

Quantum Computing
Combining physics, mathematics and computer science, quantum computing has developed in the past two decades from a visionary idea to one of the most fascinating areas of quantum mechanics. The recent excitement in this lively and speculative domain of research was triggered by Peter Shor (1994) who showed how a quantum algorithm could exponentially "speed-up" classical computation and factor large numbers into primes much more rapidly (at least in terms of the number of computational steps involved) than any known classical algorithm. Shor's algorithm was soon followed by several other algorithms that aimed to solve combinatorial and algebraic problems, and in the last few years theoretical study of quantum systems serving as computational devices has achieved tremendous progress. Common belief has it that the implementation of Shor's algorithm on a large scale quantum computer would have devastating consequences for current cryptography protocols which rely on the premiss that all known classical worst-case algorithms for factoring take time exponential in the length of their input (see, e.g., Preskill 2005). Consequently, experimentalists around the world are engaged in tremendous attempts to tackle the technological difficulties that await the realization of such a large scale quantum computer. But regardless whether these technological problems can be overcome (Unruh 1995, Ekert and Jozsa 1996, Haroche and Raimond 1996), it is noteworthy that no proof exists yet for the general superiority of quantum computers over their classical counterparts.
The philosophical interest in quantum computing is threefold: First, from a social-historical perspective, quantum computing is a domain where experimentalists find themselves ahead of their fellow theorists. Indeed, quantum mysteries such as entanglement and nonlocality were historically considered a philosophical quibble, until physicists discovered that these mysteries might be harnessed to devise new efficient algorithms. But while the technology for isolating 5 or even 7 qubits (the basic unit of information in the quantum computer) is now within reach (Schrader et al. 2004, Knill et al. 2000), only a handful of quantum algorithms exist, and the question whether these can solve classically intractable computational problems is still open. Next, from a more philosophical perspective, advances in quantum computing may yield foundational benefits. It may turn out that the technological capabilities that allow us to isolate quantum systems by shielding them from the effects of decoherence for a period of time long enough to manipulate them will also allow us to make progress in some fundamental problems in the foundations of quantum theory itself. Indeed, the development and the implementation of efficient quantum algorithms may help us understand better the border between classical and quantum physics, hence elucidate an important problem, namely, the measurement problem, that so far resists a solution. Finally, the idea that abstract mathematical concepts such as complexity and (in)tractability may not only be translated into physics, but also re-written by physics bears directly on the autonomous character of computer science and the status of its theoretical entities—the so-called "computational kinds". As such it is also relevant to the long-standing philosophical debate on the relationship between mathematics and the physical world.
- 1. A Brief History of the Field
- 2. Basics
- 3. Quantum Algorithms
- 4. Philosophical Implications
- Bibliography
- Other Internet Resources
- Related Entries
1. A Brief History of the Field
1.1 Physical Computational Complexity
The mathematical model for a "universal" computer was defined long before the invention of computers and is called the Turing machine (Turing 1936). A Turing machine consists of an unbounded tape, a head that is capable of reading from the tape and of writing onto it and can occupy an infinite number of possible states, and an instruction table (a transition function). This table, given the head's initial state and the input it reads from the tape in that state, determines (a) the symbol that the head will write on the tape, (b) the internal state it will occupy, and (c) the displacement of the head on the tape. In 1936 Turing showed that since one can encode the instruction table of a Turing machine T and express it as a binary number #(T), there exists a universal Turing machine U that can simulate the instruction table of any Turing machine on any given input with at most a polynomial slowdown (i.e., the number of computational steps required by U to execute the original program T on the original input will be polynomially bounded in #(T)). That the Turing machine model (what we now days call "an algorithm") captures the concept of computability in its entirety is the essence of the Church-Turing thesis, according to which any effectively calculable function can be computed using a Turing machine. Admittedly, no counterexample to this thesis (which is the result of convergent ideas of Turing, Post, Kleene and Church) has yet been found. But since it identifies the class of computable functions with the class of those functions which are computable using a Turing machine, this thesis involves both a precise mathematical notion and an informal and intuitive notion, hence cannot be proved or disproved. Simple cardinality considerations show, however, that not all functions are Turing-computable (the set of all Turing machines is countable, while the set of all functions from the natural numbers to the natural numbers is not), and the discovery of this fact came as a complete surprise in the 1930s (Davis 1958).
Computability, or the question whether a function can be computed, is not the only question that interests computer scientists. The cost of computing a function is also of great importance, and this cost, also known as computational complexity, is measured naturally in the physical resources (e.g., time, space, energy) invested in order to solve the computational problem at hand. Computer scientists classify computational problems according to the way their cost function behaves as a function of their input size, n, (the number of bits required to store the input) and in particular, whether it increases exponentially or polynomially with n. Tractable problems are those which can be solved in polynomial cost, while intractable problems are those which can only be solved in an exponential cost (the former solutions are commonly regarded as efficient although an exponential-time algorithm could turn out to be more efficient than a polynomial-time algorithm for some range of input sizes). If we further relax the requirement that a solution to a computational problem be always correct, and allow probabilistic algorithms with a negligible probability of error, we can dramatically reduce the computational cost. Probabilistic algorithms are non-deterministic Turing machines whose transition function can randomly change the head's configuration in one of several possible ways. The most famous example of an algorithm of this kind is the probabilistic algorithm that decides whether a given natural number is prime in a polynomial number of steps (Rabin 1976).
Using this notion we can further refine the distinction between tractable and intractable problems. The class P (for Polynomial) is the class that contains all the computational decision problems that can be solved by a deterministic Turing machine at a polynomial cost. The class NP (for Non-deterministic Polynomial) is the class that contains all those computational decision problems whose proposed solution ("guessed" by the non-deterministic Turing machine) can be verified by a deterministic Turing machine at polynomial cost. The most famous problems in NP are called "NP-complete". The term "complete" designates the fact that these problems stand or fall together: Either they are all tractable, or none of them is! If we knew how to solve an NP-complete problem efficiently (i.e., with a polynomial cost) we could solve any problem in NP with only polynomial slowdown (Cook 1971). Today we know of hundreds of examples of NP-complete problems (Garey and Johnson 1979), all of which are reducible one to another in polynomial slowdown, and since the best known algorithm for any of these problems is exponential, the widely believed conjecture is that there is no polynomial algorithm that can solve them. But while clearly P ⊆ NP, proving or disproving the conjecture that P ≠ NP remains perhaps one of the most important open questions in computer science and complexity theory.
Although the original Church-Turing thesis involved the abstract mathematical notion of computability, physicists as well as computer scientists often interpret it as saying something about the scope and limitations of physical computing machines. For example, Wolfram (1985) claims that any physical system can be simulated (to any degree of approximation) by a universal Turing machine, and that complexity bounds on Turing machine simulations have physical significance. For example, if the computation of the minimum energy of some system of n particles requires at least an exponentially increasing number of steps in n, then the actual relaxation of this system to its minimum energy state will also take an exponential time. Aharonov (1998) strengthens this thesis (in the context of showing its putative incompatibility with quantum mechanics) when she says that a probabilistic Turing machine can simulate any reasonable physical device at polynomial cost. Further examples for this thesis can be found in Copeland (1996). In order for the physical Church-Turing thesis to make sense we have to relate the space and time parameters of physics to their computational counterparts: memory capacity and number of computation steps, respectively. There are various ways to do that, leading to different formulations of the thesis (Pitowsky 1990). For example, one can encode the set of instructions of a universal Turing machine and the state of its infinite tape in the binary development of the position coordinates of a single particle. Consequently, one can physically ‘realize’ a universal Turing machine as a billiard ball with hyperbolic mirrors (Moore 1990, Pitowsky 1996). For the most intuitive connection between abstract Turing machines and physical devices see the pioneering work of Gandy (1980), simplified later by Sieg and Byrnes (1999). It should be stressed that there is no relation between the original Church-Turing thesis and its physical version (Pitowsky and Shagrir 2003), and while the former concerns the concept of computation that is relevant to logic (since it is strongly tied to the notion of proof which requires validation), it does not analytically entail that all computations should be subject to validation. Indeed, there is a long historical tradition of analog computations which use continuous physical processes (Dewdney 1984), and the output of these computations is validated either by repetitive "runs" or by validating the physical theory that presumably governs the behavior of the analog computer.
1.2 Physical "Short-cuts" of Computation
Do physical processes exist which contradict the physical Church-Turing thesis? Apart from analog computation, there exist at least two counter-examples to this thesis that purport to show that the notion of recursion, or Turing-computability, is not a natural physical property (Pour-el and Richards 1981, Pitowsky 1990, Hogarth 1994). Although the physical systems involved (a specific initial condition for the wave equation in three dimensions and an exotic solution to Einstein's field equations, respectively) are somewhat contrived, recent years saw the emergence of the thriving school of "hypercomputation" that aspires to extend the limited examples of physical "hypercomputers" and in so doing to physically "compute" the non-Turing-computable (for a review see Copeland 2002; for a criticism—Davis 2003). Quantum hypercomputation is rarely discussed in the literature (See, e.g., Calude et al. 2003), but the most concrete attempt to harness quantum theory to compute the non-computable is the suggestion to use the quantum adiabatic algorithm (see below) to solve Hilbert's Tenth Problem (Kieu 2002, 2004)—a Turing-undecidable problem equivalent to the halting problem. Recent criticism, however, has exposed the unphysical character of the alleged quantum adiabatic hypercomputer (see Smith 2005, Hodges 2005, and Hagar and Korolev 2006).
Setting aside the hype around "hypercomputers", even if we restrict ourselves only to Turing-computable functions and focus on computational complexity, we can still find many physical models that purport to display "short-cuts" in computational resources. Consider, e.g., the DNA model of computation that was claimed (Adleman 1994, Lipton 1995) to solve NP-complete problems in polynomial time. A closer inspection shows that the cost of the computation in this model is still exponential since the number of molecules in the physical system grows exponentially with the size of the problem. Or take an allegedly instantaneous solution to another NP-complete problem using a construction of rods and balls (Vergis et.al. 1986) that unfortunately ignores the accumulating time-delays in the rigid rods that result in an exponential overall slowdown. Another example is the physical simulation of the factorization of numbers into primes that uses only polynomial resources in time and space, but requires an exponentially increasing precision. It thus appears that all these models cannot serve as counter-examples to the physical Church-Turing thesis (as far as complexity is concerned) since they all require some exponential physical resource. Note, however, that all these models are based on classical physics, hence the unavoidable question: Can the shift to quantum physics allow us to find "short-cuts" in computational resources? The quest for the quantum computer began with the possibility of giving a positive answer to this question.
1.3 Milestones
The idea of a computational device based on quantum mechanics was explored already in the 1970s by physicists and computer scientists. As early as 1969 Steven Wiesner suggested quantum information processing as a possible way to better accomplish cryptologic tasks. But the first four published papers on quantum information (Wiesner published his only in 1983), belong to Alexander Holevo (1973), R.P. Poplavskii (1975), Roman Ingarden (1976) and Yuri Manin (1980). Better known are contributions made in the early 1980s by Charles H. Bennett of the IBM Thomas J. Watson Research Center, Paul A. Benioff of Argonne National Laboratory in Illinois, David Deutsch of the University of Oxford, and the late Richard P. Feynman of the California Institute of Technology. The idea emerged when scientists were investigating the fundamental physical limits of computation. If technology continued to abide by "Moore's Law" (the observation made in 1965 by Gordon Moore, co-founder of Intel, that the number of transistors per square inch on integrated circuits had doubled every 18 months since the integrated circuit was invented), then the continually shrinking size of circuitry packed onto silicon chips would eventually reach a point where individual elements would be no larger than a few atoms. But since the physical laws that govern the behavior and properties of the putative circuit at the atomic scale are inherently quantum mechanical in nature, not classical, the natural question arose whether a new kind of computer could be devised based on the principles of quantum physics.
Feynman was among the first to attempt to provide an answer to this question by producing an abstract model in 1982 that showed how a quantum system could be used to do computations. He also explained how such a machine would be able to act as a simulator for quantum physics. Feynman also conjectured that any classical computer that will be harnessed for this task will do so only inefficiently, incurring an exponential slowdown in computation time. In 1985 David Deutsch proposed the first universal quantum Turing machine and paved the way to the quantum circuit model. The young and thriving domain also attracted philosophers' attention. In 1983 David Albert showed how a quantum mechanical automaton behaves remarkably differently from a classical automaton, and in 1990 Itamar Pitowsky raised the question whether the superposition principle will allow quantum computers to solve NP-complete problems. He also stressed that although one could in principle ‘squeeze’ information of exponential complexity into polynomially many quantum states, the real problem lay in the efficient retrieval of this information.
Progress in quantum algorithms began in the 1990s, with the discovery of the Deutsch-Josza oracle (1992) and of Simon's oracle (1994). The latter supplied the basis for Shor's algorithm for factoring. Published in 1994, this algorithm marked a ‘phase transition’ in the development of quantum computing and sparked a tremendous interest even outside the physics community. In that year the first experimental realization of the quantum CNOT gate with trapped ions was proposed by Cirac and Zoller (1995). In 1995, Peter Shor and Andrew Steane proposed (independently) the first scheme for quantum error-correction. In that same year the first realization of a quantum logic gate was done in Boulder, Colorado, following Cirac and Zoller's proposal.
In 1996, Lov Grover from Bell Labs invented the quantum search algorithm which yields a quadratic "speed-up" compared to its classical counterpart. A year later the first NMR model for quantum computation was proposed, based on nuclear magnetic resonance techniques. This technique was realized in 1998 with a 2-qubit register, and was scaled up to 7 qubits in the Los Alamos National Lab in 2000.
Starting from 2000 the field saw an exponential growth. New paradigms of quantum algorithms have appeared, such as adiabatic algorithms, measurement-based algorithms, and topological-quantum-field-theory-based algorithms, as well as new physical models for realizing a large scale quantum computer with cold ion traps, quantum optics (using photons and optical cavity), condensed matter systems and solid state physics (meanwhile, the first NMR model had turned out to be a dead-end with respect to scaling; see DiVicenzo 2000). The basic questions, however, remain open even today: (1) theoretically, can quantum algorithms efficiently solve classically intractable problems? (2) operationally, can we actually realize a large scale quantum computer to run these algorithms?2. Basics
In this section we will review the basic paradigm for quantum algorithms, namely the quantum circuit model, which is composed of the basic quantum units of information (qubits) and the basic logical manipulations thereof (quantum gates).
2.1 The Qubit
The qubit is the quantum analogue of the bit, the classical
fundamental unit of information. It is a mathematical object with
specific properties that can be realized physically in many different
ways as an actual physical system. Just as the classical bit has a
state (either 0 or 1), a qubit also has a state. Yet contrary
to the classical bit,
 0
0 and
1
are but two
possible states of the qubit, and any linear combination
(superposition) thereof is also physically possible. In
general, thus, the physical state of a qubit is the superposition
ψ
=
α0
+
β1
(where α and β are complex numbers). The state of a qubit
can be described as a vector in a two-dimensional Hilbert space, a
complex vector space
(see the entry on
quantum mechanics).
The special states
0
and
1
are known as the computational basis states, and form an
orthonormal basis for this vector space. According to quantum theory,
when we try to measure the qubit in this basis in order to determine
its state, we get either
0
with probability
α²
or
1
with probability
β².
Since
α²
+
β² = 1
(i.e., the qubit is a unit
vector in the aforementioned two-dimensional Hilbert state), we may
(ignoring the overall phase factor) effectively write its state as
ψ
=
cos(θ)0
+
eiφsin(θ)1,
where the numbers θ and φ define a point on the unit
three-dimensional sphere, as shown here. This sphere is often called
the Bloch sphere, and it provides a useful means to visualize
the state of a single qubit.
and
1
are but two
possible states of the qubit, and any linear combination
(superposition) thereof is also physically possible. In
general, thus, the physical state of a qubit is the superposition
ψ
=
α0
+
β1
(where α and β are complex numbers). The state of a qubit
can be described as a vector in a two-dimensional Hilbert space, a
complex vector space
(see the entry on
quantum mechanics).
The special states
0
and
1
are known as the computational basis states, and form an
orthonormal basis for this vector space. According to quantum theory,
when we try to measure the qubit in this basis in order to determine
its state, we get either
0
with probability
α²
or
1
with probability
β².
Since
α²
+
β² = 1
(i.e., the qubit is a unit
vector in the aforementioned two-dimensional Hilbert state), we may
(ignoring the overall phase factor) effectively write its state as
ψ
=
cos(θ)0
+
eiφsin(θ)1,
where the numbers θ and φ define a point on the unit
three-dimensional sphere, as shown here. This sphere is often called
the Bloch sphere, and it provides a useful means to visualize
the state of a single qubit.
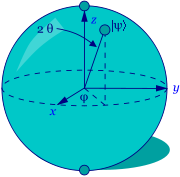
The Bloch Sphere
Theoretically, a single qubit can store an infinite amount of information, yet when measured it yields only the classical result (0 or 1) with certain probabilities that are specified by the quantum state. In other words, the measurement changes the state of the qubit, "collapsing" it from the superposition to one of its terms. The crucial point is that unless the qubit is measured, the amount of "hidden" information it stores is conserved under the dynamic evolution (namely, Schrödinger's equation). This feature of quantum mechanics allows one to manipulate the information stored in unmeasured qubits with quantum gates, and is one of the sources for the putative power of quantum computers.
To see why, let us suppose we have two qubits at our disposal. If
these were classical bits, then they could be in four possible states
(00, 01, 10, 11). Correspondingly, a pair of qubits has four
computational basis states
(00,
01,
10,
11).
But while a single classical two-bit register can store these numbers
only one at a time, a pair of qubits can also exist in a
superposition of these four basis states, each of which with its own
complex coefficient (whose mod square, being interpreted as
probability, is normalized). As long as the quantum system evolves
unitarily and is unmeasured, all four possible states are
simultaneously "stored" in a single two-qubit quantum register. More
generally, the amount of information that can be stored in a system of
n unmeasured qubits grows exponentially in n. The
difficult task, however, is to retrieve this information efficiently.
2.2 Quantum Gates
Classical computational gates are Boolean logic gates that perform manipulations of the information stored in the bits. In quantum computing these gates are represented by matrices, and can be visualized as rotations of the quantum state on the Bloch sphere. This visualization represents the fact that quantum gates are unitary operators, i.e., they preserve the norm of the quantum state (if U is a matrix describing a single qubit gate, then U†U=I, where U† is the adjoint of U, obtained by transposing and then complex-conjugating U). As in the case of classical computing, where there exists a universal gate (the combinations of which can be used to compute any computable function), namely, the NAND gate which results from performing an AND gate and then a NOT gate, in quantum computing it was shown (Barenco et al., 1995) that any multiple qubit logic gate may be composed from a quantum CNOT gate (which operates on a multiple qubit by flipping or preserving the target bit given the state of the control bit, an operation analogous to the classical XOR, i.e., the exclusive OR gate) and single qubit gates. One feature of quantum gates that distinguishes them from classical gates is that they are reversible: the inverse of a unitary matrix is also a unitary matrix, and thus a quantum gate can always be inverted by another quantum gate.

The CNOT Gate
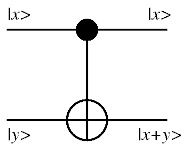
Unitary gates manipulate the information stored in the quantum register, and in this sense ordinary (unitary) quantum evolution can be regarded as computation (DiVicenzo 1995 showed how a small set of single-qubit gates and a two-qubit gate is universal, in the sense that a circuit combined from this set can approximate to arbitrary accuracy any unitary transformation of n qubits). In order to read the result of this computation, however, the quantum register must be measured. The measurement gate is a non-unitary gate that "collapses" the quantum superposition in the register onto one of its terms with the corresponding probability. Usually this measurement is done in the computational basis, but since quantum mechanics allows one to express an arbitrary state as a linear combination of basis states, provided that the states are orthonormal (a condition that ensures normalization) one can in principle measure the register in any arbitrary orthonormal basis. This, however, doesn't mean that measurements in different bases are efficiently equivalent. Indeed, one of the difficulties in constructing efficient quantum algorithms stems exactly from the fact that measurement collapses the state, and some measurements are much more complicated than others.
2.3 Quantum Circuits
Quantum circuits are similar to classical computer circuits in that
they consist of wires and logical gates. The wires
are used to carry the information, while the gates manipulate it (note
that the wires do not correspond to physical wires; they may
correspond to a physical particle, a photon, moving from one location
to another in space, or even to time-evolution). Conventionally, the
input of the quantum circuit is assumed to be a computational basis
state, usually the state consisting of all
0.
The output state of the circuit is then measured in the computational
basis, or in any other arbitrary orthonormal basis. The first quantum
algorithms (i.e. Deutsch-Jozsa, Simon, Shor and Grover) were
constructed in this paradigm. Additional paradigms for quantum
computing exist today that differ from the quantum circuit model in
many interesting ways. So far, however, they all have been
demonstrated to be computationally equivalent to the circuit model
(see below), in the sense that any computational problem that can be
solved by the circuit model can be solved by these new models with
only a polynomial overhead in computational resources.
3. Quantum Algorithms
Algorithm design is a highly complicated task, and in quantum computing it becomes even more complicated due to the attempts to harness quantum mechanical features to reduce the complexity of computational problems and to "speed-up" computation. Before attacking this problem, we should first convince ourselves that quantum computers can be harnessed to perform standard, classical, computation without any "speed-up". In some sense this is obvious, given the belief in the universal character of quantum mechanics, and the observation that any quantum computation that is diagonal in the computational basis, i.e., involves no interference between the qubits, is effectively classical. Yet the demonstration that quantum circuits can be used to simulate classical circuits is not straightforward (recall that the former are reversible while the latter use gates which are inherently irreversible). Indeed, quantum circuits cannot be used directly to simulate classical computation, but the latter can still be simulated on a quantum computer using an intermediate gate, namely the Toffoli gate. This gate has three input bits and three output bits, two of which are control bits, unaffected by the action of the gate. The third bit is a target bit that is flipped if both control bits are set to 1, and otherwise is left alone. This gate is reversible (its inverse is itself), and can be used to simulate all the elements of the classical irreversible circuit with a reversible one. Consequently, using the quantum version of the Toffoli gate (which by definition permutes the computational basis states similarly to the classical Toffoli gate) one can simulate, although rather tediously, irreversible classical logic gates with quantum reversible ones. Quantum computers are thus capable of performing any computation which a classical deterministic computer can do.
What about non-deterministic computation? Not surprisingly, a quantum
computer can simulate also this type of computation by using another
famous quantum gate, namely the Hadamard gate, which receives as an
input the state
0
and produces the state
(0
+
1)/√2.
Measuring this output state yields
0
or
1
with 50/50 probability, which can be used to simulate a fair coin
toss.


The Hadamard Gate
Obviously, if quantum algorithms could be used only to simulate classical algorithms, then the technological advancement in information storage and manipulation, encapsulated in "Moore's law", would have only trivial consequences on computational complexity theory, leaving the latter unaffected by the physical world. But while some computational problems will always resist quantum "speed-up" (in these problems the computation time depends on the input, and this feature will lead to a violation of unitarity hence to an effectively classical computation even on a quantum computer—see Myers 1997 and Linden and Popescu 1998), the hope is, nonetheless, that quantum algorithms may not only simulate classical ones, but that they will actually outperform the latter in some cases, and in so doing help to re-define the abstract notions of tractability and intractability and violate the physical Church-Turing thesis, at least as far as computational complexity is concerned.
3.1 Quantum-Circuit-Based Algorithms
The first quantum algorithms were designed to exploit the adequacy of quantum computation to computational problems which involve oracles. Oracles are devices which are used to answer questions with a simple yes or no. The questions may be as elaborate as one can make them, the procedure that answers the questions may be lengthy and a lot of auxiliary data may get generated while the question is being answered. Yet all that comes out of the oracle is just yes or no. The oracle architecture is very suitable for quantum computers. The reason for this is that, as stressed above, the read-out of a quantum system is probabilistic. Therefore if one poses a question the answer to which is given in the form of a quantum state, one will have to carry out the computation on an ensemble of quantum computers to get anywhere. On the other hand if the computation can be designed in such a way that one does get yes or no in a single measurement (and some data reduction may be required to accomplish this), then a single quantum computer and a single quantum computation run may suffice.
3.1.1 The Deutsch Oracle
This oracle (Deutsch 1989) answers the following question. Suppose we
have a function ƒ: {0,1} → {0,1}, which can be either
constant or balanced. In this case, the function is constant if ƒ(0) = ƒ(1) and it is balanced if ƒ(0) ≠ ƒ(1). Classically it would take two evaluations of the function to tell whether it
is one or the other. Quantumly, we can answer this question in
one evaluation. The reason for this complexity reduction is,
again, the superposition principle. To see why consider the following
quantum algorithm. One can prepare the input qubits of the Deutsch
oracle as the superposition
(0
+
1)/√2
(using the Hadamard gate on
0)
and the superposition
(0
−
1)/√2
(using the Hadamard gate on
1).
The oracle is implemented with a quantum circuit which takes
inputs like
x,y
to
x, y⊕ƒ(x),
where ⊕ is
addition modulo two, which is exactly what a XOR gate
does. The first qubit of the output of this oracle is then fed into a
Hadamard gate, and the final output of the algorithm is the state
±
Since ƒ(0)⊕ƒ(1) is 0 if the function is constant and 1 if the function balanced, a single measurement of the first qubit of the output suffices to retrieve the answer to the question whether the function is constant or balanced. In other words, we can distinguish in one run of the algorithm between the two quantum disjunctions without finding out the truth values of the disjuncts themselves in the computation.
3.1.2 The Deutsch-Jozsa Oracle
This oracle (Deutsch and Jozsa 1992) generalizes the Deutsch oracle to a function ƒ: {0,1}n → {0,1}. We ask the same question: is the function constant or balanced. Here balanced means that the function is 0 on half of its arguments and 1 on the other half. Of course in this case the function may be neither constant nor balanced. In this case the oracle doesn't work: It may say yes or no but the answer will be meaningless. Also here the algorithm allows one to evaluate a global property of the function in one measurement because the output state is a superposition of balanced and constant states such that the balanced states all lie in a subspace orthogonal to the constant states and can therefore be distinguished from the latter in a single measurement. In contrast, the best deterministic classical algorithm would require 2n/2+1 queries to the oracle in order to solve this problem.
3.1.3 The Simon Oracle
Suppose we have a Boolean function ƒ: {0,1}n → {0,1}n. The function is supposed to be 2-to-1, i.e., for every value of ƒ there are always two x1 and x2 such that ƒ(x1) = ƒ(x2). The function is also supposed to be periodic, meaning that there is a binary vector a such that ƒ(x⊕a) = ƒ(x), where ⊕ designates addition modulo 2, i.e., 1 ⊕ 1 = 0. The Simon oracle returns the period a in a number of measurements linear in n, which is exponentially faster than any classical algorithm (Simon 1994). Simon's oracle reduces to Deutsch XOR oracle when n=2, and can indeed be regarded as an extension of the latter, in the sense that a global property of a function, in this case its period, can be evaluated in an efficient number of measurements, given that the output state of the algorithm is decomposed into orthogonal subspaces, only one of which contains the solution to the problem, hence repeated measurements in the computational basis will be sufficient to determine this subspace. In other words, Simon's oracle is yet another example where a quantum algorithm can evaluate a disjunction without determining the truth value of the disjuncts. For more on the logical analysis of these first quantum-circuit-based algorithms see Bub (2006b).
3.1.4 Shor's Algorithm
The three oracles just described, although demonstrating the potential superiority of quantum computers over their classical counterparts, nevertheless deal with apparently unimportant computational problems. Indeed, it is doubtful whether the research field of quantum computing would have attracted so much attention and would have evolved to its current status if its merit could be demonstrated only with these problems. But in 1994, after realizing that Simon's oracle can be harnessed to solve a much more interesting and crucial problem, namely factoring, which lies at the heart of current cryptographic protocols such as the RSA (Rivest 1978), Peter Shor has turned quantum computing into one of the most exciting research domains in quantum mechanics.
Shor's algorithm (1994) exploits the ingenious number theoretic argument that two prime factors p,q of a positive integer N=pq can be found by determining the period of a function ƒ(x) = yx mod N, for any y < N which has no common factors with N other than 1 (Nielsen and Chuang 2000, App. 4). The period r of ƒ(x) depends on y and N. Once one knows the period, one can factor N if r is even and yr/2 ≠ −1 mod N, which will be jointly the case with probability greater than 1/2 for any y chosen randomly (if not, one chooses another value of y and tries again). The factors of N are the greatest common divisors of yr/2 ± 1 and N, which can be found in polynomial time using the well known Euclidean algorithm. In other words, Shor's remarkable result rests on the discovery that the problem of factoring reduces to the problem of finding the period of a certain periodic function ƒ: Zn → ZN, where Zn is the additive group of integers mod n (Note that ƒ(x) = yx mod N so that ƒ(x+r) = ƒ(x) if x+r ≤ n. The function is periodic if r divides n exactly, otherwise it is almost periodic). That this problem can be solved efficiently by a quantum computer is demonstrated with Simon's oracle.
Shor's result is the most dramatic example so far of quantum "speed-up" of computation, notwithstanding the fact that factoring is believed to be only in NP and not in NP-complete. To verify whether n is prime takes a number of steps which is a polynomial in log2n (the binary encoding of a natural number n requires log2n resources). But nobody knows how to factor numbers into primes in polynomial time, not even on a probabilistic Turing machine, and the best classical algorithms we have for this problem are sub-exponential. This is yet another open problem in the theory of computational complexity. Modern cryptography and Internet security are based on these two facts: It is easy to find large prime numbers fast, and it is hard to factor large composite numbers in any reasonable amount of time. Many protocols such as public key and electronic signature are based on these facts (Giblin 1993). The discovery that quantum computers can solve factoring in polynomial time has had, therefore, a dramatic effect. The implementation of the algorithm on a physical machine will have economic, as well as scientific consequences.
3.1.5 Grover's Algorithm
Suppose you have met someone who kept her name secret, but revealed her telephone number to you. Can you find out her name using her number and a phone directory? In the worst case, if there are n entries in the directory, the computational resources required will be linear in n. Grover (1996) showed how this task, namely, searching an unstructured database, could be done with a quantum algorithm with complexity of the order √n. Agreed, this "speed-up" is more modest than Shor's since searching an unstructured database belongs to the class P, but contrary to Shor's case, where the classical complexity of factoring is still unknown, here the superiority of the quantum algorithm, however modest, is definitely provable. That this quadratic "speed-up" is also the optimal quantum "speed-up" possible for this problem was proved by Bennett, Bernstein, Brassard and Vazirani (1997).
Although the purpose of Grover's algorithm is usually described as "searching a database", it may be more accurate to describe it as "inverting a function". Roughly speaking, if we have a function y=f(x) that can be evaluated on a quantum computer, Grover's algorithm allows us to calculate x when given y. Inverting a function is related to searching a database because we could come up with a function that produces a particular value of y if x matches a desired entry in a database, and another value of y for other values of x. The applications of this algorithm are far-reaching (over and above finding the name of the mystery ‘date’ above). For example, it can be used to to determine efficiently the number of solutions to an N-item search problem, hence to perform exhaustive searches on a class of solutions to an NP-complete problem and substantially reduce the computational resources required for solving it.
3.2 Adiabatic Algorithms
More than a decade has passed since the discovery of the first quantum algorithm, but so far little progress has been made with respect to the "Holy Grail" of solving an NP-complete problem with a quantum-circuit model. As stressed above, Shor's algorithm stands alone in its exponential "speed-up", yet while no efficient classical algorithm for factoring is known to exist, there is also no proof that such an algorithm doesn't or cannot exist. In 2000 a group of physicists from MIT and Northeastern University (Farhi et al. 2000) proposed a novel paradigm for quantum computing that differs from the circuit model in several interesting ways. Their goal was to try to solve with this algorithm an instance of satisfiability—deciding whether a proposition in the propositional calculus has a satisfying truth assignment—which is one of the most famous NP-complete problems (Cook 1971).
According to the adiabatic theorem (e.g., Messiah 1961) and given certain specific conditions, a quantum system remains in its lowest energy state, known as the ground state, along an adiabatic transformation in which the system is deformed slowly and smoothly from an initial Hamiltonian to a final Hamiltonian (as an illustration, think of moving a baby who is sleeping in a cradle from the living room to the bedroom. If the transition is done slowly and smoothly enough, and if the baby is a sound sleeper, then it will remain asleep during the whole transition). The most important condition in this theorem is the energy gap between the ground state and the next excited state (in our analogy, this gap reflects how sound asleep the baby is). Being inversely proportional to the evolution time T, this gap controls the latter. If this gap exists during the entire evolution (i.e., there is no level crossing between the energy states of the system), the theorem dictates that in the adiabatic limit (when T→∞) the system will remain in its ground state. In practice, of course, T is always finite, but the longer it is, the less likely it is that the system will deviate from its ground state during the time evolution.
The crux of the quantum adiabatic algorithm which rests on the adiabatic theorem lies in the possibility of encoding a specific instance of a given decision problem in a certain Hamiltonian (this can be done by capitalizing on the well-known fact that any decision problem can be derived from an optimization problem by incorporating into it a numerical bound as an additional parameter). One then starts the system in a ground state of another Hamiltonian which is easy to construct, and slowly evolves the system in time, deforming it towards the desired Hamiltonian. According to the quantum adiabatic theorem and given the gap condition, the result of such a physical process is another energy ground state that encodes the solution to the desired decision problem. The adiabatic algorithm is thus a rather ‘laid back’ algorithm: one needs only to start the system in its ground state, deform it adiabatically, and measure its final ground state in order to retrieve the desired result. But whether or not this algorithm yields the desired "speed-up" depends crucially on the behavior of the energy gap as the number of degrees of freedom in the system increases. If this gap decreases exponentially with the size of the input, then the evolution time of the algorithm will increase exponentially; if the gap decreases polynomially, the decision problem so encoded could be solved efficiently in polynomial time. Although physicists have been studying spectral gaps for almost a century, they have never done so with quantum computing in mind. How this gap behaves in general remains thus far an open empirical question.
The quantum adiabatic algorithm holds much promise (Farhi et al. 2001), and recently it was shown (Aharonov et al. 2004) to be polynomially equivalent to the circuit model (that is, each model can simulate the other with only polynomial, i.e., modest, overhead of resources, namely, number of qubits and computational steps), but the caveat that is sometimes left unmentioned is that its application to an intractable computational problem may sometimes require solving another, as intractable a task (this general worry was first raised by a philosopher! see Pitowsky 1990). Indeed, Reichardt (2004) has shown that there are simple problems for which the algorithm will get stuck in a local minimum, in which there are exponentially many eigenvalues all exponentially close to the ground state energy, so applying the adiabatic theorem, even for these simple problems, will take exponential time, and we are back to square one.
3.3 Measurement-Based Algorithms
Measurement-based algorithms differ from the circuit model in that instead of applying unitary evolution as the basic mechanism for the manipulation of information, these algorithms use only non-unitary measurements as their computational steps. These models are especially interesting from a foundational perspective because they have no evident classical analogues and because they offer a new insight on the role of entanglement in quantum computing (Jozsa 2005). They may also have interesting consequences for experimental considerations, suggesting a different kind of computer architecture which is more fault tolerant (Nielsen and Dawson 2004).
The measurement-based algorithms fall into two categories. The first is teleportation quantum computing (based on an idea of Gottesman and Chuang 1999, and developed into a computational model by Nielsen 2003 and Leung 2003). The second is the "one way quantum computer", known also as the "cluster state" model (Raussendorf and Briegel 2000). The interesting feature of these models is that they are able to represent arbitrary quantum dynamics, including unitary dynamics, with basic non-unitary measurements. The measurements are performed on a pool of maximally entangled states, and are adaptive, i.e., each measurement is done in a different basis which is calculated classically, given the result of the earlier measurement (the first model uses measurements of 2 or more qubits, while the second uses only single qubit measurements; in the first model only bi-partite entanglement is used, while in the second one has multi-partite entanglement across all qubits). Such exotic models might seem redundant, especially when they have been shown to be polynomially equivalent to the standard circuit model in terms of computational complexity (Raussendorf et al. 2003). Their merit, however, lies in the foundational lessons they drive home: with these models the separation between the classical part (i.e., the calculation of the next measurement-basis) and the quantum parts (i.e., the measurement and the entangled states) of the computation becomes evident, hence it may be easier to pinpoint the quantum resources that are responisble for the putative "speed-up".
3.4 Topological-Quantum-Field-Theory (TQFT) Algorithms
Another exotic model for quantum computing which is attracting a lot of attention lately, especially from Microsoft inc. (Freedman 1998), is the Topological Quantum Field Theory model. In contrast to the straightforward and standard circuit model, this model resides in the most abstract reaches of theoretical physics. The exotic physical systems TQFT describes are topological states of matter. That the formalism of TQFT can be applied to computational problems was shown by Witten (1989) and the idea was later developed by others. Also here the model was proved to be efficiently simulated on a standard quantum computer (Freedman, Kitaev, Wang 2000, Aharonov et al. 2005), but its merit lies in its high tolerance to errors resulting from any possible realization of a large scale quantum computer (see below). Topology is especially helpful here because many global topological properties are, by definition, invariant under deformation, and given that most errors are local, information encoded in topological properties is robust against them.
3.5 Realizations
The quantum computer might be the theoretician's dream, but as far as experimentalists are concerned, its realization is a nightmare. The problem is that while some prototypes of the simplest elements needed to build a quantum computer have already been implemented in the laboratory, it is still an open question how to combine these elements into scalable systems. Shor's algorithm may break the RSA code, but it will remain an anecdote if the largest number that it can factor is 15. In the circuit-based model the problem is to achieve a scalable quantum system that at the same time will allow one to (1) robustly represent quantum information, (2) perform a universal family of unitary transformation, (3) prepare a fiducial initial state, and (4) measure the output result. Alternative paradigms may trade some of these requirements with others, but the gist will remain the same, i.e., one would have to achieve control of one's quantum system in such a way that the system will remain "quantum" albeit macroscopic or even mesoscopic in its dimensions.
Several ingenious solutions to the first two requirements above were devised, including quantum error correction codes (Shor 1995) and fault tolerant computation (Shor and DiVicenzo 1996, Aharonov and Ben-Or 1997) that dramatically reduce the spread of errors during a ‘noisy’ quantum computation. The problem, however, lies in the last two requirements. If one hopes to solve intractable problems efficiently with a scalable quantum computer, then the preparation of the input state and the measurement of the output state must be performed in such a way that will not increase the complexity of the computation. In other words, if the construction of the theoretical operator that measures a quantum state which encodes a solution to an NP-complete problem requires an exponential time, or even solving yet another NP-complete problem, then one has gained nothing by representing this solution in a quantum state.
4. Philosophical Implications
4.1 What is Quantum in Quantum Computing?
Notwithstanding the excitement around the discovery of Shor's algorithm, and apart from the almost insurmountable problem of practically realizing and implementing a large scale quantum computer, a crucial theoretical question remains open, namely, what physical resources are responsible for the putative power of quantum computing? Put another way, what are the essential features of quantum mechanics that allow one to solve problems or simulate certain systems far more efficiently than on a classical computer? Remarkable is also the fact that the relevance of features commonly thought essential to the superiority of quantum computers, e.g., entanglement and interference (Josza 1997), has recently been questioned (Linden and Popescu 1999, Biham 2004). Moreover, even if these features do play an essential role in the putative quantum "speed-up", it is still unclear how they do so (Fortnow 2003).
Theoretical as it may seem, the question "what is quantum in quantum computing?" has an enormous practical consequence. One of the embarrassments of quantum computing is the fact that, so far, only one algorithm has been discovered, namely Shor's, for which a quantum computer is significantly faster than any known classical one. It is almost certain that one of the reasons for this scarcity of quantum algorithms is related to the lack of our understanding of what makes a quantum computer quantum (see also Preskill 1998 and Shor 2004). As an ultimate answer to this question one would like to have something similar to Bell's (1964) famous theorem, i.e., a succinct crispy statement of the fundamental difference between quantum and classical systems, encapsulated in the non-commutative character of observables. Quantum computers, unfortunately, do not seem to allow such simple characterization. Observables—in the quantum circuit model there are only two, the preparation of the initial state and the observation of the final state, in the same basis, and of the same variable, at the end of the computation—are not as important here as in Bell's case since any measurement commutes with itself. The non-commutativity in quantum computing lies much deeper, and it is still unclear how to cash it into useful currency. Quantum computing skeptics (Levin 2003) happily capitalize on this puzzle: If no one knows why quantum computers are superior to classical ones, how can we be sure that they are, indeed, superior?
The elusive character of the physical resource responsible for the quantum "speed-up" can be nicely demonstrated with the following example. Consider a solution of a decision problem, say satisfiability, with a quantum algorithm based on the circuit model. What we are given here as input is a proposition in the propositional calculus and we have to decide whether it has a satisfying truth assignment. As Pitowsky (2002) shows, the quantum algorithm appears to solve this problem by testing all 2n assignments "at once", yet this quantum ‘miracle’ helps us very little since any measurement performed on the output state collapses it, and if there is one possible truth assignment that solves this decision problem, the probability of retrieving it is 2−n, just as in the case of a classical probabilistic Turing machine which guesses the solution and then checks it. Pitowsky's conclusion is that in order to enhance computation with quantum mechanics we must construct ‘clever’ superpositions that increase the probability of successfully retrieving the result far more than that of a pure guess. Shor's algorithm and the class of algorithms that evaluate a global property of a function (this class is known as the hidden subgroup class of algorithms) are (so far) a unique example of both a construction of such ‘clever’ superposition and a retrieval of the solution in polynomial time. The quantum adiabatic algorithm may give us similar results, contingent upon the existence of an energy gap that decreases polynomially with the input.
This question also raises important issues about how to measure the complexity of a given quantum algorithm. The answer differs, of course, according to the particular model at hand. In the adiabatic model, for example, one needs only to estimate the energy gap behavior and its relation to the input size (encoded in the number of degrees of freedom of the Hamiltonian of the system). In the measurement-based model, one counts the number of measurements needed to reveal the solution that is hidden in the input cluster state (since the preparation of the cluster state is a polynomial process, it does not add to the complexity of the computation). But in the circuit model things are not as straightforward. After all, the whole of the quantum-circuit-based computation can be be simply represented as a single unitary transformation from the input state to the output state.
This feature of the quantum circuit model supports the conjecture that the power of quantum computers, if any, lies not in quantum dynamics (i.e., in the Schrödinger equation), but rather in the quantum state, or the wave function. Another argument in favor of this conjecture is that the Hilbert subspace "visited" during a quantum computational process is, at any moment, a linear space spanned by all of the vectors in the total Hilbert space which have been created by the computational process up to that moment. But this Hilbert subspace is thus a subspace spanned by a polynomial number of vectors and is thus at most a polynomial subspace of the total Hilbert space. A classical simulation of the quantum evolution on a Hilbert space with polynomial number of dimensions (that is, a Hilbert space spanned by a number of basis vectors which is polynomial in the number of qubits involved in the computation), however, can be carried out in a polynomial number of classical computations. Were quantum dynamics important to the efficiency of quantum computing, the latter could be mimicked in a polynomial number of steps with a classical computer (see Unruh 2004 and Vidal 2003).
This is not to say that quantum computation is no more powerful than classical computation. The key point, of course, is that one does not end a quantum computation with an arbitrary superposition, but aims for a very special, ‘clever’ state—to use Pitowsky term. Quantum computations may not always be mimicked with a classical computer because the characterization of the computational subspace of certain quantum states is difficult, and it seems that these special, ‘clever’, quantum states cannot be classically represented as vectors derivable via a quantum computation in an optimal basis, or at least that one cannot do so in such way that would allow one to calculate the outcome of the final measurement made on these states.
Consequently, in the quantum circuit model one should count the number of computational steps in the computation not by counting the number of transformations of the state, but by counting the number of one- or two-qubit local transformations that are required to create the ‘clever’ superposition that ensures the desired "speed-up". (Note that Shor's algorithm, for example, involves three major steps in this context: First, one creates the ‘clever’ entangled state with a set of unitary transformations. The result of the computation—a global property of a function—is now ‘hidden’ in this state; second, in order to retrieve this result, one projects it on a subspace of the Hilbert space, and finally one performs another set of unitary transformations in order to make the result measurable in the original computational basis. All these steps count as computational steps as far as the efficiency of the algorithm is concerned. See also Bub 2006a.) The trick is to perform these local one- or two-qubit transformations in polynomial time, and it is likely that it is here where the physical power of quantum computing may be found.
4.2 Experimental Metaphysics?
The quantum information revolution has prompted several physicists and philosophers to claim that new insights can be gained from the rising new science into conceptual problems in the foundations of quantum mechanics (Fuchs 2002, Bub 2005). Yet while one of the most famous foundational problems in quantum mechanics, namely the quantum measurement problem, remains unsolved even within quantum information theory (see Hagar 2003 and Hagar and Hemmo 2006 for a critique of the quantum information theoretic approach to the foundations of quantum mechanics and the role of the quantum measurement problem in this context), quantum information theorists dismiss it as a philosophical quibble (Fuchs 2002). Indeed, in quantum information theory the concept of "measurement" is taken as a primitive, a "black box" which remains unanalyzed (see Dickson 2005 (Other Internet Resources) for a discussion on this view in the context of the "one way" quantum computer). The measurement problem itself, furthermore, is regarded as a misunderstanding of quantum theory. But recent advances in the realization of a large scale quantum computer may eventually prove quantum information theorists wrong: Rather than supporting the dismissal of the quantum measurement problem, these advances may surprisingly lead to its empirical solution.
The speculative idea is the following. As it turns out, collapse theories— one form of alternatives to quantum theory which aim to solve the measurement problem—modify Schrödinger's equation and give different predictions from quantum theory in certain specific circumstances. These circumstances may be realized, moreover, if decoherence effects could be suppressed (Bassi et al. 2005). Now one of the most difficult obstacles that await the construction of a large scale quantum computer is its robustness against decoherence effects (Unruh 1995). It thus appears that the technological capabilities required for the realization of a large scale quantum computer are exactly those upon which the distinction between "true" and "false" collapse (Pearle 1998), i.e., between collapse theories and environmentally induced decoherence, is contingent. Consequently, while quantum computing may elucidate the essential distinction between quantum and classical physics, its physical realization would shed light also on one of the long standing conceptual problems in the foundations of the theory, and would serve as yet another example of experimental metaphysics (the term was coined by Abner Shimony to designate the chain of events that led from the EPR argument via Bell's theorem to Aspect's experiments).
4.3 Are There Computational Kinds?
Another philosophical implication of the realization of a large scale quantum computer regards the long-standing debate in the philosophy of mind on the autonomy of computational theories of the mind (Fodor 1974). In the shift from strong to weak artificial intelligence, the advocates of this view tried to impose constraints on computer programs before they could qualify as theories of cognitive science (Pylyshyn 1984). These constraints include, for example, the nature of physical realizations of symbols and the relations between abstract symbolic computations and the physical causal processes that execute them. The search for the computational feature of these theories, i.e., for what makes them computational theories of the mind, involved isolating some features of the computer as such. In other words, the advocates of weak AI were looking for computational properties, or kinds, that would be machine independent, at least in the sense that they would not be associated with the physical constitution of the computer, nor with the specific machine model that was being used. These features were thought to be instrumental in debates within cognitive science, e.g., the debate between functionalism and connectionism (Fodor and Pylyshyn 1988).
Note, however, that once the physical Church-Turing thesis is violated, some computational notions cease to be autonomous. In other words, given that quantum computers may be able to efficiently solve classically intractable problems, hence re-describe the abstract space of computational complexity, computational concepts and even computational kinds such as ‘an efficient algorithm’ or ‘the class NP’, will become machine-dependent, and recourse to ‘hardware’ will become inevitable in any analysis thereof.
Advances in quantum computing may thus militate against the functionalist view about the unphysical character of the types and properties that are used in computer science. In fact, these types and categories may become physical as a result of this natural development in physics (e.g., quantum computing, chaos theory). Consequently, efficient quantum algorithms may also serve as counterexamples to a-priori arguments against reductionism (Pitowsky 1996).
Bibliography
- Adleman, L.M. (1994), ‘Molecular computation of solutions to combinatorial problems’, Science 266, 1021-1024.
- Aharonov, D. (1998), ‘Quantum computing’, Annual Review of Computational Physics VI (Singapore: World Scientific). [Preprint available online].
- Aharonov, D. and Ben-Or, M. (1997), ‘Fault tolerant computation with constant error’, Proc. ACM Symposium on the Theory of Computing (STOC), 176-188.
- Albert, D. (1983), ‘On quantum mechanical automata’, Phys. Lett. A 98, 249.
- Barenco, A. et al. (1995), ‘Elementary gates for quantum computation’, Phys. Rev. A 52, 3457–3467.
- Bell, J.S. (1964), ‘On the Einstein Podolsky Rosen paradox’, Physics 1, 195-200.
- Bennett, C. et al. (1997), ‘Strengths and weaknesses of quantum computing’, SIAM Journal on Computing 26(5), 1510-1523.
- Biham, E., et al. (2004), ‘Quantum computing without entanglement’, Theoretical Computer Science 320, 15-33.
- Bub, J. (2005), ‘Quantum mechanics is about quantum information’, Foundations of Physics 34, 541-560.
- Cirac, J.I. and Zoller, P. (1995), ‘Quantum computations with cold trapped ions’, Phys. Rev. Lett. 74, 4091-4094.
- Copeland, J. (2002), ‘Hypercomputation’, Minds and Machines 12, 461-502.
- Cook, S. A. (1971), ‘The complexity of theorem proving procedures’, Proc. 3rd ACM Symposium on Theory of Computing, 151-158.
- Davis, M. (1958), The Undecidable (New York: Dover).
- Davis, M. (2003), ‘The myth of hypercomputation’, pp. 195-212 in C. Teuscher (Ed.) Alan Turing, Life and Legacy of a Great Thinker (New York: Springer).
- Deutsch, D. (1985), ‘Quantum theory, the Church Turing principle, and the universal quantum computer’, Proc. Roy. Soc. Lond. A 400, 97-117.
- Deutsch, D. and Jozsa, R. (1992), ‘Rapid solution of problems by quantum computer’, Proc. Roy. Soc. Lond. A 439, 553-558.
- Dewdney A. K. (1984), ‘On the spaghetti computer and other analog gadgets for problem solving’, Scientific American 250(6),19-26.
- DiVicenzo, D. (1995), ‘Two-bit gates are universal for quantum computation’, Phys. Rev. A 51, 1015–1022.
- Ekert, A. and Jozsa, R. (1996), ‘Quantum computation and Shor's factoring algorithm’, Rev. Mod. Phys. 68(3), 733-753.
- Farhi, E. et al. (2001), ‘A quantum adiabatic evolution algorithm applied to random instances of an NP-complete problem’, Science 292(5516) 472-475.
- Feynman, R. (1982), ‘Simulating physics with computers’, International Journal of Theoretical Physics 21, 467-488.
- Fodor, J. (1974), ‘Special Sciences’, Synthese 2, 97-115.
- Fodor, J. and Pylyshyn, Z. (1988), ‘Connectionism and cognitive architecture, a critical analysis’, Cognition 28, 3-71.
- Fortnow, L. (2003), ‘One complexity theorist's view of quantum computing’, Theoretical Computer Science 292, 597-610.
- Freedman, M. (1998), ‘P/NP and the quantum field computer’, Proc. Natl. Acad. Sci. 95, 98-101.
- Gandy, R. (1980), ‘Church's thesis and principles for mechanisms’, in J. Barwise et al. (eds.) The Kleene Symposium, 123-148 (Amsterdam: North-Holland).
- Garey, M. R. and Johnson, D.S. (1979), Computers and intractability: A guide to the theory of NP-completeness (New York: WH Freeman).
- Giblin, P. (1993), Primes and Programming (Cambridge, Cambridge University Press).
- Gottesman, D. and Chuang, I. (1999), ‘Demonstrating the viability of universal quantum computation using teleportation and single-qubit operations’, Nature 402, 390-393.
- Grover, L. (1996), ‘A fast quantum mechanical algorithm for database search’, Proc. 28th ACM Symp. Theory of Computing, 212-219.
- Hagar, A. (2003), ‘A philosopher looks at quantum information theory’, Philosophy of Science 70, 752-775.
- Hagar, A. and Hemmo, M. (2006), ‘Explaining the unobserved: Why quantum mechanics ain't only about information’, Foundations of Physics, forthcoming. [Preprint available online]
- Hagar, A. and Korolev, A. (2006), ‘Quantum hypercomputability?’, Minds and Machines 16(1).
- Haroche, S. and Raimond, J.M. (1996), ‘Quantum computing: Dream or nightmare?’, Physics Today 8, 51-52.
- Hogarth, M. (1994), ‘Non-Turing computers and non-Turing computability’, PSA 94(1), 126-138.
- Holevo, A.S. (1973), ‘Bounds for the quantity of information transmitted by a quantum communication channel’, Problemy Peredachi Informatsii, 9(3), 3-11. English translation in Problems of Information Transmission 9, 177-183, 1973.
- Ingarden, R.S. (1976), ‘Quantum information theory’, Rep. Math. Phys. 10, 43-72.
- Jozsa, R. (1997), ‘Entanglement and quantum computation’, Ch. 27 in S. Hugget et al.. (eds.) The Geometric Universe (Oxford: OUP). [Preprint available online].
- Kieu, T.D. (2002), ‘Quantum Hypercomputability’, Minds and Machines 12, 541--561.
- Kieu, T.D. (2004), ‘A reformulation of Hilbert's Tenth Problem through quantum mechanics’, Proc. Royal Soc. A 460, 1535--1545
- Knill, E. et al., (2000), ‘An algorithmic benchmark for quantum information processing’, Nature 404, 368-370.
- Levin, L. (2003), ‘Polynomial time and extravagant models’, Problems of Information Transmission 39(1).
- Linden, N. and Popescu, S. (1999), ‘Good dynamics versus bad kinematics: Is entanglement needed for quantum computation?’, Phys. Rev. Lett. 87(4), 047901. [Preprint available online].
- Lipton, R. (1995), ‘Using DNA to solve NP-complete problems’, Science 268,542–545.
- Manin, Y. (1980), Computable and Uncomputable (Moscow: Sovetskoye Radio).
- Messiah, A. (1961), Quantum Mechanics, Volume II (New York: Interscience Publishers).
- Moore, C. (1990), ‘Unpredictability and undecidability in dynamical systems’, Phys. Rev. Lett. 64, 2354-2357.
- Myers, J. (1997), ‘ Can a universal quantum computer be fully quantum?’, Phys. Rev. Lett. 78(9), 1823-1824.
- Nielsen, M. (2003), ‘Quantum computation by measurement and quantum memory’, Phys. Lett. A 308, 96-100.
- Nielsen, M.A. and Chuang I.L. (2000), Quantum Computation and Quantum Information (Cambridge: Cambridge University Press).
- Pitowsky, I. (1990), ‘The physical Church thesis and physical computational complexity, Iyyun 39 81-99.
- Pitowsky. I. (1996), ‘Laplace's demon consults an oracle: The computational complexity of predictions’, Studies in the History and Philosophy of Modern Physics 27, 161-180.
- Pitowsky, I. (2002), ‘Quantum speed-up of computations’, Philosophy of Science 69 S168-S177.
- Pitowsky, I. and Shagrir, O. (2003), ‘Physical hypercomputation and the Church-Turing thesis’, Minds and Machines 13, 87-101.
- Poplavskii, R.P (1975), ‘Thermodynamical models of information processing’, (in Russian). Uspekhi Fizicheskikh Nauk 115(3),465-501.
- Pour-el, M. and Richards, I. (1981), The wave equation with computable initial data such that its unique solution is not computable’, Advances in Mathematics 39, 215-239.
- Preskill, J. (1998), ‘Quantum computing: Pro and Con’, Proc. Roy. Soc. Lond. A 454, 469-486.
- Pylyshyn, Z. (1984), Computation and Cognition: Toward a Foundation for Cognitive Science. (Cambridge: MIT Press).
- Rabin, M. (1976), ‘Probabilistic algorithms’, in J. Traub (ed.) Algorithms and Complexity: New Directions and Recent Results, 21-39. (New York: Academic Press).
- Reichardt, B.W. (2004), ‘The quantum adiabatic optimization algorithm and local minima’, Proceedings of the 36th Symposium on Theory of Computing (STOC), 502-510.
- Rivset R. et al. (1978), ‘A method for obtaining digital signatures and public-key cryptosystems’, Communications of the ACM 21(2), 120-126.
- Schrader et al. (2004), ‘Neutral atoms quantum register’, Phys. Rev. Lett. 93, 150501.
- Sieg W. and Byrnes J. (1999), ‘An abstract model for parallel computations’, The Monist 82, 150-164.
- Simon, D.R. (1994), ‘On the power of quantum computation’, Proc. 35th Symposium on Foundations of Computer Science.
- Shor, P. (1994) ‘Algorithms for quantum computation: Discrete logarithms and factoring’, Proc. 35th Annual Symposium on Foundations of Computer Science, 124-134.
- Shor, P. (1995), ‘Scheme for reducing decoherence in quantum computer memory’, Phys. Rev. A 52, 2493-2496.
- Shor, P. (1996), ‘Fault-tolerant quantum computation’, Proc. 37th Annual Symposium on Foundations of Computer Science, 56-65.
- Shor, P. (2004), ‘Progress in quantum computing’, Quantum Information Processing 3, 5-13. [Preprint available online].
- Shor, P. and DiVincenzo , D. (1996) ‘Fault tolerant error correction with efficient quantum codes’, Phys. Rev. Lett. 77, 3260-3263.
- Steane A.M. (1996), ‘Multiple particle interference and quantum error correction’, Proc. Roy. Soc. Lond. A 452, 2551-2577.
- Turing, A. (1936), ‘On computable numbers, with an application to the Entscheidungsproblem’, reprinted in M. Davis (Ed.) The Undecidable, pp. 115-153, (1958).
- Unruh,W.G. (1995), ‘Maintaining coherence in quantum computers’, Phys. Rev. A 51, 992-997.
- Unruh, W.G. (2004), ‘What is quantum in quantum computing’, A talk given in the 8th annual Seven Pines Symposium.
- Vergis, A. et al. (1986), ‘The complexity of analog computation’, Mathematics and Computers in Simulation 28, 91-113.
- Vidal, G. (2003), ‘Efficient classical simulation of slightly entangled quantum computations’, Phys. Rev. Lett. 91, 147902.
- Wiesner, S. (1983), ‘Conjugate coding’, Sigact news 18, 78-88.
- Witten, E. (1989), ‘Quantum field theory and the Jones polynomial’, Comm. Math. Phys. 121, 351-399.
- Wolfram, S. (1985), ‘Undecidability and intractability in theoretical physics’, Phys. Rev. Lett. 54, 735.
Other Internet Resources
Online Papers
- Aharonov, D. et al. (2004), ‘Adiabatic quantum computation is equivalent to standard quantum computation’, [Preprint available online].
- Aharonov, D. et al. (2005), ‘A polynomial quantum algorithm for approximating the Jones polynomial’, [Preprint available online].
- Bassi, A. et al. (2005), ‘Towards quantum superpositions of a mirror: stochastic collapse analysis’, [Preprint available online].
- Bub, J. (2006a), ‘Quantum information and computation’, [Preprint available online].
- Bub, J. (2006b), ‘Quantum computation from a quantum logical perspective’, [Preprint available online].
- Calude et al. (2003), ‘Transcending the limits of Turing computability’, [Preprint available online].
- Dickson, M. (2005), ‘Is measurement a “black box” ’?, [Preprint available online].
- DiVicenzo, D. (2000), ‘The physical implementation of quantum computation’, [Preprint available online].
- Farhi, E., et al. (2000), ‘Quantum computation by adiabatic evolution’, [Preprint available online].
- Freedman, M. et al. (2000), ‘Simulation of topological field theories by quantum computers’, [Preprint available online].
- Fuchs, C. (2002), ‘Quantum mechanics as quantum information (and only a little more)’, [Preprint available online].
- Hodges, A. (2005), ‘Can quantum computing solve classically unsolvable problems?’, [Preprint available online].
- Jozsa, R. (2005), ‘An introduction to measurement based quantum computation’, [Preprint available online].
- Leung, D. (2003), ‘Quantum computation by measurements’, [Preprint available online].
- Nielsen, M. and Dawson, C. (2004), ‘Fault-tolerant quantum computation with cluster states’, [Preprint available online].
- Pearle, P. (1998), ‘True and false collapse’, [Preprint available online].
- Popescu, S. and Linden, N. (1998), ‘The halting problem for quantum computers’, [Preprint available online].
- Preskill, J. (2005), Lecture notes for quantum computation. [Available online].
- Raussendorf, R. and Briegel, H. (2000), ‘Quantum computing via measurements only’, [Preprint available online].
- Raussendorf, R. et al. (2003), ‘Measurement-based quantum computation with cluster states’, [Preprint available online].
- Smith, W.D. (2005), Three counterexamples refuting Kieu's plan for "Quantum Adiabatic Hypercomputation"; and some uncomputable quantum mechanical tasks,’, [Preprint available online].
Web sites of interest
- Centre for Quantum Computation, Oxford and Cambridge, UK
- The Quantum Computer Project, MIT
- Centre for Quantum Computer Technology, Australia
- Institute of Quantum Computing, Canada
- Anton Zeilinger's Quantum Information Group, University of Vienna
- Samuel Braunstein's Quantum computation: a tutorial, University of York
- Umesh Vazirani's Quantum Computation Course, University of California/Berkeley
- Isaac Chuang's Course on Quantum Infromation Theory, MIT
Related Entries
Bell's Theorem | Church-Turing Thesis | computability and complexity | quantum mechanics | quantum mechanics: collapse theories | quantum mechanics: the role of decoherence in | quantum theory: measurement in | quantum theory: quantum entanglement and information | quantum theory: the Einstein-Podolsky-Rosen argument in | Turing, Alan | Turing machines