 15th National Conference on Artificial Intelligence (AAAI-98). Menlo Park, CA: AAAI Press, pp. 567–573.
- –––, 2007, “Mixed-initiative systems for collaborative problem solving,” AI Magazine, 28(2): 23–32.
- Ferrucci, D.A., 2012, “This is Watson,” IBM Journal of Research and Development, 56(3–4).
- Ferrucci, D., E. Brown, J. Chu-Carroll, J. Fan, D. Gondek, A.A Kalyanpur, A. Lally, J.W. Murdock, E. Nyberg, J. Prager, N. Schlaefer, and C. Welty, 2010, “Building Watson: An overview of the DeepQA project,” AI Magazine, 31(3): 59–79.
- Fine, A.B., T.F. Jaeger, T.A. Farmer, and T. Qian, 2013, “Rapid expectation adaptation during syntactic comprehension,” PLoS ONE, 8(1): e77661.
- Fleischman, M., and D. Roy, 2005, “Intentional context in situated language learning,” in 9th Conference on Computational Natural Language Learning (CoNLL-2005), Ann Arbor, MI, June 29–30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Fleischman and Roy 2005 available online (pdf)]
- Gärdenfors, P., 2000, Conceptual Spaces: The Geometry of Thought, Cambridge, MA: MIT Press.
- Ge, R. and R.J. Mooney, 2009, “Learning a compositional semantic parser using an existing syntactic parser,” in Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing (ACL-IJCNLP 2009), Suntec, Singapore, August. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 611–619. [Ge and Mooney 2009 available online (pdf)]
- Geib, C.W., 2004, “Assessing the complexity of plan recognition,” in Proceedings of the 19th National Conference on Artifical intelligence (AAAI'04), San Jose, CA, July 25–29. Menlo Park, CA: AAAI Press, pp. 507–512.
- Glickman, O. and I. Dagan, 2005, “A probabilistic setting and lexical cooccurrence model for textual entailment,” in Proceedings of ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, MI, June 30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Glickman and Dagan 2005 available online (pdf)].
- Gluck, M.A. and D.E. Rumelhart, 1990, Neuroscience and Connectionist Theory, Hillsdale, NJ: Lawrence Erlbaum.
- Goldberg, A.E., 2003, “Constructions: a new theoretical approach to language,” Trends in Cognitive Sciences, 7(5): 219–224.
- Goldman, R.P. and E. Charniak, 1991, “Probabilistic text understanding,” in Proceedings of the 3rd International Workshop on AI and Statistics, Fort Lauderdale, FL. Also published in D.J. Hand (ed.), 1993, Artificial Intelligence Frontiers in Statistics: AI and Statistics III, London, UK: Chapman & Hall.
- Gordon, J. and L.K. Schubert, 2010, “Quantificational sharpening of commonsense knowledge,” Common Sense Knowledge Symposium (CSK-10), AAAI 2010 Fall Symposium Series, November 11-13, Arlington, VA, AAAI Technical Report FS-10-02, Menlo Park, CA: AAAI Press.
- Gregory, H. and S. Lappin, 1997, “A computational model of ellipsis resolution,” in Proceedings of the Conference on Formal Grammar (Linguistic Aspects of Logical and Computational Perspectives on Language), 9th ESSLLI, Aix-en-Provence, France: European Summer School, August 11–27.
- Grice, H.P., 1968, “Utterer's meaning, sentence meaning and word meaning,” Foundations of Language, 4: 225–242.
- Groenendijk, J. and M. Stokhof, 1991, “Dynamic predicate logic,” Linguistics and Philosophy, 14(1): 39–100.
- Grosz, B.J. and C.L. Sidner, 1986, “Attention, intentions, and the structure of discourse,” Computational Linguistics, 12(3, July-September): 175–204.
- Hadamard, J., 1945, The Psychology of Invention in the Mathematical Field, Princeton, NJ: Princeton University Press.
- Haghighi, A. and D. Klein, 2010, “Coreference resolution in a modular, entity-centered model,” in Proceedings of the Annual Conference of the North American Chapter of the ACL (HLT-NAACL 2010), Los Angeles, June. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 385–393. [Haghighi and Klein 2010 available online (pdf)]
- Hardt, D., 1997, “An empirical approach to VP ellipsis,” Computational Linguistics, 23(4): 525–541.
- Harris, L.R., 1984, “Experience with INTELLECT: Artificial Intelligence technology transfer,” AI Magazine, 5(2): 43–50.
- Havasi, C., R. Speer, and J. Alonso, 2007, “ConceptNet 3: a flexible, multilingual semantic network for common sense knowledge,” in N. Nicolov, G. Angelova, and R. Mitkov (eds.), Proceedings of Recent Advances in Natural Language Processing (RANLP-07), Borovets, Bulgaria, Sept. 27–29. Amsterdam:John Benjamins.
- Hearst, M., 1992, “Automatic acquisition of hyponyms from large text corpora,” in Proceedings of the 14th International Conference on Computational Linguistics (COLING-92), Nantes, France, Aug. 23–28. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 539–545. [Hearst 1992 available online (pdf)]
- Heim, I.R., 1982, The Semantics of Definite and Indefinite Noun Phrases, Doctoral dissertaton, University of Massachusetts, Amherst.
- Henderson, J., 1994, “Connectionist syntactic parsing using temporal variable binding,” Journal of Psycholinguistic Research 23(5): 353–379.
- Hendrix, G.G., E.D. Sacerdoti, D. Sagalowicz, and J. Slocum, 1978, “Developing a natural language interface to complex data,” ACM Transactions on Database Systems, 3(2): 105–147.
- Hewitt, C., 1969, “PLANNER: A language for proving theorems in robots,” in D.E. Wlaker and L.M. Norton (eds.), Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI'69), Washington, D.C., May 7–9. Los Altos, CA: William Kaufmann, pp. 295–301.
- Hobbs, J.R., 1979, “Coherence and coreference,” Cognitive Science, 3(1): 67–90.
- –––, 2003, “The logical notation: Ontological promiscuity,” in J.R. Hobbs, Discourse and Inference (in progress). [Hobbs 2003 preprint available online].
- Hobbs, J.R., D.E. Appelt, J. Bear, M. Kameyama, M.E. Stickel, and M. Tyson, 1997, “FASTUS: A cascaded finite-state transducer for extracting information from natural-language text,” in E. Roche and Y. Schabes (eds.), Finite-State Language Processing, Cambridge, MA: MIT Press, 383–406.
- Hobbs, J.R. and A. Gordon, 2005, “Encoding knowledge of commonsense psychology,” in 7th International Symposium on Logical Formalizations of Commonsense Reasoning (Commonsense 2005), Corfu, Greece, May 22–24. [Hobbs and Gordon 2005 available online (pdf)]
- Hobbs, J.R., M.E. Stickel, D.E. Appelt, and P. Martin, 1993, “Interpretation as abduction,” Artificial Intelligence, 63: 69–142.
- Hoffmann, R., S. Amershi, K. Patel, F. Wu, J. Fogarty, and D. Weld, 2009, “Amplifying community content creation with mixed-initiative information extraction,” ACM Conference on Human Factors in Computing Systems (CHI 2009), Boston, MA, April 4–9. New York: ACM Press.
- Hofstadter, D. R. and the Fluid Analogy Research Group, 1995, Fluid Concepts and Creative Analogies: Computer Models of the Fundamental Mechanisms of Thought, New York: Basic Books.
- Hovy, E., 1988, “Planning coherent multisentential text,” in Proceedings of the 26th Annual Meeting of the ACL (ACL'88), Buffalo, NY. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 179–186. [Hovy 1988 available online (pdf)]
- Humphrey, N., 1992, A History of the Mind: Evolution and the Birth of Consciousness, New York: Simon & Schuster.
- Ide, N. and J. Véronis, 1994, “Knowledge extraction from machine-readable dictionaries: An evaluation”, in P. Steffens (ed.), Machine Translation and the Lexicon, Berlin: Springer-Verlag.
- Jackendoff, R.S., 1990, Semantic Structures, Cambridge, MA: MIT Press.
- Johnson-Laird, P.N., 1983, Mental Models: Toward a Cognitive Science of Language, Inference and Consciousness, Cambridge, MA: Harvard University Press.
- Johnston, B. and M.-A. Williams, 2009, “Autonomous learning of commonsense simulations,” in Proceedings of Commonsense 2009, Toronto, Canada, June 1–3. Commonsense Reasoning. [Johnston and Williams 2009 available online (pdf)]
- Jordan, P., M. Makatchev, U. Pappuswamy, K. VanLehn, and P. Albacete, 2006, “A natural language tutorial dialogue system for physics,” in G.C.J. Sutcliffe and R.G. Goebel (eds.), Proceedings of the 19th International Florida Artificial Intelligence Research Society (FLAIRS-06). Menlo Park, CA: AAAI Press.
- Jurafsky, D. and J.H. Martin, 2009, Speech and Language Processing, 2nd edition. Upper Saddle River, NJ: Pearson Higher Education, Prentice-Hall; original edition, 2000, Upper Saddle River, NJ: Pearson Higher Education, Prentice-Hall.
- Kamp, H., 1981, “A theory of truth and semantic representation,” in J. Groenendijk, T. Janssen, and M. Stokhof (eds.), Formal Methods in the Study of Language, Mathematics Center, Amsterdam.
- Kasabov, N., 1996, Foundations of Neural Networks, Fuzzy Systems and Knowledge Engineering, Cambridge, MA: MIT Press.
- Kecman, V., 2001, Learning and Soft Computing, Cambridge, MA: MIT Press.
- Kim, J. and R.J. Mooney, 2012, “Unsupervised PCFG induction for grounded language learning with highly ambiguous supervision,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing and Natural Language Learning (EMNLP-CoNLL ‘12), July 12–14, Jeju, Korea. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Kim and Mooney 2012 available online (pdf)]
- Koehn, Philipp, 2010, Statistical Machine Translation, Cambridge, UK: Cambridge University Press.
- Kosslyn, S.M., 1994, Image and Brain: The Resolution of the Imagery Debate, Cambridge, MA: MIT Press.
- Kuhlmann, M., 2013, “Mildly non-projective dependency grammar,” Computational Linguistics, 39(2): 355–387.
- Lafferty, J., A. McCallum, and F. Pereira, 2001, “Conditional random fields: Probabilistic models for segmenting and labeling sequence data,” in C.E. Brodley and A. Pohoreckyj Danyluk (eds.), International Conference on Machine Learning (ICML), Williams College, MA, June 28–July 1. San Francisco: Morgan Kaufmann.
- Lakoff, G. and M. Johnson, 1980, Metaphors We Live By, Chicago: University of Chicago Press.
- Landman, F., 1991, Structures for Semantics, SLAP 45, Dordrecht: Kluwer.
- Landman, F., 1989, “Groups I & II”, Linguistics and Philosophy, 12(5): 559–605 and 12(6): 723–744.
- –––, 2000, Events and Plurality, Dortrecht: Kluwer.
- Lenat, D., 1995, “CYC: A large-scale investment in knowledge infrastructure,” Communications of the ACM, 38(11): 33–38.
- Lewis, D.K., 1970, “General semantics,” Synthese, 22: 18–67. Reprinted in D. Davidson and G. Harman (eds.), 1972, Semantics of Natural Language, Dortrecht: D. Reidel.
- Lieberman, H., H. Liu, P. Singh, and B. Barry, 2004. “Beating some common sense into interactive applications,” AI Magazine, 25(4): 63–76.
- Lin, D. and P. Pantel, 2001, “DIRT—Discovery of Inference Rules from Text,” in Proceedings of the 7th ACM Conference on Knowledge Discovery and Data Mining (KDD-2001), San Francisco, CA, August 26–29. New York: ACM Digital Library, pp. 323–328.
- Lindsay, R., 1963, “Inferential memory as the basis of machines which understand natural language”, in E. Feigenbaum and J. Feldman (eds.), Computers and Thought, New York: McGraw-Hill.
- Link, G. 1983, “The logical analysis of plurals and mass terms: a lattice-theoretical approach”, in R. Bauerle, C. Schwarze, and and A. von Stechow (eds.), Meaning, Use, and Interpretations of Language, Berlin: de Gruyter.
- Litman, D.J. and S. Silliman, 2004, “ITSPOKE: An intelligent tutoring spoken dialogue system,” in Proceedings of the Human Language Technology Conference: 4th Meeting of the North American Chapter of the Association for Computational Linguistics (HLT/NAACL-04). Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 233–236. [Litman and Silliman 2004 available online (pdf)]
- MacCartney, B. and C.D. Manning, 2009, “An extended model of natural logic,” in Proceedings of the 8th International Conference on Computational Semantics (IWCS-8), Tilburg University, Netherlands. Stroudsburg, PA: Association for Computational Linguistics (ACL). [MacCartney and Manning 2009 available online (pdf)]
- Manger, R., V.L. Plantamura, and B. Soucek, 1994, “Classification with holographic neural networks,” in V.L. Plantamura, B. Soucek, and G. Visaggio (eds.), Frontier Decision Support Concepts, New York: John Wiley and Sons, 91–106.
- Mann, W. and S.A. Thompson, 1987, “Rhetorical structure theory: description and construction of text structures,” in G. Kempen (ed.), Natural Language Generation: Recent Advances in Artificial Intelligence, Psychology, and Linguistics, Dortrecht: Kluwer Academic Publishers, 85–96.
- Mann, W.C. and S.A. Thompson, 1988, “Rhetorical Structure Theory: toward a functional theory of text organization.” Text, 8(3): 243–281.
- Manning, C.D. and H. Schütze, 1999, Foundations of Statistical Natural Language Processing, Cambridge, MA: MIT Press.
- Markert, K. and M. Nissim, 2007, “SemEval-2007 Task 08: metonymy resolution at SemEval-2007,” in Proceedings of SemEval 2007, Prague. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Markert and Nissim 2007 available online (pdf)]
- Martin, J.H., 1990, A Computational Model of Metaphor Interpretation, New York: Academic Press.
- Massaro, D.W., M.M. Cohen, M. Tabain, J. Beskow, and R. Clark, 2012, “Animated speech: Research progress and applications,” in G. Bailly, P. Perrier, and E. Vatiokis-Bateson (eds.), Audiovisual Speech Processing, Cambridge, UK: Cambridge University Press, 309–345.
- May, A., 2012, “Machine translation,” chapter 19 of A. Clark, C. Fox, and S. Lappin (eds.), The Handbook of Computational Linguistics and Natural Language Processing, Chichester, UK: Wiley Blackwell.
- Mayberry, III, M.R. and R. Miikkulainen, 2008, “Incremental nonmonotonic sentence interpretation through semantic self-organization,” Technical Report AI08-12, Dept. of Computer Science, University of Texas, Austin, TX.
- Maybury, M.T. (ed.), 2004, New Directions in Question Answering, Cambridge, MA: AAAI and MIT Press.
- McCarthy, J., 1990, “First order theories of individual concepts and propositions,” in J. McCarthy and V. Lifschitz (eds.), 1990, Formalizing Common Sense: Papers by John McCarthy, 119–141. (Note: An earlier version appeared in J.E. Hayes, D. Michie, and L. Mikulich (eds.), 1979, Machine Intelligence 9, Chichester/Halsted, New York: Ellis Norwood, 129–148. [See also the [most recent version, 2000.]
- McClain, M. and S. Levinson, 2007, “Semantic based learning of syntax in an autonomous robot,” International Journal of Humanoid Robotics, 4(2): 321–346.
- McCord, M., 1986, “Focalizers, the scoping problem, and semantic interpretation rules in logic grammars,” in M. Van Caneghem and D.H.D. Warren (eds.), Logic Programming and its Applications, Norwood, NJ: Ablex, 223–243.
- McKeown, K.R., 1985, Text Generation: Using Discourse Strategies and Focus Constraints to Generate Natural Language Text, Cambridge, UK: Cambridge University Press.
- Minsky, M., 1968, Semantic Information Processing, Cambridge, MA: MIT Press.
- Moldovan, D.I. and V. Rus, 2001, “Logic form transformation of WordNet and its applicability to question answering,” in Proceedings of ACL 2001, Association for Computational Linguistics, Toulouse, France, July 6–11. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 402–409. [Moldovan and Rus 2001 available online (pdf)]
- Montague, R., 1970, “English as a formal language,” in B. Visentini et al. (eds.), Linguaggi nella società e nella tecnicà, Milan: Edizioni di Comunita, 189–224.
- –––, R., 1973, “The proper treatment of quantification in ordinary English,” in K.J.J. Hintikka, J.M.E. Moravcsik, and P. Suppes (eds.), Approaches to Natural Language, Dortrecht: D. Reidel.
- Mooney, R.J., 2007, “Learning for semantic parsing,” in A. Gelbukh (ed.), Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2007), Mexico City, February. Berlin: Springer, pp. 311–324.
- Moore, J.D. and C.L. Paris, 1988, “Constructing coherent texts using rhetorical relations,” in Proceedings of the 10th Annual Conference of the Cognitive Science Society (COGSCI-88), Montreal, Canada, August 17–19. New York: Taylor & Francis, pp. 199–204.
- –––, 1993, “Planning texts for advisory dialogues: capturing intentional and rhetorical information,” Computational Linguistics, 19(4): 651–694.
- Mostow, J. & J. Beck, 2007, “When the rubber meets the road: Lessons from the in-school adventures of an automated reading tutor that listens,” in B. Schneider & S.-K. McDonald (eds.), Scale-Up in Education (Vol. 2), Lanham, MD: Rowman & Littlefield Publishers, 183–200.
- Movellan, J.R., M. Eckhardt, M. Virnes, and A. Rodriguez, 2009, “Sociable robot improves toddler vocabulary skills,” in Proceedings of the International Conference on Human Robot Interaction (HRI2009), San Diego, CA, March 11–13. New York: ACM Digital Library.
- Narayanan, S., 1997, KARMA: Knowledge-based Action Representations for Metaphor and Aspect, Doctoral thesis, U.C. Berkeley, CA.
- Newell, A. and H.A. Simon, 1976, “Computer science as empirical inquiry: symbols and search,” Communications of the ACM, 19(3): 113–126.
- Nielsen, L.A., 2004, “Verb phrase ellipsis detection using automatically parsed text”, in Proceedings of the 20th International Conference on Computational Linguistics (COLING'04), Geneva, Switzerland. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Nielsen 2004 available online (pdf)]
- Norman, D.A., D.E. Rumelhart, and the LNR Research Group, 1975, Explorations in Cognition, New York: W.H. Freeman and Company.
- Onyshkevych, B., 1998, “Nominal metonymy processing,” COLING-ACL Workshop on the Computational Treatment of Nominals, Aug. 10–14, Quebec, Canada. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Onyshkevych 1998 available online (pdf)]
- Paivio, A., 1986, Mental representations: a dual coding approach, Oxford, England: Oxford University Press.
- Palmer, M., D. Gildea, and N. Xue, 2010, Semantic Role Labeling, San Rafael, CA: Morgan & Claypool.
- Palmer-Brown, D., J.A. Tepper, and H.M. Powell, 2002, “Connectionist natural language parsing,” Trends in Cognitive Sciences 6(October): 437–442.
- Pantel, P., R. Bhagat, B. Coppola, T. Chklovski, and E. Hovy, 2007, “ISP: Learning Inferential Selectional Preferences,” in Proceedings of North American Association for Computational Linguistics / Human Language Technology (NAACL-HLT'07), Rochester, NY. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 564–571. [Pantel et al. 2007 available online (pdf)]
- Parsons, T., 1990, Events in the Semantics of English: A Study in Subatomic Semantics, Cambridge, MA: MIT Press.
- Pereira, F.C.N. and D.H.D. Warren, 1982, “An efficient easily adaptable system for interpreting natural language queries,” American Journal of Computational Linguistics, 8(3–4): 110–122.
- Pierce, J.R., J.B. Carroll, et al., 1966, Language and Machines—Computers in Translation and Linguistics. ALPAC report, National Academy of Sciences, National Research Council, Washington, DC.
- Pinker, S., 1994, The Language Instinct, New York: Harper.
- –––, 2007, The Stuff of Thought, New York: Penguin Group.
- Plate, T.A., 2003, Holographic Reduced Representation: Distributed Representation for Cognitive Structures, Stanford, CA: CSLI Publications.
- Poincaré, H., 1913, “Mathematical creation,” in H. Poincaré (with an introduction by J. Royce), The Foundations of Science: Science and Method, Book I (Science and the Scientist), chapter III, New York: The Science Press.
- Pon-Barry, H., K. Schultz, Owen E. Bratt, B. Clark, and S. Peters, 2006, “Responding to student uncertainty in spoken tutorial dialogue systems,” International Journal of Artificial Intelligence in Education, 16(2): 171–194.
- Poon, H., 2013, “Grounded unsupervised semantic parsing,” in Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL-13), Sofia, Bulgaria, Aug. 4–9. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Poon 2013 available online (pdf)]
- Poon, H. and P. Domingos, 2009, “Unsupervised semantic parsing,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, Aug. 6–7. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Poon and Domingos 2009 available online (pdf)]
- Pullum, G., 2011, “Remarks by Noam Chomsky in London”, Linguist, November 14, 2011, 22.4631. [Pullum 2011 available online]
- Pulman, S., J. Boye, M. Cavazza, Smith and C. R. Santos de la Cámara, 2010, “How was your day?” in Proceedings of the 2010 Workshop on Companionable Dialogue Systems, Uppsala, Sweden, July. Stroudsburg, PA: Association for Computational Linguistics, 37–42.
- Quillian, M.R., 1968, “Semantic memory,” in M. Minsky (ed.) Semantic Information Processing, Cambridge, MA: MIT Press, 227–270.
- Ramsay, W., S.P. Stich, and J. Garon, 1991, “Connectionism, eliminativism and the future of folk psychology,” in W. Ramsay, S.P. Stich, and D.E. Rumelhart (eds.), Philosophy and Connectionist Theory, Hillsdale, NJ: Lawrence Erlbaum.
- Rapaport, W.J., 1995, “Understanding understanding: Syntactic semantics and computational cognition,” in J.E. Tomberlin (ed.), AI, Connectionism, and Philosophical Psychology, Philosophical Perspectives, Vol. 9, Atascadero, CA: Ridgeview Publishing, 49–88.
- Raphael, B., 1968, “SIR: A computer program for semantic infomation retrieval,” in M. Minsky (ed.) Semantic Information Processing, Cambridge, MA: MIT Press, 33–145.
- Ratnaparkhi A., 1997, “A simple introduction to maximum entropy models for natural language processing”, Technical Report 97–08, Institute for Research in Cognitive Science, University of Pennsylvania.
- Reichenbach, H., 1947, Elements of Symbolic Logic, New York: MacMillan.
- Rich, C. and C.L. Sidner, 1998, “COLLAGEN: A collaboration manager for software interface agents,” User Modeling and User-Adapted Interaction, 8(3–4): 315–350.
- Robinson, D.N., 2007, Consciousness and Mental Life, New York, NY: Columbia University Press.
- Rumelhart, D.E., P.H. Lindsay, and D.A. Norman, 1972, “A process model for long-term memory,” in E. Tulving and W. Donaldson, Organization and Memory, New York: Academic Press, 197–246.
- Rumelhart, D.E. and J. McClelland, 1986, Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Cambridge, MA: MIT Bradford Books.
- Salton, G., 1989, Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer, Boston, MA: Addison-Wesley.
- Scha, R., 1981, “Distributive, collective and cumulative quantification,” in J. Groenendijk, T. Janssen, and M. Stokhof (eds.), Formal Methods in the Study of Language, Amsterdam: Mathematical Centre Tracts.
- Schank, R.C. and R.P. Abelson, 1977, Scripts, Plans, Goals and Understanding, Hillsdale, NJ: Lawrence Erlbaum.
- Schank, R.C. and K.M. Colby, 1973, Computer Models of Thought and Language, San Francisco: W.H. Freeman and Co.
- Schank, R.C. and C.K. Riesbeck, 1981, Inside Computer Understanding, Hillsdale, NJ: Lawrence Erlbaum.
- Scheutz, M., R. Cantrell, and P. Schermerhorn, 2011 “Toward human-like task-based dialogue processing for HRI,” AI Magazine 32(4): 77–84.
- Schoenmackers, S., J. Davis, O. Etzioni, and D.S. Weld, 2010, “Learning first-order Horn clauses from Web text,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2010), MIT, MA, Oct. 9–11. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Schoenmackers et al. available online (pdf)]
- Schubert, L.K., 2000, “The situations we talk about”, in J. Minker (ed.), Logic-Based Artificial Intelligence, Dortrecht: Kluwer, 407–439.
- –––, 2007, “Implicit Skolemization: efficient reference to dependent entities,” Research on Language and Computation 5, April, (special volume on Binding Theory, edited by A. Butler, E. Keenan, J. Mattausch and C.-C. Shan): 69-86.
- Schubert, L.K. and F.J. Pelletier, 1982, “From English to logic: Context-free computation of ‘conventional’ logical translations”, American Journal Computational Linguistics, 8: 27–44; reprinted in B.J. Grosz, K. Sparck Jones, and B.L. Webber (eds.), 1986, Readings in Natural Language Processing, Los Altos, CA: Morgan Kaufmann, 293–311.
- Schubert, L.K. and M. Tong, 2003, “Extracting and evaluating general world knowledge from the Brown Corpus,” in Proceedings of the HLT-NAACL Workshop on Text Meaning, Edmonton, Alberta, May 31. Stroudsburg, PA: Association for Computational Linguistics (ACL), 7–13. [Schubert and Tong 2003 available online (pdf)]
- Searle, J., 1969, Speech Acts, Cambridge, UK: Cambridge University Press.
- Sebestyen, G.S., 1962, Decision-Making Processes in Pattern Recognition, New York: Macmillan.
- Sha, F. and F. Pereira, 2003, “Shallow parsing with conditional random fields,” Human Language Technology Conference (HLT-NAACL 2003), May 27 – June 1, Edmonton, Canada. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Sha and Pereira 2003 available online (pdf)]
- Singh, P., T. Lin, E.T. Mueller, G. Lim, T. Perkins, and W.l. Zhu, 2002, “Open Mind Common Sense: Knowledge acquisition from the general public,” in Proceedings of the 1st International Conference on Ontologies, Databases, and Applications of Semantics for Large Scale Information Systems (ODBASE 2002), Irvine, California, October 29–31. Lecture Notes in Computer Science, Volume 2519, New York: Springer, pp. 1223–1237.
- Smith, R.W., D.R. Hipp, and A.W. Biermann, 1995, “An architecture for voice dialogue systems based on Prolog-style theorem proving,” Computational Linguistics, 21: 281–320.
- Smolensky, P., 1988, “On the proper treatment of connectionism,” The Behavioral and Brain Sciences, 11: 1–23.
- Smolensky, P., G. Legendre, and Y. Miyata, 1992, “Principles for an integrated connectionist and symbolic theory of higher cognition,” Technical Report CU-CS-600-92, Computer Science Department, University of Colorado, Boulder, CO.
- Snow, R., B. O'Connor, D. Jurafsky, and A.Y. Ng, 2008, “Cheap and fast—but is it good? Evaluating non-expert annotations for natural language tasks,” in Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP 2008), Waikiki, Honolulu, Oct. 25–27. Stroudsburg, PA: Association for Computational Linguistics (ACL), 254–263. [Snow et al. 2008 available online (pdf)]
- Steedman, Mark, 2007, “Presidential Address to the 45th Annual Meeting of the ACL”, Prague, June 2007. Also printed in 2008, “On becoming a discipline”, Computational Linguistics, 34(1): 137–144. [Steedman 2007 [2008] available online]
- Sun, R., 2001, “Hybrid systems and connectionist implementationalism” (also listed as 2006, “Connectionist implementationalism and hybrid systems,”), in L. Nadel (ed.) Encyclopedia of Cognitive Science, London, UK: MacMillan.
- Tenenbaum, J. B., C. Kemp, T.L. Griffiths, and N.D. Goodman, 2011, “How to grow a mind: Statistics, structure, and abstraction,” Science, 331: 1279–1285.
- Thompson, F.B., P.C. Lockermann, B.H. Dostert, and R. Deverill, 1969, “REL: A rapidly extensible language system,” in Proceedings of the 24th ACM National Conference, New York: ACM Digital Library, pp. 399–417.
- Thompson, F.B. and B.H. Thompson, 1975, “Practical natural language processing: The REL system as prototype,” in M. Rubinoff and M.C. Yovits (eds.), Advances in Computers, vol. 13, New York: Academic Press, 109–168.
- Turney, P.D., 2008, “The Latent Relation Mapping Engine: algorithm and experiments,” Journal of Artificial Intelligence Research, 33: 615–655.
- Van Durme, B., P. Michalak, and L.K. Schubert, 2009, “Deriving generalized knowledge from corpora using WordNet abstraction”, 12th Conference of the European Chapter of the Association for Computational Linguistics (EACL-09), Athens, Greece, Mar. 30–Apr. 3. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Van Durme, Michalak and Schubert 2009 available online (pdf)]
- Veale, T. and Y. Hao, 2008, “A fluid knowledge representation for understanding and generating creative metaphors,” The 22nd International Conference on Computational Linguistics (COLING 2008), Manchester, UK, Aug. 18–22. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 945–952. [Veale and Hao 2008 available online (pdf)]
- Vijay-Shankar, K. and D.J. Weir, 1994, “Parsing some constrained grammar formalisms,” Computational Linguistics, 19(4): 591–636.
- von Ahn, L., M. Kedia, and M. Blum, 2006, “Verbosity: A game for collecting common-sense knowledge,” in R. Grinter, T. Rodden, P. Aoki, E. Cutrell, R. Jeffries, and G. Olson (eds.), Proceedings of the SICHI Conference on Human Factors in Computing Systems (CHI 2006), Montreal, Canada, April 22–27. New York: ACM Digital Library, pp. 75–78.
- Weischedel, R.M. and N.K. Sondheimer, 1983, “Meta-rules as a basis for processing ill-formed input,” American Journal of Computational Linguistics, 9(3–4): 161–177.
- Widdows, D., 2004, Geometry and Meaning, Stanford, CA: CSLI Publications.
- Wilks, Y., 1978, “Making preferences more active,” Artificial Intelligence, 11(3): 197–223; also in N.V. Findler (ed.), 1979, Associative Networks: Representation and Use of Knowledge, Orlando, FL: Academic Press, 239–266.
- –––, 2010, “Is a companion a distinctive kind of relationship with a machine?” in Proceedings of the 2010 Workshop on Companionable Dialogue Systems, (CDS ‘10), Uppsala, Sweden. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 13–18. [Wilks 2010 available online (pdf)]
- Winograd, T., 1972, Understanding Natural Language, New York: Academic Press.
- Woods, W.A., R.M. Kaplan, B.L. Nash-Webber, 1972, “The Lunar Sciences Natural Language Information System: Final Report”, BBN Report No. 2378, Bolt Beranek and Newman Inc., Cambridge, MA. (Available from NTIS as N72-28984.)
- Yarowsky, D., 1992, “Word-sense disambiguation using statistical models of Roget's categories trained on large corpora,” in Proceedings of the 14th International Conference on Computational Linguistics (COLING-92), Nantes, France. Stroudsburg, PA: Association for Computational Linguistics (ACL), pp. 454–60. [Yarowsky 1992 available online (pdf)]
- Younger, D.H., 1967, “Recognition and parsing of context-free languages in time n3,” Information and Control, 10(2): 189–208.
- Zettlemoyer, L.S. and M. Collins, 2007, “On-line learning of relaxed CCG grammars for parsing to logical form,” in Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2007), Prague, June 28–30. Stroudsburg, PA: Association for Computational Linguistics (ACL). [Zettlemoyer and Collins 2007 available online (pdf)]
Academic Tools
How to cite this entry. Preview the PDF version of this entry at the Friends of the SEP Society. Look up this entry topic at the Internet Philosophy Ontology Project (InPhO). Enhanced bibliography for this entry at PhilPapers, with links to its database.
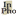

Other Internet Resources
- NLP toolkits: MALLET (MAchine Learning for LanguagE Toolkit)
- Cognitive Assistant that Learns and Organizes (CALO), SRI International Artificial Intelligence Center.
- Collections of factoids about named entities, in the form of word tuples: UW Open IE and ReVerb; collections of factoids as RDF (Resource Description Framework) triples—e.g., DBpedia, True Knowledge, and YAGO.
- Large-scale QA systems: A very readable and cogent comparison of the approaches to QA in Wolfram|Aplha and IBM's Watson, with suggestive architectural flowcharts, can be found at http://blog.stephenwolfram.com/2011/01/jeopardy-ibm-and-wolframalpha/.
Acknowledgments
The author and editors would like to thank an anonymous external referee for the time he spent and the advice he gave us for improving the presentation in this entry.
