
Epistemic Utility Arguments for Probabilism
Our beliefs come in degrees; we believe some things more strongly than others. For instance, I believe that the sun will rise tomorrow very slightly more strongly than I believe that it will rise every morning for the coming week; and I believe both of these propositions much more strongly than I believe that there will be an earthquake tomorrow in Bristol. We call the strength or the degree of our belief in a proposition our credence in that proposition. Suppose I know that a die is to be rolled, and I believe that it will land on six more strongly than I believe that it will land on an even number. In this case, we would say that there is something wrong with my credences, for if it lands on six, it lands on an even number, and I ought not to believe a proposition more strongly than I believe a logical consequence of it. This follows from a popular doctrine in the epistemology of credences called Probabilism, which says that our credences at a given time ought to satisfy the axioms of the probability calculus (given in detail below). Since this says something about how our credences ought to be rather than how they in fact are, we call this an epistemic norm.
In this entry, we explore a particular strategy that we might deploy when we wish to establish an epistemic norm such as Probabilism. It is called epistemic utility theory or accuracy-first epistemology, or sometimes cognitive or epistemic decision theory. In this entry, we will use the former. Epistemic utility theory is inspired by traditional utility theory, so let’s begin with a quick summary of that.
Traditional utility theory (also known as decision theory, see entry on normative theories of rational choice: expected utility) explores a particular strategy for establishing the norms that govern which actions it is rational for us to perform in a given situation. Given a particular situation, the framework for the theory includes states of the world that are relevant to the situation, actions that are available to the agent in the situation, and the agent’s utility function, which takes a state of the world and an action and returns a measure of the extent to which she values the outcome of performing that action at that world. We call this measure the utility of the outcome at the world. For example, there might be just two relevant states of the world: one in which it rains and one in which it does not. And there might be just two relevant actions from which to choose: take an umbrella when you leave the house or don’t. Then your utility function will measure how much you value the outcomes of each action at each state of the world: that is, it will give the value of being in the rain without an umbrella, being in the rain with an umbrella, being with an umbrella when there is no rain, and being without an umbrella when there is no rain. With this framework in hand, we can state certain very general norms of action in terms of it. For instance, we might say that an agent ought not to perform an action if there is some other action that has greater utility than it at every possible state of the world. This norm is called Naive Dominance. We will have a lot to say about it in section 5.1 below.
In epistemic utility theory, the states of the world remain the same, but the possible actions an agent might perform are replaced by the possible epistemic states she might adopt, and the utility function is replaced, for each agent, by an epistemic utility function, which takes a state of the world and a possible epistemic state and returns a measure of the purely epistemic value that the agent attaches to being in that epistemic state at that state of the world. So, in epistemic utility theory, we appeal to epistemic utility to ask which of a range of possible epistemic states it is rational to adopt, just as in traditional utility theory we appeal to non-epistemic, pragmatic utility to ask which of a range of possible actions it is rational to perform. In fact, we will often talk of epistemic disutility rather than epistemic utility in this entry. But it is easy to translate between them. If \(\mathfrak{EU}\) is an epistemic utility function, then \(-\mathfrak{EU}\) is an epistemic disutility function, and vice versa.
Again, certain very general norms may be stated, such as the obvious analogue of Naive Dominance from above. Thus, before the die is rolled, we might ask whether I should adopt an epistemic state in which I believe that the die will land on six more strongly than I believe that it will land on an even number. And we might be able to show that I shouldn’t because there is some other epistemic state I could adopt instead that will have greater epistemic utility however the world turns out. In this case, we appeal to the epistemic version of Naive Dominance to show that my credences are irrational. This is an example of how epistemic utility theory might come to justify Probabilism. As we will see, arguments just like this have indeed been given. In this entry, we explore these arguments.
- 1. Modelling Epistemic States
- 2. The Form of Arguments in Epistemic Utility Theory
- 3. The Epistemic Norm of Probabilism
- 4. Calibration Arguments
- 5. Accuracy Arguments
- 6. Epistemic disutility arguments
- 7. Related issues
- Bibliography
- Academic Tools
- Other Internet Resources
- Related Entries
1. Modelling Epistemic States
In formal epistemology, epistemic states are modelled in many different ways (see entry on formal representations of belief). Given an epistemic agent and a time \(t\), we might model her epistemic state at \(t\) using any of the following:
- the set of propositions she believes at \(t\) (we might call this the full belief model; it is the object of study in much traditional epistemology and in doxastic and epistemic logic);
- the set of propositions she believes at \(t\) together with an entrenchment ordering, which specifies the order in which she is prepared to abandon her beliefs in the light of conflicting evidence (this is the ranking theory model);
- a single credence function at \(t\), which takes each proposition about which she has an opinion and returns her credence in that proposition at \(t\) (this is the precise credence or standard Bayesian model);
- a set of credence functions, each of which is a precisification of her otherwise vague or imprecise or indeterminate credences at \(t\) (this is the imprecise credence model);
- her upper and lower probability functions at \(t\);
- and so on.
Epistemic utility theory may be applied to any one of these ways of modelling epistemic states. Whichever we choose, we define an epistemic disutility function to be a function that takes an epistemic state modelled in this way, together with a state of the world, to a non-negative real number or the number \(\infty\), and we take this number to measure the epistemic disutility of having that epistemic state at that world.
The vast majority of work carried out so far in epistemic utility theory has taken an agent’s epistemic state at time \(t\) to be modelled by her credence function at \(t\). And, in any case, the epistemic norm of Probabilism that interests us here governs agents modelled in this way. Thus, we focus on this case. In section 7, we will consider how the argument strategy employed here to justify Probabilism for agents with precise credences might be employed to establish other norms either for agents also represented as having precise credences or for agents represented in other ways.
So, henceforth, we model an agent’s epistemic state at \(t\) by her credence function at \(t\). We now make more precise what this means. We assume that the set of propositions about which an agent has an opinion is finite and forms an algebra \(\mathcal{F}\). That is:
- It contains a contradictory proposition (\(\bot\)). This is a proposition that is false at all worlds.
- It contains a tautologous proposition (\(\top\)). This is a proposition that is true at all worlds.
- It is closed under disjunction, conjunction, and negation. That is, if \(A\) and \(B\) are in \(\mathcal{F}\), then \(A \vee B\), \(A\ \&\ B\), and \(\neg A\) and \(\neg B\) are also in \(\mathcal{F}\).
We then assume that our agent’s credence in a proposition in \(\mathcal{F}\) can be measured by a real number between 0 and 1 inclusive, where 0 represents minimal credence, and 1 represents maximal credence. Then her credence function at \(t\) is a function c from \(\mathcal{F}\) to the closed unit interval \([0, 1]\). If \(A\) is in \(\mathcal{F}\), then \(c(A)\) is our agent’s credence in \(A\) at \(t\). Throughout, we denote by \(\mathcal{C_F}\) the set of possible credence functions defined on \(\mathcal{F}\). There is no principled reason for restricting to the case in which \(\mathcal{F}\) is finite. We do it here only because the majority of work on this problem has been carried out under this assumption. It is an interesting question how the results here might be extended to the case in which \(\mathcal{F}\) is infinite, but we will not explore it here (again, see section 7).
So, an epistemic utility function for credences takes a credence function, together with a way the world might be, and returns a measure of the epistemic utility of having that credence function if the world were that way.
2. The Form of Arguments in Epistemic Utility Theory
In epistemic utility theory, we attempt to justify an epistemic norm N using the following two ingredients:
- QA norm of standard utility theory (or decision theory), which is to be applied, using epistemic utility functions, to discover which credence functions it is rational for an agent to adopt in a given situation.
- EA set of conditions that a legitimate measure of epistemic utility must satisfy.
Typically, the inference from Q and E to N appeals to a mathematical theorem, which shows that, applied to any epistemic utility function that satisfies the conditions E, the norm Q entails the norm N.
Given that the existing arguments of epistemic utility theory share this common form, we might organize these arguments by the norms they attempt to justify, or by the norms of standard utility theory they employ, or by the set of constraints on epistemic utility functions they impose. We will take the latter course in this survey.
In sections 4 and 5, we identify a specific epistemic goal and treat epistemic disutility functions as measures of the distance of an epistemic state from that goal in a given situation; we lay down conditions that it is claimed all such measures must satisfy. In section 6, we take an alternative route: we lay down putative general conditions on any epistemic disutility function, which it is claimed such a function must satisfy regardless of whether or not it is a measure of distance from a specified epistemic goal. In the next section, we state Probabilism precisely, so that we can refer back to it later.
3. The Epistemic Norm of Probabilism
Probabilism is often said to be a coherence constraint on credence functions, which would mean that it governs how an agent’s credences in some propositions should relate to her credences in other, related propositions. It is often likened to the consistency constraint on sets of full beliefs. In fact, this isn’t quite right. Condition (ii) below is certainly a coherence constraint, but condition (i) is not.
Probabilism A rational agent’s credence function \(c\) at a given time is a probability function. That is:
- \(c(\bot) = 0\) and \(c(\top) = 1\).
- \(c(A \vee B) = c(A) + c(B)\), for all mutually exclusive \(A\) and \(B\) in \(\mathcal{F}\).
Note that any agent who satisfies Probabilism must be logically omniscient: that is, she must be certain of every tautology. Some other consequences of Probabilism:
- \(c(A) \leq c(A \vee B)\) for any \(A\), \(B\) in \(\mathcal{F}\).
- \(c(A\ \&\ B) \leq c(A)\) for any \(A\), \(B\) in \(\mathcal{F}\).
- \(c(A) = c(B)\) if \(A\) and \(B\) are logically equivalent.
Probabilism is one of a handful of norms that characterise the Bayesian view in credal epistemology.
4. Calibration Arguments
In this section, we consider the conditions imposed on an epistemic disutility function when we treat it as a measure of the distance of an epistemic state from the goal of being actually or hypothetically calibrated (van Fraassen 1983; Lange 1999; Shimony 1988). We say that a credence function is actually calibrated at a particular possible world if the credence it assigns to a proposition matches the relative frequency with which propositions of that kind are true at that world. Thus, credence 0.2 in proposition \(A\) is actually calibrated if one-fifth of propositions like \(A\) are actually true. And we say that a credence function is hypothetically calibrated if the credence it assigns to a proposition matches the limiting relative frequency with which propositions of that kind would be true were there more propositions of that kind. Thus, credence 0.2 in proposition \(A\) is hypothetically calibrated if, as we move to worlds with more and more propositions like \(A\), the proportion of such propositions that are true approaches one-fifth in the limit. According to the calibration arguments, matching these relative frequencies or limiting relative frequencies is an epistemic goal. And they attempt to justify Probabilism by appealing to this goal and measures of distance from it.
4.1 Calibration measures
First, we must make precise what we mean by actual and hypothetical calibration; then we can say which functions will count as measuring distance from these putative goals. We treat actual calibration first. Since we are talking of relative frequencies, we will need to assign to each proposition in \(\mathcal{F}\) its reference class: that is, the set of propositions that are relevantly similar to it. Thus, we require an equivalence relation \(\sim\) on \(\mathcal{F}\), where \(A \sim B\) iff \(A\) and \(B\) are relevantly similar. For instance, if our algebra of propositions contains Heads on first toss of coin, Heads on second toss of coin, and Six on first roll of die, we might plausibly say that the first two are relevantly similar, but neither first nor second is relevantly similar to the third. Proponents of calibration arguments do not claim to give an account of how the equivalence relation is determined. Nor do they claim that there is a single, objectively correct equivalence relation on a given algebra of propositions: this is the notorious problem of the reference class that haunts frequentist interpretations of objective probability. Rather they treat the equivalence relation as a component of the agent’s epistemic state, along with her credence function. Indeed, for van Fraassen, it is determined entirely by the credence function together with the form of the propositions in \(\mathcal{F}\) (van Fraassen 1983: 299). However, they do impose some rational constraints on \(\sim\) in order to establish their conclusion. We will not discuss these conditions in any detail. Rather we denote them \(C(\sim)\), and keep in mind that this is a placeholder for a full account of conditions on \(\sim\). Detailed accounts of these conditions have been given by van Fraassen (1983) and Shimony (1988). We say that a credence function \(c\), together with an equivalence relation \(\sim\), is perfectly calibrated or not relative to a way the world might be. We are now ready to give our first definitions; but we preface these with an example.
Suppose a coin is to be flipped 1000 times. And suppose that \(A\) is the proposition Heads on toss 1. And suppose that the propositions that are relevantly similar to \(A\) in algebra \(\mathcal{F}\) are: Heads on toss 1, …Heads on toss 1000. Finally, suppose that \(w\) is a possible world; a way that the world might be. In fact, throughout this article, we need not quantify over genuine possible worlds, which are maximally specific ways the world might be; we need only quantify over ways the world might be that are specific enough to assign truth values to each of the propositions in the algebra \(\mathcal{F}\). Let’s call these possible worlds relative to \(\mathcal{F}\) and let \(\mathcal{W_F}\) be the set of them for a given algebra \(\mathcal{F}\). Then the relative frequency of \(A\) at \(w\) (written \(\mathrm{Freq}(\mathcal{F}, A, \sim, w)\)) is the proportion of the propositions relevantly similar to \(A\) that are true at \(w\): that is, the frequency of heads amongst the 1000 coin tosses at that world. For instance, if every second toss lands heads at \(w\), or if the first five hundred land heads and the rest land tails at \(w\), then \(\mathrm{Freq}(\mathcal{F}, A, \sim, w) = \frac{1}{2}\). If every third toss lands heads at \(w\), then \(\mathrm{Freq}(\mathcal{F}, A, \sim, w) = \frac{1}{3}\). And so on.
Now we give the definition in full generality. Suppose \(\sim\) is an equivalence relation on \(\mathcal{F}\), and \(w\) is a possible world relative to \(\mathcal{F}\). Then:
- For each \(A\) in \(\mathcal{F}\), the relative frequency of truths among propositions like \(A\) is defined as follows: \[\mathrm{Freq}(\mathcal{F}, A, \sim, w) := \frac{|\{ X \in \mathcal{F} : X \sim A\ \&\ v_w(X) = 1\}|}{|\{X \in \mathcal{F} : X \sim A\}|}\] where \(|X|\) is the cardinality of the set \(X\) and \(v_w\) is the standard numerical truth value assignment at that world, so that \(v_w(X) = 1\) if \(X\) is true at \(w\) and \(v_w(X) = 0\) if \(X\) is false at \(w\) (we call \(v_w\) the omniscient credence function at \(w\)). Thus, \(\mathrm{Freq}(\mathcal{F}, A, \sim, w)\) is the proportion of true propositions amongst all propositions in \(\mathcal{F}\) that are relevantly similar to the proposition \(A\).
- Relative to \(\sim\), the credence r in proposition \(A\) is actually calibrated at \(w\) if \(r = \mathrm{Freq}(\mathcal{F}, A, \sim, w)\).
The idea is that, if \(\sim\) satisfies constraints \(C(\sim)\), then the function \(\mathrm{Freq}(\mathcal{F}, \cdot, \sim, w)\) is always a probability function on \(\mathcal{F}\).
Next, we treat hypothetical calibration. For this, we need the notion of the limiting relative frequency of truths amongst propositions of a certain sort. The idea is that, for each proposition \(A\) in \(\mathcal{F}\), there is not just a fact of the matter about what the frequency of truths amongst propositions like \(A\) actually is; there is also a fact of the matter about what the frequency of truths amongst propositions like \(A\) would be if there were more propositions like \(A\). For instance, there is not just a fact of the matter about how many actual tosses of a given coin will land heads; there is also a fact of the matter about the frequency of heads amongst hypothetical further tosses of the same coin. In general, suppose we have a possible world \(w\), an extension \(\mathcal{F}'\) of \(\mathcal{F}\) (containing new propositions like \(A\)), and an extension \(\sim'\) of \(\sim\) to cover the new propositions in \(\mathcal{F}'\). Then there is a single unique number \(\mathrm{Freq}(\mathcal{F}', A, \sim', w)\) that gives what the relative frequency of truths amongst propositions like \(A\) would be were there all the propositions in \(\mathcal{F}'\) and where the relation of similarity amongst them is given by \(\sim'\), where this counterfactual is evaluated at the world \(w\). Again, let us illustrate this using our example of the coin toss from above.
Suppose again that \(A\) is the proposition Heads on toss 1 and that the propositions in \(\mathcal{F}\) that are relevantly similar to \(A\) according to \(\sim\) are Heads on toss 1, …, Heads on toss 1000. Now suppose that \(\mathcal{F}_1\) extends \(\mathcal{F}\) by introducing a new proposition about a further hypothetical toss of the coin (as well as perhaps other propositions). That is, it introduces Heads on toss 1001 (and closes out under negation, disjunction, and conjunction). And suppose that \(\sim_1\) extends \(\sim\), so that the new proposition Heads on toss 1001 is considered relevantly similar to each Heads on toss 1, …, Heads on toss 1000. Then those who appeal to hypothetical limiting frequencies must claim that there is a unique number that gives what the frequency of heads would be, were the coin tossed 1001 times. They denote this number \(\mathrm{Freq}(\mathcal{F}_1, A, \sim_1, w)\). Now suppose that \(\mathcal{F}_2\) extends \(\mathcal{F}_1\) by adding the new proposition Heads on toss 1002 and \(\sim_2\) extends \(\sim_1\), so that the new proposition Heads on toss 1002 is considered relevantly similar to each Heads on toss 1, …, Heads on toss 1001. And so on. Then the limiting relative frequency of \(A\) at \(w\) (written \(\mathrm{LimFreq}(\mathcal{F}, A, \sim, w)\)) is the number towards which the following sequence tends: \[\mathrm{Freq}(\mathcal{F}, A, \sim, w), \mathrm{Freq}(\mathcal{F}_1, A, \sim_1, w), \mathrm{Freq}(\mathcal{F}_2, A, \sim_2, w), \ldots\]
In general, for each algebra \(\mathcal{F}\) and equivalence relation \(\sim\), there is an infinite sequence \[(\mathcal{F}, \sim) = (\mathcal{F}_0, \sim_0), (\mathcal{F}_1, \sim_1), (\mathcal{F}_2, \sim_2), \ldots\] of pairs of algebras \(\mathcal{F}_i\) and equivalence relations \(\sim_i\) such that each \(\mathcal{F}_{i+1}\) is an extension of \(\mathcal{F}_i\) and each \(\sim_{i+1}\) is an extension of \(\sim_i\) and, for each \(i\), \(C(\sim_i)\). Using this, we can define the notion of limiting relative frequency and the associated notion of hypothetical calibration in full generality. Suppose \(\sim\) is an equivalence relation on \(\mathcal{F}\) and \(w\) is a possible world. And suppose \[(\mathcal{F}_0, \sim_0), (\mathcal{F}_1, \sim_1), (\mathcal{F}_2, \sim_2), \ldots\] is the sequence just mentioned. Then:
- For each \(A\) in \(\mathcal{F}\), the limiting relative frequency of truths among propositions like \(A\) is \[\mathrm{LimFreq}(\mathcal{F}, A, \sim, w) := \lim_{n \rightarrow \infty} \mathrm{Freq}(\mathcal{F}_n, A, \sim_n, w)\] That is, the limiting relative frequency of \(A\) is the number approached arbitrarily closely by the hypothetical relative frequencies of truths as we extend the algebra \(\mathcal{F}\) to include more and more propositions like \(A\).
- Relative to \(\sim\), the credence r in proposition \(A\) is hypothetically calibrated at \(w\) if \[r = \mathrm{LimFreq}(\mathcal{F}, A, \sim, w)\]
According to some calibration arguments, actual calibration is an epistemic goal; according to others, hypothetical calibration is the goal. Whichever it is, the epistemic disutility of a credence ought to be given by its distance from this epistemic goal. We say that an epistemic disutility function is local if it measures only the epistemic disutility of an individual credence at a world; we say that it is global if it measures the epistemic disutility of an entire credence function at a world. In this section, we will be concerned only with local epistemic disutility functions. In sections 5 and 6, we will be concerned instead with global epistemic disutility functions.
The goals of actual calibration and hypothetical calibration give rise to the following definitions of two sorts of local epistemic disutility function:
- An actual calibration measure is a function of the form \[\mathfrak{c}(r, A, \mathcal{F}, \sim, w) = f(|\mathrm{Freq}(\mathcal{F}, A, \sim, w) - r|)\] where \(f : [0, 1] \rightarrow \mathbb{R}\) is a strictly increasing continuous function with \(f(0) = 0\). Let Actual Calibration be the claim that \(\mathfrak{c}\) is the measure of epistemic disutility.
- A hypothetical calibration measure is a function of the form \[\mathfrak{hc}(r, A, \mathcal{F}, \sim, w) = f(|\mathrm{LimFreq}(\mathcal{F}, A, \sim, w) - r|)\] where again \(f : [0, 1] \rightarrow \mathbb{R}\) is a strictly increasing continuous function with \(f(0) = 0\). Let Hypothetical Calibration be the claim that \(\mathfrak{hc}\) is the measure of epistemic disutility.
Our next task is to identify the norms of standard decision theory/utility theory that are deployed in conjunction with this characterization to derive Probabilism.
4.2 Calibration arguments for Probabilism
In this section, we consider the two accounts of epistemic disutility for credences given in the previous section and we combine them with decision-theoretic norms to derive epistemic norms. When we state the decision-theoretic norms in question, we state them in full generality. In practical decision theory, we evaluate acts: it is acts that have practical disutilities at worlds. In epistemic decision theory, on the other hand, we evaluate credence functions: it is credence functions that have epistemic disutilities at worlds. And in another context still, we might wish to use decision theory to evaluate some other sort of thing, such as a scientific theory (Maher 1993). So we want to state the decision-theoretic norms in a way that is neutral between these. We will talk of options as the things that are being evaluated and that have utilities at worlds. Options can thus be acts or credence functions or scientific theories or some other sort of thing.
Here’s our first putative norm of standard decision theory (van Fraassen 1983: 297):
Possibility of Vindication A rational agent will not adopt an option that has no possibility of attaining minimal disutility, when such a minimum exists.
Here it is a little more formally: Suppose \(\mathcal{O}\) is a set of options, \(\mathcal{W}\) is the set of possible worlds, and \(\mathfrak{U}\) is a disutility function. Then, if \(o^*\) is an option, and there is no \(w^*\) in \(\mathcal{W}\) such \[\mathfrak{U}(o^*, w^*) = \min \{\mathfrak{U}(o, w) : o \in \mathcal{O}\ \&\ w \in \mathcal{W}\}\] (when this minimum exists), then \(o^*\) is irrational.
It can be shown that, together with Actual Calibration from the previous section and suitable constraints \(C(\sim)\) on the equivalence relation \(\sim\), this norm entails something stronger than Probabilism. It entails:
Rational-valued Probabilism At any time \(t\), a rational agent’s credence function \(c\) is a probability function that takes only values in \(\mathbb{Q}\) (where \(\mathbb{Q}\) is the set of rational numbers).
This is a consequence of the following theorem:
Theorem 1 Suppose \(\mathfrak{c}\) is a calibration measure and suppose \(C(\sim)\). Then the following are equivalent:
- \(c\) is a probability function on \(\mathcal{F}\) that takes only values in \(\mathbb{Q}\);
- There is a world at which \(c\) is actually calibrated. That is, there is a world \(w\) in \(\mathcal{W}\) such that, for all \(A\) in \(\mathcal{F}\), \(\mathfrak{c}(c(A), A, \mathcal{F}, \sim, w) = 0\).
Different versions of this theorem result from different constraints \(C(\sim)\) on the equivalence relation \(\sim\) (van Fraassen 1983; Shimony 1988), but the result is not surprising. An agent will satisfy Possibility of Vindication just in case her credences match the relative frequencies at some world. And those relative frequencies will satisfy the probability axioms if \(C(\sim)\) and if we have specified that condition correctly. That they will be rational numbers follows from the definition of the relative frequency of a proposition at a world.
Thus, we have the following argument:
Actual Calibration argument for Rational-valued Probabilism
- \((1)\)Actual Calibration
- \((2)\)Possibility of Vindicatione
- \((3)\)Theorem 1
- Therefore,
- \((4)\)Rational-valued Probabilism
Most proponents of the calibration argument are reluctant to accept a norm that rules out every credence given by an irrational number. To establish the weaker norm of Probabilism, there are two strategies they might adopt. The first is to appeal to the epistemic goal of hypothetical calibration instead of actual calibration. This, together with Possibility of Vindication gives us Probabilism via the following theorem:
Theorem 2 Suppose \(C(\sim)\). Then the following are equivalent:
- \(c\) is a probability function on \(\mathcal{F}\).
- There is a world at which \(c\) is hypothetically calibrated. That is, there is a world \(w\) in \(\mathcal{W}\) such that, for all \(A\) in \(\mathcal{F}\), \(\mathfrak{hc}(c(A), A, \mathcal{F}, \sim, w) = 0\).
The reason is that, while relative frequencies are always rational numbers, the limit of an infinite sequence of rational numbers may be an irrational number. And, in fact, for any irrational number, there is a sequence of rational numbers that approaches it in the limit (indeed, there are infinitely many such sequences).
Thus, we have the following argument:
Hypothetical Calibration argument for Probabilism
- \((1)\)Hypothetical Calibration
- \((2)\)Possibility of Vindication
- \((3)\)Theorem 2
- Therefore,
- \((4)\)Probabilism
An alternative route to Probabilism changes the decision-theoretic norm to which we appeal, rather than the sort of calibration from which we wish our epistemic disutility function to measure distance. The alternative norm is:
Possibility of Arbitrary Closeness to Vindication. An agent ought not to adopt an option unless there are worlds at which it is arbitrarily close to achieving minimal disutility.
That is: Suppose \(\mathcal{O}\) is a set of options, \(\mathcal{W}\) is the set of possible worlds, and \(\mathfrak{U}\) is a disutility function. Then, if \(o^*\) is an option, and if it is not the case that, for any \(\varepsilon > 0\), there is a possible world \(w^*_\varepsilon\) in \(\mathcal{W}\) such \[| \mathfrak{U}(o^*, w^*_\varepsilon) - \min \{\mathfrak{U}(o, w) : o \in \mathcal{O}\ \&\ w \in \mathcal{W}\}| < \varepsilon\] (when these minima exist), then \(o^*\) is irrational.
Together with the characterization of calibration measures given above, suitable constraints \(C(\sim)\) on the equivalence relation \(\sim\), and two extra assumptions, this norm does establish Probabilism. The extra assumptions are these: First, if our agent has a credence function \(c\) in \(\mathcal{C_F}\), the possible worlds that we are considering include not only all (consistent) truth assignments to \(\mathcal{F}\), but also any (consistent) truth assignments to any (finite) algebra \(\mathcal{F}'\) that extends \(\mathcal{F}\). And, second, given any such \(\mathcal{F}'\), the equivalence relation \(\sim\) can be extended in any possible way, providing the extension \(\sim'\) of \(\sim\) satisfies \(C(\sim')\).
Theorem 3 Suppose \(C(\sim)\). Then the following are equivalent:
- \(c\) is a probability function on \(\mathcal{F}\).
- For all \(\varepsilon > 0\), there is a finite extension \(\mathcal{F}'\) of \(\mathcal{F}\) and an extension \(\sim'\) of \(\sim\) that satisfies \(C(\sim')\), and a possible world \(w'\) in \(\mathcal{W}\) such that, for all \(A\) in \(\mathcal{F}\), \(\mathfrak{c}(c(A), A, \mathcal{F}', \sim', w') < \varepsilon\)
Thus, if our agent satisfies Probabilism, then however close she would like to be to actual calibration, there is some possible world at which she is that close. And conversely.
Thus, we have the following argument:
Actual Calibration argument for Probabilism
- \((1)\)Actual Calibration
- \((2)\)Possibility of Arbitrary Closeness to Vindication
- \((3)\)Theorem 3
- Therefore,
- \((4)\)Probabilism
These are the calibration arguments for Probabilism. In the next section, we consider objections that may be raised against them.
4.3 Objections to calibration arguments for Probabilism
Objection 1: Calibration is not an epistemic goal. It may be objected that neither actual nor hypothetical calibration measures are truth-directed epistemic disutility functions, where this is taken to be a necessary condition on such a function (Joyce 1998: 595; Seidenfeld 1985). We say that a local epistemic disutility function—that is, recall, an epistemic disutility function defined for individual credences—is truth-directed if the disutility that it assigns to a credence in a true proposition increases as the credence decreases, and the disutility it assigns to a credence in a false proposition increases as the credence increases. Calibration measures do not have this property. To see this, let us return to our toy example: the propositions Heads on toss 1, …, Heads on toss 1000 are in \(\mathcal{F}\) and they are all relevantly similar according to \(\sim\). Now suppose that the first coin toss lands heads, but all the others land tails. Then credence 0.001 in Heads on toss 1 is actually calibrated, since exactly one out of one-thousand relevantly similar propositions are true; so it has epistemic disutility 0. Credence 0.993, on the other hand, is not, and thus receives a positive epistemic disutility. However, it is a higher credence in a true proposition, and thus should be assigned a lower epistemic disutility, according to the requirement of truth-directedness. One natural response to this objection is that it is question-begging. Proponents of the calibration argument will simply reject the claim that an epistemic disutility function must be truth-directed. Credences, unlike beliefs, they might say, are not in the business of getting close to the truth; they are in the business of getting close to being calibrated.
Objection 2: Limiting relative frequencies are not well-defined. To define the limiting relative frequency of \(A\) at a world \(w\), we require that there is a unique sequence of extensions of the algebra each of which contains more propositions that are relevantly similar to \(A\) than the previous extension, and a corresponding sequence of relative frequencies of truths amongst the propositions like \(A\) in the corresponding algebra. But the assumption of such a unique sequence is extremely controversial and the problems to which it gives rise have haunted hypothetical frequentism about objective probability (Hájek 2009).
Objection 3: Neither Possibility of Vindication nor Possibility of Arbitrary Closeness to Vindication is a norm. It might be that the only actions that give rise to the possibility of vindication or of arbitrary closeness to vindication also give rise to the possibility of maximal distance from vindication. And it might be that there are actions that do not give rise to the possibility of vindication or of arbitrary closeness to vindication, but do limit the distance from vindication that is risked by choosing that action. In such cases, it is not at all clear that it is rationally required of an agent that she ought to risk maximal distance from vindication in order to leave open the possibility of vindication or of arbitrary closeness to vindication. Compare: I have two options—if I choose option 1, I will receive £0 or £100, but I don’t know which; if I choose option 2, I will receive £99 for sure. Even before they know the objective chances of the two possibilities that the first option creates, many people will opt for the second. However, by doing so, they rule out the possibility that they will receive the maximum possible utility, which is obtained by option 1 if I receive £100. It seems that ruling out such a possibility is not irrational. To put it another way: Possibility of Vindication and Possibility of Arbitrary Closeness to Vindication are extreme risk-seeking norms. That is, they suggest that we make our decisions by trying to maximise the utility we obtain in our best-case scenario. But while it might be rationally permissible to be so risk-seeking, it is certainly not mandatory (Easwaran & Fitelson 2015: Section 8).
Objection 4: The constraints on \(\sim\) are ill-motivated. This objection will vary with the constraints \(C(\sim)\) that are imposed on \(\sim\). One uncontroversial constraint is this: If \(A \sim B\), then \(c(A) = c(B)\). The further constraints imposed by Shimony (1988) and van Fraassen (1983) are more controversial (Joyce 1998: 594–6). Moreover, they limit the application of the result, since they involve assumptions about the form of the propositions in \(\mathcal{F}\). Thus, the calibration arguments do not show in general, of any finite algebra \(\mathcal{F}\), that a credence function on \(\mathcal{F}\) ought to be a probability function, since not every such algebra will contain propositions with the form required by the constraints \(C(\sim)\).
5. Accuracy Arguments
In this section, we move from calibration arguments to accuracy arguments for Probabilism. These arguments have the same structure as the calibration arguments. They consist of a mathematically-precise account of epistemic disutility and a decision-theoretic norm. And they derive, from that norm together with that account of disutility, an epistemic norm. In particular, they derive Probabilism. And that derivation goes via a mathematical theorem. However, they will use different accounts of epistemic disutility and different decision-theoretic norms.
In this section, we will begin with the original accuracy-based argument for Probabilism due to James M. Joyce (1998; see also Rosenkrantz 1981; both versions, as well as subsequent versions, build on mathematical results due to de Finetti (1974)). Then we’ll consider its various components in turn, and explore the objections they have elicited and the adjustments that have been made to them.
5.1 Joyce’s accuracy argument for Probabilism
Joyce’s argument consists of an account of the epistemic disutility of credences and a decision-theoretic norm. Let’s consider each in turn.
Joyce’s account of the epistemic disutility of credences itself consists of two components. The first identifies epistemic disutility with gradational inaccuracy; the second gives a mathematically-precise account of gradational inaccuracy.
In more detail: The first component of Joyce’s account of epistemic disutility for credences is the claim—which we will call Credal Veritism, partly following Goldman (2002: 58)—that the only source of value for credences that is relevant to their epistemic status is their gradational accuracy, where the gradational accuracy of a credence in a true proposition is higher when the credence is closer to 1, which we might think of as the ideal or vindicated credence in a true proposition, while the gradational accuracy of a false proposition is higher when the credence is closer to 0, which we might think of as the ideal or vindicated credence in a false proposition. Thus, the only source of disvalue for credences is their gradational inaccuracy.
The second component of Joyce’s account of epistemic disutility for credences is a set of mathematically-precise conditions that a measure of the gradational inaccuracy of a credence function at a given possible world must satisfy. A putative inaccuracy measure for credence functions over an algebra \(\mathcal{F}\) is a mathematical function \(\mathfrak{I}\) that takes a credence function \(c\) in \(\mathcal{C_F}\) and a possible world \(w\) in \(\mathcal{W_F}\) and returns a number \(\mathfrak{I}(c, w)\) in \([0, \infty]\) that measures the inaccuracy of \(c\) at \(w\). (The set \([0, \infty]\) contains all non-negative real numbers together with \(\infty\).) Here is an example, called the Brier score: \[\mathfrak{B}(c, w) := \sum_{X \in \mathcal{F}} |v_w(X) - c(w)|^2\] Thus, the Brier score measures the inaccuracy of a credence function at a world as follows: it takes each proposition to which the credence function assigns credences; it takes the difference between the credence that the credence function assigns to that proposition and the ideal or vindicated credence in that proposition at that world; it squares this difference; and it sums up the results. We shall not give all of Joyce’s conditions here, but just note that the Brier score just defined satisfies them all. Let us say that any putative inaccuracy measure \(\mathfrak{I}\) that satisfies these conditions is a Joycean inaccuracy measure. And let Joycean Inaccuracy be the claim that all legitimate inaccuracy measures are Joycean inaccuracy measures.
Combining Credal Veritism and Joycean Inaccuracy, we have the claim that the epistemic disutility of a credence function at a world is given by its inaccuracy at that world as measured by a Joycean inaccuracy measure.
Let us turn now to the decision-theoretic norm to which Joyce appeals. We have met it already above in the introduction to this article: it is the norm of Naive Dominance. We will state it here precisely:
Naive Dominance A rational agent will not adopt an option when there is another option that has lower disutility at all worlds.
That is: Suppose \(\mathcal{O}\) is a set of options, \(\mathcal{W}\) is the set of possible worlds, and \(\mathfrak{U}\) is a disutility function. Then, if \(o^*\) is an option, and if there is another option \(o'\) such that \(\mathfrak{U}(o', w) < \mathfrak{U}(o^*, w)\) for all worlds \(w\) in \(\mathcal{W}\), then \(o^*\) is irrational. (In this situation, we say that \(o^*\) \(\mathfrak{U}\)-dominates \(o'\).)
The idea behind Naive Dominance is this: If there is one option that is guaranteed to have lower disutility than another option, then the latter is guaranteed to be worse than the former; so the agent can know a priori that the latter is worse than the former. And surely it is irrational to adopt an option if there is another that you know a priori to be better.
Thus, we have the substantial components of Joyce’s argument: Credal Veritism, Joycean Inaccuracy, and Naive Dominance. From these, we can derive Probabilism via the following mathematical theorem Joyce (1998: 597–600):
Theorem 4 (Joyce’s Main Theorem) Suppose \(\mathcal{F}\) is an algebra and \(\mathfrak{I} : \mathcal{C_F} \times \mathcal{W_F} \rightarrow [0, \infty]\) is a Joycean inaccuracy measure for the credence functions on \(\mathcal{F}\). Now suppose that \(c^*\) is a credence function in \(\mathcal{C_F}\) that violates Probabilism. Then there is a credence function \(c'\) in \(\mathcal{C_F}\) such that \(\mathfrak{I}(c', w) < \mathfrak{I}(c^*, w)\) for all \(w\) in \(\mathcal{W_F}\). (In this situation, we say that \(c'\) accuracy dominates \(c^*\) relative to \(\mathfrak{I}\).)
Figure 1 illustrates this result in the particular very simple case in which \(\mathcal{F}\) contains just a proposition, Heads, and its negation, Tails, and inaccuracy is measured using the Brier score.
Thus, we have the following argument:
Joyce’s accuracy argument for Probabilism
- \((1)\)Credal Veritism + Joycean Inaccuracy
- \((2)\)Naive Dominance
- \((3)\)Theorem 4
- Therefore,
- \((4)\)Probabilism
![[a graph of two vertical lines and two horizontal lines forming a square but lines extend beyond the intersections. The left vertical line is labelled 'Tails' and the lower horizontal line labelled 'Heads'. The upper left corner is labelled \(v_{w_1}\) , the lower right corner is labelled \(v_{w_2}\)] and a diagonal linke connects the two. Two arcs, one stretches from the lower left vertical line to the upper right horizontal line and the other from the upper right vertical line to the lower left horizontal line. The two arcs intersect twice. The upper right intersection is labelled \(c*\) and a point on the diagonal line in the middle of the intersection space is labelled \(c'\).](fig1.png)
Figure 1: In this figure, we plot the various possible credence functions defined on a proposition Heads and its negation Tails in the unit square. Thus, we plot the credence in Heads along the horizontal axis and the credence in Tails up the vertical axis. We also plot the vindicated credence functions \(v_{w_1}\) and \(v_{w_2}\) for the two worlds \(w_1\) (at which Tails is true and Heads is false) and \(w_2\) (at which Heads is true and Tails is false). The diagonal line between them contains all and only the credence functions on these two propositions that are probability functions and thus satisfy Probabilism. \(c^*\) (which assigns 0.7 to Heads and 0.6 to Tails) violates Probabilism. The lower right-hand arc contains all the credence functions that are exactly as inaccurate as \(c\) at world \(w_2\), where that inaccuracy is measured using the Brier score. To see this, note that the Brier score of \(c^*\) at \(w_2\) is the square of the Euclidean distance of the point \(c^*\) from the point \(v_{w_2}\). Thus, the credence functions that have exactly the same Brier score as \(c^*\) at \(w_2\) are those that lie equally far from \(v_{w_2}\). For the same reason, the upper left-hand arc contains all the credence functions that are exactly as inaccuracy as \(c\) at world \(w_1\). Every credence function that lies between the two arcs is more accurate than \(c^*\) at both worlds. These are the ones whose squared Euclidean distance from \(v_{w_2}\) is less than the squared Euclidean distance of \(c^*\) from \(v_{w_2}\), and similarly for \(v_{w_1}\). It assigns 0.55 to Heads and 0.45 to Tails. \(c'\) is such a credence function. \(c'\) also satisfies Probabilism.
5.2 The source(s) of epistemic disutility
Let us start by considering the first of the two components that comprise Joyce’s account of epistemic disutility for credences, namely, Credal Veritism. This says that the sole fundamental source of epistemic disutility for a credence is its gradational inaccuracy. That is, any other vice that the credence has must derive from this vice (Goldman 2002: 52).
First, let’s note why it is important to make this assumption. Would it not be sufficient to say merely that one of the sources of disutility for a credence is its inaccuracy, and then to point out that any credence function that isn’t a probability function is accuracy dominated? If it could always be guaranteed that, for any non-probabilistic credence function, none of its accuracy dominators has any epistemic vice to a greater degree than does the credence function it dominates, then this would be sufficient. But, if it were possible that every accuracy dominator is guaranteed to be better along the dimension of inaccuracy but worse along some other dimension of epistemic disutility, then being accuracy dominated would not rule out a credence function as irrational. Thus, if the accuracy dominance argument for Probabilism is to work, we must claim, with Credal Veritism, that inaccuracy is the only source of epistemic disutility for credences.
How are we to establish this? How can we be sure there aren’t other sources of disutility. For instance, perhaps it is a virtue of a credence function if the credences it assigns cohere with one another in a particular way, and a vice if they do not. This is a coherentist claim of the sort endorsed for full beliefs, rather than credences, by the likes of BonJour (1985) and Harman (1973). Or perhaps it is a virtue of a credence in a particular proposition if it matches the degree of support given to that proposition by the agent’s current total evidence. This claim is dubbed evidential proportionalism by Goldman (2002: 55–7). Recent proponents might include Williamson (2000) and White (2009). Another possibility: perhaps the verisimilitude or truthlikeness of your credences is a source of their epistemic utility over and above their gradational accuracy (see entry on truthlikeness). Graham Oddie (2019) argues in favour of this. Each of these seem plausible. How is the credal veritist to answer the objection that there are sources of epistemic disutility, such as these three, that go beyond gradational inaccuracy? Of course, it is notoriously difficult to prove a negative existential claim, such as the credal veritist claim that there are no other epistemic vices beyond inaccuracy. But here is a natural strategy: for each proposed candidate epistemic vice besides accuracy, the credal veritist should provide an account of how its badness derives from the badness of inaccuracy.
In the case of the coherentist described above, who proposes that it is a vice to have credences that fail to cohere in a particular way, there is a very natural instance of this strategy. The coherence that we demand of credences is precisely that they relate to one another in the way that Probabilism demands, so that, for instance, no disjunction is assigned lower credence than is assigned to either of the disjuncts, no proposition is assigned very high credence at the same time that its negation is also assigned very high credence, and so on. If that is correct, then of course Joyce’s accuracy argument for Probabilism detailed above provides an argument that this vice derives its badness from the badness of inaccuracy: after all, if a credence function lacks the coherence that the coherentist considers virtuous, they will be accuracy dominated.
What of the evidential proportionalist? Here it is a little more difficult. There are principles that the evidential proportionalist will take to govern evidential support that go beyond merely Probabilism, which is a relatively weak and undemanding principle. So it is not sufficient to point to the accuracy argument for that principle in the way we did in response to the coherentist. However, here is an attempt at an answer. It comes from collecting together a series of accuracy arguments for other principles of rationality that we take to govern our credences. For instance, Greaves & Wallace (2006) and Briggs & Pettigrew (2018) give an accuracy argument for the principle of conditionalization, which says that, if an agent is rational, her credence function at a later time will be obtained from her credence function at an earlier time by conditionalizing on the total evidence she obtains between those two times; Easwaran (2013) and Huttegger (2013) extend the argument, and Schoenfield (2016) and Carr (2019) clarify the norm that it establishes. Moreover, Pettigrew (2013a) gives an accuracy argument for the Principal Principle, which says that, if an agent is rational, her credences in propositions concerning the objective chances will relate to propositions to which those chances attach in a particular way. Pettigrew (2014b) and Konek (2016) give rather different accuracy-based arguments for the Principle of Indifference, which says how a rational agent with no evidence will distribute their credences. Moss (2011), Lam (2013), and Levinstein (2015) describe principles that rational agents will obey in the presence of peer disagreement and provide accuracy-based arguments in their favour. And finally Horowitz (2014) uses accuracy-based arguments to evaluate various species of permissivism. The point is that, piece by piece, the principles that are taken to govern the degree of support provided to a proposition by a body of evidence are being shown to follow from accuracy considerations alone. This, it seems, constitutes a response to the concerns of the evidential proportionalist.
Christopher Meacham (2018) objects to this response in two ways: first, he argues that the different decision-theoretic norms that are used in the justifications of the various credal norms listed above might be incompatible with one another; and, second, he worries that some of the decision-theoretic norms that are used in those justifications are not themselves purely alethic and therefore fail to provide purely veritistic justifications of the norms in question.
Both the response to the coherentist and the response to the evidential proportionalist leave the accuracy argument for Probabilism in a strange position. The argument for, or defence of, one component of its first premise, namely, Credal Veritism appeals to an argument of which it is a premise! In fact, this isn’t problematic. The credal veritist and her opponent might agree that the argument at least establishes a conditional: if credal veritism is true, then probabilism is true. You need not accept credal veritism to accept that conditional. And it is that conditional to which the credal veritist appeals in defending her position against the coherentist and the evidential proportionalist. Having successfully defended credal veritism in this way, she can then appeal to its truth to derive Probabilism.
Before we consider how to measure inaccuracy in the next section, let’s consider the claim that verisimilitude or truthlikeness is a further source of epistemic utility. It is most easily introduced by an example. Suppose I am interested in how many stars there are on the flag of Suriname. I have credences in three propositions: 1 (which says there’s one star), 2 (which says there are two), and 3 (which says three). In fact, there is one star on the flag. That is, 1 is true at the actual world, while 2 and 3 are false. Now consider two different credence functions on these three propositions:
- \(c(1) = 0\), \(c(2) = 0.5\), \(c(3) = 0.5\)
- \(c'(1) = 0\), \(c'(2) = 1\), \(c'(3) = 0\)
That is, \(c\) and \(c'\) both assign credence 0 to the true proposition, 1; they are certain that there are either 2 or 3 stars on the flag, but while \(c\) spreads its credence equally over these two false options, \(c'\) is certain of the first. According to Oddie (2019), \(c'\) has greater truthlikeness than \(c\) at the actual world because it assigns a higher credence to a proposition that, while false, is more truthlike, namely, 2, and it assigns a lower credence to a proposition that is, while also false, less truthlike, namely, 3. On this basis, he argues that any measure of epistemic disutility must judge \(c\) to be worse than \(c'\). However, he notes, nearly all measures of gradational accuracy that are used in accuracy dominance arguments for Probabilism will not judge in that way: they will judge \(c'\) worse than \(c\). And indeed those that do so judge will fail to respect truthlikeness in other ways. Jeffrey Dunn (2018) and Miriam Schoenfield (2019) respond to Oddie’s arguments.
5.3 Measures of inaccuracy
5.3.1 Joyce on Convexity
So much, then, for the first component of the first premise of the accuracy argument for Probabilism, namely, Credal Veritism. In this section, we turn to the second component, namely, Joycean Inaccuracy. Let’s focus on a particular condition that Joyce places on measures of inaccuracy, namely, Strong Convexity (Joyce calls it Weak Convexity, but we change the name in this presentation because, as Patrick Maher (2002) points out, it is considerably stronger than Joyce imagines.)
Strong Convexity Suppose \(\mathfrak{I}\) is a legitimate inaccuracy measure. Then if \(c \neq c'\) and \(\mathfrak{I}(c, w) = \mathfrak{I}(c', w)\), then \[\mathfrak{I}\left(\frac{1}{2}c + \frac{1}{2}c', w\right) < \mathfrak{I}(c, w) = \mathfrak{I}(c', w)\] (Given two credence functions, \(c\) and \(c'\), we define a third credence function \(\frac{1}{2}c + \frac{1}{2} c'\) as follows: the credence that \(\frac{1}{2}c + \frac{1}{2}c'\) assigns to a proposition is the straight average of the credences that \(c\) and \(c'\) assign to it. Thus, \((\frac{1}{2}c + \frac{1}{2}c')(X) = \frac{1}{2}c(X) + \frac{1}{2}c'(X).\) We call this the equal mixture of \(c\) and \(c'\).)
This says that, for any two distinct credence functions that are equally inaccurate at a given world, the third credence function obtained by “splitting the difference” between them and taking an equal mixture of the two is less inaccurate than either of them. Here is Joyce’s justification of this condition:
[Strong] Convexity is motivated by the intuition that extremism in the pursuit of accuracy is no virtue. It says that if a certain change in a person’s degrees of belief does not improve accuracy then a more radical change in the same direction and of the same magnitude should not improve accuracy either. Indeed, this is just what the principle says. (Joyce 1998: 596)
Joyce’s point is this: Suppose we have three credence functions, \(c\), \(m\), and \(c'\). And suppose that, to move from \(m\) to \(c'\) is just to move in the same direction and by the same amount as to move from \(c\) to \(m\), which is exactly what will be true if \(m\) is the equal mixture of \(c\) and \(c'\). Now suppose that \(m\) is at least as inaccurate as \(c\)—that is, the change from \(c\) to \(m\) does not “improve accuracy”. Then, Joyce claims, \(c'\) must be at least as inaccurate as \(m\)—that is, the change from \(m\) to \(c'\) also does not “improve accuracy”.
Objection: The justification given doesn’t justify Strong Convexity. The problem with this justification is that it establishes a weaker principle than Strong Convexity. This was first pointed out by Patrick Maher (2002), who noted that Joyce’s justification in fact motivates the following weaker principle:
Weak Convexity Suppose \(\mathfrak{I}\) is a legitimate inaccuracy measure. Then if \(c \neq c'\) and \(\mathfrak{I}(c, w) = \mathfrak{I}(c', w)\), then \[\mathfrak{I}\left(\frac{1}{2}c + \frac{1}{2}c', w\right) \leq \mathfrak{I}(c, w) = \mathfrak{I}(c', w)\]
That is, Joyce’s motivation rules out situations in which inaccuracy increases from \(c\) to \(m\) and then decreases from \(m\) to \(c'\). And this is what Weak Convexity also rules out. But Strong Convexity furthermore rules out situations in which inaccuracy remains the same from \(c\) to \(m\) and then from \(m\) to \(c'\). And Joyce has given no reason to think that such changes are problematic. What’s more, as Maher proves, the stronger convexity condition is crucial for Joyce’s proof. With only the weaker condition, the theorem is false.
5.3.2 Local and global inaccuracy
In this section, we consider alternative sets of conditions on inaccuracy measures that are presented by Leitgeb & Pettigrew (2010a). These propose that we replace the claim Joycean Inaccuracy in Joyce’s accuracy argument for Probabilism with an alternative claim that says that the legitimate inaccuracy measures are (amongst) those that satisfy Leitgeb and Pettigrew’s alternative conditions. Unlike Joyce’s conditions, these are sufficient to narrow the field of legitimate inaccuracy measures to just a single one, namely, the Brier score \(\mathfrak{B}\) that we met in section 5.1 above. Let us say that Brier Inaccuracy is the claim that the Brier score is the only legitimate measure of inaccuracy. And note that, if we replace Joycean Inaccuracy with Brier Inaccuracy in Joyce’s argument for Probabilism, we retain our argument for that epistemic norm:
Brier accuracy-based argument for Probabilism: I
- \((1)\)Credal Veritism + Brier Inaccuracy
- \((2)\)Naive Dominance
- \((3)\)Theorem 4
- Therefore,
- \((4)\)Probabilism
So far, in this section, we have been concerned only with what we might call global measures of inaccuracy—that is, measures of the inaccuracy of entire credence functions. Leitgeb and Pettigrew are certainly interested in those. But they are also interested in what we might call local measures of inaccuracy—that is, measures of the inaccuracy of individual credences. Indeed, they are interested in how these two sorts of inaccuracy measure interact. They lay down constraints on each of the inaccuracy measures individually, and then they lay down constraints on how they combine. The guiding idea in each case is that any feature of the inaccuracy of credences that is determined from the point of view of local inaccuracy measures—such as their total inaccuracy, or the urgency with which an agent with inaccurate credences should change them—should match that same feature when it is determined from the point of view of global inaccuracy measures. If this doesn’t happen, then the agent will face a rational dilemma when choosing which of the two ways she should use to determine that feature. Here, we shall focus only on one of the most powerful of Leitgeb and Pettigrew’s conditions, which also turns out to be the most problematic. Here it is:
Global Normality and Dominance If \(\mathfrak{I}\) is a legitimate global inaccuracy measure, there is a strictly increasing \(f:[0, \infty) \rightarrow [0, \infty)\) such \[\mathfrak{I}(c, w) = f(||v_w - c||_2).\] where, for any two credence functions \(c\), \(c'\) defined on \(\mathcal{F}\), \[||c - c'||_2 := \sqrt{\sum_{X \in \mathcal{F}} |c(X) - c'(X)|^2}\] and we call \(||c - c'||_2\) the Euclidean distance between \(c\) and \(c'\); and, recall, \(v_w\) is the omniscient credence function at \(w\), so that \(v_w(X) = 1\) if \(X\) is true at \(w\) and \(v_w(X) = 0\) if \(X\) is false at \(w\).
Thus, Global Normality and Dominance says that the inaccuracy of a credence function at a world should supervene in a certain way upon the Euclidean distance between that credence function and the omniscient credence function at that world. Indeed, it should be a strictly increasing function of that distance between them.
Objection 1: There is no motivation for the appeal to Euclidean distance. Leitgeb and Pettigrew show that the only inaccuracy measure that satisfies Global Normality and Dominance, together with their other conditions on inaccuracy measures, is the Brier score, which we defined above. That is, imposing these conditions entails Brier Inaccuracy. The problem with this characterization, however, is that it depends crucially on the appeal to the Euclidean distance made in Global Normality and Dominance, and no reason is given for appealing to the Euclidean distance measure in particular, rather than some other measure of distance between credence functions. Suppose we replace that condition with one that says that a legitimate global inaccuracy measure must be a strictly increasing function of the so-called Manhattan or city block distance measure, where the distance between two credence functions measured in this way is defined as follows: \[||c - c'||_1 := \sum_{X \in \mathcal{F}} |c(X) - c'(X)|\] That is, the Manhattan distance between two credence functions is obtained by summing the differences between the credences they each assign to the various propositions on which they are defined. Together with the other constraints that Leitgeb and Pettigrew place on inaccuracy measures, this alternative constraint entails that the only legitimate inaccuracy measure is the so-called absolute value score, which is defined as follows: \[\mathfrak{A}(c, w) := \sum_{X \in \mathcal{F}} |v_w(X) - c(X)|\]
Now, it turns out that the absolute value score cannot ground an accuracy argument for Probabilism. In fact, there are situations in which non-probabilistic credence functions accuracy dominate probabilistic credence functions when inaccuracy is measured using the absolute value score. Let \(\mathcal{F} = \{X_1, X_2, X_3\}\), where \(X_1\), \(X_2\), and \(X_3\) are mutually exclusive and exhaustive propositions. And consider the following two credence functions: \(c(X_i) = \frac{1}{3}\) for each \(i = 1, 2, 3\); \(c'(X_i) = 0\) for each \(i = 1, 2, 3\). The former, \(c\), is probabilistic; the latter, \(c'\), is not. But, if we measure inaccuracy using the absolute score, the inaccuracy of \(c\) at each of the three possible worlds is \(\frac{4}{3}\), whereas the inaccuracy of \(c'\) at each of the three possible worlds is \(1\). The upshot of this observation is that it is crucial, if our accuracy argument for Probabilism is to succeed, to rule out the absolute value score. The problem with the Leitgeb and Pettigrew characterization is that it rules out this measure essentially by fiat. It rules it out by demanding that the inaccuracy of a credence function at a world supervenes on the Euclidean distance between the credence function and the omniscient credence function at that world. But it gives no reason for favouring this measure of distance over another, such as Manhattan distance.
Objection 2: Using the Brier score to measure inaccuracy has unintuitive consequences. A further objection to Leitgeb and Pettigrew’s characterization of inaccuracy measures is given by Levinstein (2012). In the sequel to the paper in which they give this characterization, Leitgeb and Pettigrew use it to argue in favour of an updating rule for credences that applies in the same situations as so-called Jeffrey Conditionalization (or Probability Kinematics) but offers different advice (Jeffrey 1965; Leitgeb & Pettigrew 2010b). Levinstein objects to the use of the Brier score to measure inaccuracy on the grounds that this alternative updating rule gives deeply unintuitive results.
5.3.3 Calibration and accuracy
The final characterization of inaccuracy measures that we consider here is due to Pettigrew (2016). Again, we won’t enumerate all of the conditions here. Instead, we’ll describe the most contentious and mathematically powerful of the conditions—the one that in some sense does the main mathematical “heavylifting” when it comes to showing what putative inaccuracy measures these conditions permit.
So far in this entry, we have presented calibration accounts of epistemic utility and accuracy accounts as separate and incompatible. The condition on inaccuracy measures that Pettigrew proposes and that we consider in this section denies that. Rather, it claims that closeness to calibration in fact plays a role in determining the accuracy of a credence function; the difference between this approach and the calibration arguments of section 4 is that Pettigrew does not think that closeness to calibration is the whole story. Let \(\mathfrak{D}\) be a putative measure of the distance between two credence functions. That is, \(\mathfrak{D} : \mathcal{C_F} \times \mathcal{C_F} \rightarrow [0, \infty]\), and we’ll assume that \(\mathfrak{D}(c, c') = 0\) iff \(c = c'\). Now first we use this measure of distance to define a measure of the distance that a credence function lies from being perfectly calibrated at a world. Then, following a point already made above in our treatment of calibration arguments for Probabilism, we note that this, on its own, cannot define a measure of inaccuracy because it lacks a crucial feature that we demand of any such measure: it is not truth-directed. However, we then note how to supplement the measure of distance from calibration in order to give an inaccuracy measure that does have the crucial feature. And we claim that all inaccuracy measures are produced by supplementing a measure of distance from calibration in this way.
As in section 4.1, we let \(\sim\) be an equivalence relation on the set \(\mathcal{F}\) of propositions to which our agent assigns opinions. It is the relation of relevant similarity between two propositions. In section 4.1, we said that we would impose conditions \(C(\sim)\) on this equivalence relation, but we said no more to identify those conditions. In this section, we in fact define this equivalence relation. We take it to be relative to a credence function \(c\), so we write it \(\sim_c\), and we define it as follows: \(A \sim_c B\) iff \(c(A) = c(B)\). That is, two propositions are relevantly similar for our agent with credence function \(c\) if \(c\) assigns them the same credence. Thus, given a possible world \(w\), we say that a credence function \(c\) is perfectly calibrated at \(w\) if, for each \(A\) in \(\mathcal{F}\), \[c(A) = \mathrm{Freq}(\mathcal{F}, A, \sim_c, w)\]
Next, given a credence function \(c\) and a world \(w\), the perfectly calibrated counterpart of \(c\) at \(w\) is a credence function also defined on \(\mathcal{F}\) that is defined as follows: for each \(A\) in \(\mathcal{F}\) \[c^w(A) = \mathrm{Freq}(\mathcal{F}, A, \sim_c, w)\] That is, the perfectly calibrated counterpart of \(c\) at \(w\) assigns to each proposition \(A\) the frequency of truths at \(w\) amongst all propositions to which \(c\) assigns the same credence that it assigns to \(A\). Note that \(c^w\) is perfectly calibrated at \(w\). And if \(c\) is perfectly calibrated at \(w\), then \(c^w = c\). Now, we define the distance that a credence function \(c\) lies from calibration at a world \(w\) to be the distance, \(\mathfrak{D}(c^w, c)\), from \(c^w\) to \(c\). Now, as we saw in Objection 1 from section 4.3 above, this measure does not itself give a measure of epistemic disutility. The problem is that an agent can move closer to calibration at a world \(w\) while moving uniformly further from the omniscient credence function at that world: that is, the measure of epistemic disutility provided by the distance of the credence function from its perfectly calibrated counterpart is not truth-directed. Thus, if an agent’s distance from her perfectly calibrated counterpart is to contribute to a measure of her inaccuracy, it must be supplemented by something that ensures that the resulting measure avoids this consequence. The idea that Pettigrew proposes is this: the inaccuracy of \(c\) at \(w\) is given by the distance of \(c\) from the omniscient credence function \(v_w\) at \(w\); and that is given by adding the distance of \(c\) from its perfectly calibrated counterpart \(c^w\) to the distance of \(c^w\) from \(v_w\). Thus, while moving to a credence function that is closer to its perfectly calibrated counterpart may move you further from the omniscient credence function, this can only be because the perfectly calibrated counterpart of your new credence function is further from the omniscient credence function than the perfectly calibrated counterpart of your current credence function. If their perfectly calibrated counterparts are the same, or if they are different but equally close to the omniscient credence function, then moving closer to them will move you closer to the omniscient credence function. Thus, Pettigrew imposes the following constraint:
Decomposition Suppose \(\mathfrak{I}\) is a legitimate inaccuracy measure and \(\mathfrak{D}\) is a distance measure such that \(\mathfrak{I}(c, w) = \mathfrak{D}(v_w, c)\). Then \[\mathfrak{I}(c, w) = \mathfrak{D}(v_w, c) = \mathfrak{D}(c^w, c) + \mathfrak{D}(v_w, c^w)\]
Together with the other conditions that Pettigrew imposes, Decomposition narrows down the class of legitimate inaccuracy measures to a single one, namely, the Brier score. That is, imposing these conditions entails Brier Inaccuracy.
Objection 1: Appeal to summation is arbitrary. One concern about Decomposition is this: it is crucial for the proof that the Brier score and only the Brier score satisfies all of Pettigrew’s conditions that in Decomposition we combine the distance between \(c\) and \(c^w\) with the distance between \(c^w\) and \(v_w\) by summing them together. But we could have combined those quantities in other ways: we might have multiplied them together, for instance; or, we might have summed them and then taken a strictly increasing function of that sum. It might be mathematically natural simply to add them together: but that doesn’t privilege that means of combining them for philosophical purposes. However, if we combine them in any of these alternative ways, Pettigrew’s conditions will no longer hold of the Brier score.
Objection 2: Proximity to calibration is not a good. Another concern is that, while proximity to being perfectly calibrated seems epistemically good in the standard cases that are used to motivate calibrationist accounts, it seems less compelling in other cases. For instance, suppose you have opinions only about three propositions: First coin toss lands heads, Second coin toss lands heads, Third coin toss lands heads. And suppose you assign to each of them the same credence, \(\frac{1}{3}\). Then, in that situation, it seems plausible that you are doing better if one out of the three tosses comes up heads. Now suppose that I have opinions only about three propositions: Djibouti is the capital of Ghana, Serena Williams is a badminton player, Doris Lessing wrote The Golden Notebook. And suppose I assign to each of them the same credence, \(\frac{1}{3}\). Then, in that situation, do we really retain the intuition that I do best if one out of the three turns out true?
5.3.4 Levinstein on importance
In many of the accounts of inaccuracy measures that we’ve considered, such as those that propose the Brier score, the inaccuracy of a whole credence function is given by the sum of the inaccuracies of the individual credences it comprises; and the inaccuracy of every individual credence is measured using the same local inaccuracy measure. You might object, however, that not all credences should be contribute equally to the overall inaccuracy of a credence function of which they are a part. The accuracy of my credence that general relativity is correct is surely more important and contributes more to the overall epistemic utility of my credence function than the accuracy of my credence that there are 1,239,382 blades of grass on my front lawn. Now, we might accommodate this intuition by taking the inaccuracy of the whole credence function to be not the straight sum of the local inaccuracies of the credences it assigns, but rather the weighted sum, where a credence gets greater weight the more important the proposition to which it is assigned is. Now, as Predd, et al. (2009) show, if we define global inaccuracy like this, and if the importance of a proposition is the same at every world, then an analogue of Theorem 4 still holds and we can still establish Probabilism. However, Ben Levinstein (2018) shows that, if the importance of a proposition changes from world to world, the analogue of Theorem 4 will fail and with it the accuracy dominance argument for Probabilism. And, he argues, the importance of a proposition does often change from world to world. In worlds where I have a brother, propositions that concern his well-being have great importance to me, and the accuracy of my credences in them should contribute greatly to the epistemic utility of my whole credence function; in worlds where I am an only child, on the other hand, the importance of these propositions is much diminished, as is the contribution of the accuracy of my credences in them to my total epistemic utility.
5.4 Dominance principles
So far, we have considered the two components of the first premise of Joyce’s accuracy argument for Probabilism: Credal Veritism and Joycean Inaccuracy. We have left the former intact, but we have seen concerns with the latter, and we have considered arguments for a stronger claim, Brier Inaccuracy, though these also face difficulties. In this section, we move from the account of epistemic disutility on which the argument is based to the decision-theoretic principle to which we appeal in order to derive Probabilism from this account. Let’s recall the version of the principle to which Joyce appeals in his original paper:
Naive Dominance A rational agent will not adopt an option when there is another option that has lower disutility at all worlds.
That is: Suppose \(\mathcal{O}\) is a set of options, \(\mathcal{W}\) is the set of possible worlds, and \(\mathfrak{U}\) is a disutility function. Then, if \(o^*\) is an option, and if there is another option \(o'\) such that \(\mathfrak{U}(o', w) < \mathfrak{U}(o^*, w)\) for all worlds \(w\) in \(\mathcal{W}\), then \(o^*\) is irrational.
Thus, according to Joyce, a credence function is irrational if it is accuracy dominated.
In this section, we’ll consider four objections that have been raised against Naive Dominance in the context of the accuracy argument for Probabilism.
5.4.1 The Bronfman objection
The first objection to the application of Naive Dominance in the context of the accuracy argument for Probabilism was first stated in an unpublished manuscript by Aaron Bronfman entitled “A Gap in Joyce’s Proof of Probabilism”; it has been discussed by Hájek (2008) and Pettigrew (2010, 2013b). The starting point for the objection is the observation that Credal Veritism and Joycean Inaccuracy do not together narrow down the class of legitimate measures of epistemic disutility to a single function; they characterize a family of such measures. But, for all that Theorem 4 (Joyce’s Main Theorem) tells us, it may well be that, for a given non-probabilistic credence function \(c^*\), different measures in this family of legitimate inaccuracy measures give different sets of credence functions that accuracy dominate \(c^*\). Thus, an agent with a non-probabilistic credence function \(c^*\) might be faced with a range of credence functions, each of which accuracy dominates \(c^*\) relative to a different legitimate inaccuracy measure. Moreover, it may be that any credence function that accuracy dominates \(c^*\) relative to Joycean inaccuracy measure \(\mathfrak{I}\) does not accuracy dominate \(c^*\) relative to the alternative Joycean measure \(\mathfrak{I}'\); indeed, it may be that any credence function that dominates \(c^*\) relative to \(\mathfrak{I}\) risks very high inaccuracy at some world relative to \(\mathfrak{I}'\), and vice versa. In this situation, it is plausible that the agent is rationally permitted to stick with her non-probabilistic credence function \(c^*\).
There are two replies to this objection. According to the first, the objection relies on a false meta-normative claim; according to the second, it misunderstands the purpose of Joyce’s conditions.
Reply 1: No requirement to give advice. The meta-normative claim on which the objection seems to rely is the following: For a norm to hold, there must be specific advice available to those who violate that norm concerning how to improve their behaviour. Bronfman’s objection begins with the observation that, for any specific advice that one might give to a non-probabilistic agent concerning which credence function she should adopt in favour of her own, there will be inaccuracy measures that satisfy Joyce’s conditions, but don’t sanction this advice; indeed, there will be inaccuracy measures relative to which that advice is very bad. Thus, Joyce’s accuracy argument violates the meta-normative constraint. But, the reply submits, the meta-normative claim is false: for a norm to hold, it is sufficient that there is a serious defect suffered by those who violate the norm that is not shared by those who satisfy the norm; it is not also required that there should be advice on which specific action an agent should perform to improve her behaviour. And Joyce’s argument satisfies this sufficient condition. An agent ought to satisfy Probabilism because non-probabilistic credence functions suffer from a serious epistemic defect (namely, being accuracy dominated) that does not beset probabilistic ones. And this fact is “supertrue”, so to speak: that is, it is true on any precisification of the notion of accuracy that obeys Joyce’s conditions on an inaccuracy measure.
Reply 2: Each agent uses a single inaccuracy measure. The second reply to this objection does not take issue with the meta-normative claim mentioned above; indeed, on the understanding of the accuracy argument for Probabilism that it proposes, the argument satisfies the necessary condition imposed by that claim. That is, according to this reply, the accuracy argument, properly understood, does in fact provide specific advice to non-probabilistic agents. The idea is this: There are (at least) three ways to understand the purpose of Joyce’s conditions on inaccuracy measures. First, we might think that the notion of inaccuracy is vague; and we might say that any inaccuracy measure that satisfies the conditions is a legitimate precisification of it. This is a supervaluationist approach. On this approach, there is no specific advice available to non-probabilistic agents that is sanctioned by all precisifications. Second, we might think that the notion of inaccuracy is precise, but that we have only limited knowledge about it, and that the sum total of our knowledge is embodied in the conditions. This is an epistemicist approach. On this approach, there is specific advice, but it is not available to us. Third, we might think that there is no objectively correct inaccuracy measure; rather, any inaccuracy measure that satisfies the conditions is rationally permissible. But nonetheless, any particular agent has exactly one such measure. This is a subjectivist approach. On this understanding, there is specific advice for any non-probabilistic agent. Any such agent uses an inaccuracy measure that satisfies Joyce’s conditions. And this gives, for any non-probabilistic credence function, a probabilistic credence function that strongly dominates it. So the specific advice is this: adopt one of the probabilistic credence functions that strongly dominates your non-probabilistic credence function relative to your favoured measure of inaccuracy. This gives us Probabilism and does so without violating the meta-normative claim on which Bronfman’s objection relies.
However, this response isn’t without its own problems. For instance, it assumes that each agent values inaccuracy in a sufficiently specific way that they narrow down the class of inaccuracy measures to a single measure that they can then use to obtain this advice. But, at least for those who think that Joycean Inaccuracy is the strongest condition we can place on the inaccuracy measures, this seems too strong. How can we assume that each rational agent will have a unique inaccuracy measure in mind when we don’t think that there are conditions that demand that we narrow down the class of legitimate inaccuracy measures this far?
5.4.2 Undominated dominance
The second objection to Naive Dominance comes from Pettigrew (2014a). Here, Pettigrew observes that there are decisions in which Naive Dominance does not seem to hold because the irrationality of being dominated depends on the status of the dominating options in some way. Here’s Pettigrew’s central example:
Name Your Fortune\(^*\) You have a choice: play a game with God or don’t. If you don’t, you receive 2 utiles for sure. If you do, you then pick an integer. If you pick \(k\), God will then do one of two things: (i) give you \(2^{k-1}\) utiles; or (ii) give you \(2 - \frac{1}{2^{k-1}}\) utiles. (Pettigrew 2014a: 587)
In this example, the only option that isn’t dominated is the option in which you do not play the game with God. If you choose that option, you get 2 utiles for sure. If, on the other hand, you choose to play the game and pick integer \(k\), then choosing integer \(k+1\) will be guaranteed to get you more utility: either \(2^{k+1}\) utiles compared with \(2^k\) or \(2 - \frac{1}{2^k}\) utiles compared with \(2 - \frac{1}{2^{k-1}}\). However, the option in which you get 2 utiles for sure seems a lousy option given the other possibilities available. One way to see this is as follows: Take a probability distribution over the two possibilities (i) and (ii) between which God will choose if you choose to play; then, providing it doesn’t assign all probability to God choosing (i), there will be some option you can take if you play the game that has greater expected utility than the option of not playing the game. If Naive Dominance is correct, however, not playing the game is the only rational option. This seems to tell against Naive Dominance.
The moral that Pettigrew draws from this example is the following. Not all dominated options are irrational. Whether or not a dominated option is irrational depends on the status of the options that dominate it. If all of the options that dominate a given option are themselves dominated, then being dominated does not rule out the given option as irrational. Thus, in Name Your Fortune\(^*\), none of the options are ruled irrational because they are dominated; after all, all of the dominated options are only dominated by other options that are also themselves dominated. Thus, Pettigrew instead suggests a decision-theoretic principle to replace Naive Dominance. To state it, we must distinguish between two notions of dominance: a strong notion and a weak notion. Suppose \(o^*\) and \(o'\) are options. We say that \(o^*\) strongly dominates \(o'\) if \(o^*\) has greater utility than \(o'\) at all worlds. We say that \(o^*\) weakly dominates \(o'\) if \(o^*\) has at least as great utility as \(o'\) at all worlds and greater utility at some world.
Undominated Dominance A rational agent will not adopt an option that is strongly dominated by an option that is not itself even weakly dominated.
Now, it turns out that, if we accept Brier Inaccuracy, we can still derive Probabilism using only Undominated Dominance. This is a consequence of the following theorem:
Theorem 5 (de Finetti) Suppose that \(c^*\) is a credence function in \(\mathcal{C_F}\) that violates Probabilism. Then
- there is a credence function \(c'\) in \(\mathcal{C_F}\) such that \(\mathfrak{B}(c', w) < \mathfrak{B}(c^*, w)\) for all \(w\) in \(\mathcal{W_F}\), and
- there is no credence function \(c\) such that \(\mathfrak{B}(c, w) \leq \mathfrak{B}(c', w)\) for all \(w\) in \(\mathcal{W_F}\) and \(\mathfrak{B}(c, w) < \mathfrak{B}(c', w)\) for some \(w\) in \(\mathcal{W_F}\).
Thus, we have the following argument:
Brier-based accuracy argument for Probabilism: II
- (1)Credal Veritism + Brier Inaccuracy
- (2)Undominated Dominance
- (3)Theorem 5
- Therefore,
- (4)Probabilism
5.4.3 Evidence and Accuracy
The next objection to Naive Dominance is similar to the objection raised in the previous section. In the previous section, the moral we drew from Name Your Fortune\(^*\) is that a dominated option is only ruled irrational in virtue of being dominated if at least one of the options that dominate it is not itself dominated. But there may be other features that a credence function might have besides itself being dominated such that being dominated by that credence function does not entail irrationality. Easwaran & Fitelson (2012) suggest the following feature. Suppose that your credence function is non-probabilistic, but it matches the evidence that you have: that is, the credence it assigns to a proposition matches the extent to which your evidence supports that proposition. And suppose that none of the credence functions that accuracy dominate your credence function have that feature. Then, we might say, the fact that your credence function is accuracy dominated does not rule it irrational. After all, it is dominated only by credence functions that violate the constraints that your evidence imposes on your credences. Thus, Easwaran and Fitelson suggest the following decision-theoretic principle, which applies only when the options in question are credence functions:
Evidential Dominance A rational agent will not adopt a credence function that is strongly dominated by an alternative credence function that is not itself even weakly dominated and which matches the agent’s evidence if the dominated credence function does.
Easwaran and Fitelson then object that there are situations in which Evidential Dominance does not entail Probabilism. For instance, suppose that a trick coin is about to be tossed. Your evidence tells you that the chance of it landing heads is 0.7. Your credence that it will lands heads is 0.7 and your credence that it will land tails is 0.6. Then you might think that your credences match your evidence, because you have evidence only about it landing heads and your credence that it will land heads equals the known chance that it will land heads. However, it turns out that all of the credence functions that accuracy dominate your credence function (when accuracy is measured by the Brier score) fail to match this evidence: that is, they assign credence other than 0.7 to Heads. Thus, Evidential Dominance does not entail that your credence function is irrational. Figure 2 illustrates this result. Pettigrew (2014a) responds to this objection on behalf of the accuracy argument for Probabilism.
![[The same as figure 1 except there is a vertical dashed line going through the point labelled \(c*\) . (figure 1 description repeated: a graph of two vertical lines and two horizontal lines forming a square but lines extend beyond the intersections. The left vertical line is labelled 'Tails' and the lower horizontal line labelled 'Heads'. The upper left corner is labelled \(v_{w_1}\), the lower right corner is labelled \(v_{w_2}\)] and a diagonal line connects the two. Two arcs, one stretches from the lower left vertical line to the upper right horizontal line and the other from the upper right vertical line to the lower left horizontal line. The two arcs intersect twice. The upper right intersection is labelled \(c*\) and a point on the diagonal line in the middle of the intersection space is labelled \(c'\).]](fig2.png)
Figure 2: In this figure, as in Figure 1, we plot the various possible credence functions defined on a proposition Heads and its negation Tails in the unit square. The diagonal line contains all and only the probability functions. Let \(c^*\) be your credence function: that is, it assigns 0.7 to Heads and 0.6 to Tails. So it violates Probabilism. The credence functions that lie between the two arcs are all and only the credence functions that accuracy dominate \(c^*\). The credence functions on the dashed line are all and only the credence functions that match your evidence that the chance of Heads is 0.7. Notice that the dashed line does not overlap with the set of credence functions that accuracy dominate yours at any point. This is the crucial fact on which Easwaran and Fitelson’s objection rests.
5.4.4 Dominance and Act-State Dependence
The final objection to Naive Dominance comes from Hilary Greaves (2013) and Michael Caie (2013), who point out that, in practical decision theory, only a restricted version of that principle is accepted (see also Jenkins 2007; Berker 2013a,b; Carr 2017). To see why such a restriction is needed, consider the following case:
Driving Test My driving test is in a week’s time. I can choose now whether or not I will practise for it. Other things being equal, I prefer not to practise. But I also want to pass the test, and I know that I won’t pass if I don’t practise, and I will pass if I do. Here is my decision table:
| Pass | Fail | |
| Practise | 10 | 2 |
| Don’t Practise | 15 | 7 |
According to Naive Dominance, it is irrational to practise. After all, whether or not I pass or fail, I obtain higher utility if I don’t practise, so not practising strongly dominates practising. But this is clearly the wrong result. The reason is that I should not compare practising at the world at which I pass with not practising at that world, and practising at the world at which I fail with not practising at that world. For if I practise, I will pass; and if I don’t, I will fail. Moreover, I know all this. So I should compare practising at the world at which I pass with not practising at the world at which I fail. And then my utility is higher if I practise.
The moral of this example is that Naive Dominance should be restricted so that it applies only in situations in which the options between which the agent is choosing will not influence the way the world is if they are adopted. Such situations are sometimes called situations of act-state independence. In situations in which the acts (options) influence the states (of the world), Naive Dominance does not apply. To see how this affects the accuracy argument for Probabilism, consider the following example, which borrows from Caie’s and Greaves’ examples:
Thwarted Accuracy Suppose I can read your mind. You have opinions only about two propositions, \(A\) and \(\neg A\). And suppose that I have control over the truth of \(A\) and \(\neg A\). I decide to do the following. First, define the non-probabilistic credence function \(c^\dag(A) = 0.99\) and \(c^\dag(\neg A) = 0.005\). Then:
- If your credence function is \(c^\dag\), I will make \(A\) true (and thereby make your credence function very accurate);
- If your credence function is not \(c^\dag\) and your credence in \(A\) is greater than 0.5, I will make \(A\) false (and thereby make your credence function rather inaccurate);
- If your credence function is not \(c^\dag\) and your credence in \(A\) is at most 0.5, I will make \(A\) true (and thereby make your credence function rather inaccurate).
In this case, since the credence function \(c^\dag\) is not a probability function, it is accuracy dominated by Joyce’s theorem and thus it is ruled out as irrational by Naive Dominance, just as the option of practising is ruled out as irrational in Driving Test. However, this is a situation in which adopting an option influences the way the world is in such a way that it affects the utility of the option, just as choosing whether or not to practise does in Driving Test. If I were to have credence function \(c^\dag\), I would be more accurate than I would be were I to have any other credence function. Thus, it seems that, just as we said that practising is in fact the only option that shouldn’t be ruled irrational in Driving Test, so now we must say that credence function \(c^\dag\) is the only option that shouldn’t be ruled irrational in Thwarted Accuracy. But of course, it then follows that Probabilism is false, for there are situations such as this one in which it is irrational to do anything other than have a non-probabilistic credence function.
There are three responses available here: the first is to bite the bullet, accept the restriction to Naive Dominance, and therefore accept a restriction on the cases in which Probabilism holds; the second is to argue that the practical case and the epistemic case are different, with different decision-theoretic principles applying to each; the third, of course, is to abandon the accuracy argument for Probabilism. Joyce (2018) and Pettigrew (2018a) argue for the first response. They advocate different decision-theoretic principles to replace Naive Dominance in the epistemic case: Joyce advocates standard causal decision theory together with a Ratifiability condition (Jeffrey 1983); Pettigrew omits the ratifiability condition. But they both agree that these principles will agree with Naive Dominance in cases of act-state independence; and they agree with the verdict that \(c^\dag\) is the only credence function that isn’t ruled out as irrational in Thwarted Accuracy. Konek & Levinstein (2019) argue for the second response, claiming that, since doxastic states and actions have different directions of fit, different decision-theoretic principles will govern them. They hold that Naive Dominance (or, perhaps, Undominated Dominance) is the correct principle when the options are credence functions, even though it is not the correct principle when the options are actions. Caie (2013) and Berker (2013b), on the other hand, argue for the third option.
5.5 Epistemic expansions
In section 5.4.2, we introduced Undominated Dominance and we stated Theorem 5, which says that every non-probabilistic credence function \(c^*\) defined on \(\mathcal{F}\) is accuracy dominated by a credence function \(c'\) defined on \(\mathcal{F}\) that is itself not accuracy dominated by a credence function \(c\) defined on \(\mathcal{F}\). But you might think that this is still not sufficient to establish Probabilism. After all, while \(c'\) is not itself dominated by a credence function defined on \(\mathcal{F}\), it might be accuracy dominated by a credence function \(c^\dag\) defined on some other set of propositions \(\mathcal{F}^\dag\). For instance, take the non-probabilistic credence function \(c^*\) defined on \(\mathcal{F} = \{X, \neg X\}\), where \(c^*(X) = 0.6 = c^*(\neg X)\). It is Brier dominated by \(c'(X) = 0.5 = c'(\neg X)\), since \(c^*\) has Brier score \(|1-0.6|^2 + |0-0.6|^2 = 0.52\) at both worlds in \(\mathcal{W_F}\) while \(c'\) has \(|1-0.5|^2 + |0-0.5|^2 = 0.5\) at both worlds. But \(c'\) is Brier dominated by \(c^\dag\) defined on \(\mathcal{F}^\dag = \{X\}\), where \(c^\dag(X) = 0.5\), since this has Brier score \(|1-0.5|^2 = |0-0.5|^2 = 0.25\) at both worlds. A natural reaction to this is to define the epistemic disutility function to be the average Brier score rather than the total Brier score:
\[\mathfrak{B}'(c, w) := \frac{1}{|\mathcal{F}|}\sum_{X \in \mathcal{F}} |v_w(X) - c(w)|^2\]Now, relative to \(\mathfrak{B}'\), \(c^*\) is indeed accuracy dominated by \(c'\) and \(c'\) is not accuracy dominated by \(c^\dag\). But \(c'\) is accuracy dominated by \(c^+\) defined on \(\mathcal{F}^+ = \{\top\}\), where \(c^+(\top) = 1\), since the average Brier score of \(c^+\) is \(\frac{1}{1}|1-1|^2 = 0\) at all worlds, while the average Brier score of \(c'\) is \(\frac{1}{2}(|1-0.5|^2 + |0-0.5|^2) = 0.25\) at all worlds. Jennifer Carr (2015) initiated the investigation into how epistemic utility arguments for Probabilism might work when we start to compare credence functions defined on different sets of propositions. She notes the analogy with population axiology in ethics (see entry on the repugnant conclusion). Pettigrew (2018b) takes this analogy further, proving an impossibility result analogous to those prevalent in that part of ethics.
6. Epistemic disutility arguments
So far, we have considered calibration arguments and accuracy arguments for Probabilism. In each of these cases, we identify a particular feature of a credence function—the proximity of its credences to being calibrated, or their proximity to the omniscience credences—we claim that it is the source of all epistemic utility, and we attempt to characterize the mathematical functions that legitimately measure the extent to which the credence function has that feature. In this section, we consider an argument due to Joyce (2009) that attempts to characterize epistemic disutility functions directly.
Joyce’s central condition is Coherent Admissibility, which says that a measure of epistemic disutility should never render a probabilistic credence function weakly dominated. More precisely:
Coherent Admissibility Suppose \(\mathcal{F}\) is a set of propositions and \(\mathfrak{D}: \mathcal{C_F} \times \mathcal{W_F} \rightarrow [0, \infty]\) is a measure of epistemic disutility. Then, if \(c^*\) is a probabilistic credence function, then \(c^*\) is not weakly dominated relative to \(\mathfrak{D}\). That is, for any probabilistic credence function \(c^*\), there is no credence function \(c'\) such that
- \(\mathfrak{D}(c', w) \leq \mathfrak{D}(c^*, w)\) for all \(w\); and
- \(\mathfrak{D}(c', w) < \mathfrak{D}(c^*, w)\) for some \(w\).
We then have two results concerning coherent admissible epistemic disutility functions. On the first, we restrict attention to the case in which \(\mathcal{F}\) is a partition, and we prove that, together with Undominated Dominance, we can establish Probabilism; on the second, we focus on the case in which \(\mathcal{F}\) is an algebra, and we prove that, together with Naive Dominance, we can establish Probabilism.
Theorem 5 (Joyce 2009) Suppose \(\mathcal{F}\) is a set of propositions and \(\mathfrak{D}\) is a Joycean epistemic disutility function for the credence functions in \(\mathcal{C_F}\).
- Suppose \(\mathcal{F}\) is an algebra. Then, if \(c^*\) is a
credence function in \(\mathcal{C_F}\) that violates
Probabilism, then
- there is a credence function \(c'\) in \(\mathcal{C_F}\) such that \(\mathfrak{D}(c', w) < \mathfrak{D}(c^*, w)\) for all \(w\) in \(\mathcal{W_F}\).
- Suppose \(\mathcal{F}\) is a partition. Then, if \(c^*\) is a
credence function in \(\mathcal{C_F}\) that violates
Probabilism, then
- there is a credence function \(c'\) in \(\mathcal{C_F}\) such that \(\mathfrak{D}(c', w) < \mathfrak{D}(c^*, w)\) for all \(w\) in \(\mathcal{W_F}\), and
- there is no credence function \(c\) such that \(\mathfrak{D}(c, w) \leq \mathfrak{D}(c', w)\) for all \(w\) in \(\mathcal{W_F}\) and \(\mathfrak{D}(c, w) < \mathfrak{D}(c', w)\) for some \(w\) in \(\mathcal{W_F}\).
Let’s say that Joycean Disutility is the claim that all legitimate measures of epistemic disutility satisfy Coherent Admissibility along with the other new conditions that Joyce imposes. Then we have the following argument:
Joycean epistemic disutility argument for Probabilism
- \((1)\)Joycean Disutility
- \((2)\)Undominated or Naive Dominance
- \((3)\)Theorem 5
- Therefore,
- \((4)\)Probabilism
Joyce argues for Coherent Admissibility as follows.
- \((1)\)For each probabilistic credence function \(c\), there is a possible world at which \(c\) is the objective chance function.
- \((2)\)If an agent learns with certainty that \(c\) is the objective chance function, and nothing more, then the unique rational response to her evidence is to set her credence function to \(c\). (This is close to David Lewis’ Principal Principle (Lewis 1980).)
- \((3)\)Thus, by (1) and (2): for each probabilistic credence function \(c\), there is an evidential situation in which an agent might find herself such that \(c\) is the unique rational response to that evidential situation.
- \((4)\)Thus, by (3): Let \(c^*\) be a probabilistic credence function. Then there is an evidential situation in which \(c^*\) is the unique rational response.
- \((5)\)If \(c'\) weakly dominates \(c^*\) relative to a legitimate measure of epistemic disutility, and \(c^*\) is rationally permitted, then \(c'\) is also rationally permitted.
- \((6)\)Thus, by (4) and (5): if \(c^*\) is weakly dominated, there is no evidential situation in which \(c^*\) the unique rational response.
- Therefore,
- \((7)\)\(c^*\) is not weakly dominated relative to any legitimate measure of epistemic disutility.
Let’s consider two objections to this argument.
Objection 1: Not all probabilistic credence functions could be chance functions. The first objection denies (1). It’s due to Alan Hájek (2008). As Hájek notes, if a credence function \(c\) is defined on propositions about the chances themselves, it’s not obvious that any chance function will be defined on that proposition. If that’s right \(c\) is not a possible chance function. And his argument might be extended. We can assign a credence function on propositions concerning ethical matters, or mathematical matters, or aesthetic matters, or facts about the current time or the agent’s current location. But it is not clear that such a credence function could possibly be the chance function of any world, since it seems natural to think that chances cannot attach to these sorts of proposition. Pettigrew (2014b: 5.2.1) replies on Joyce’s behalf.
Objection 2: The argument over-generates. The second objection claims that, in the absence of Probabilism, which is supposed to be the conclusion of the argument for which Coherent Admissibility is a crucial part, this argument overgenerates. Consider, for instance, the following claim:
- (\(2'\))If an agent learns with certainty that \(c\) is the credence function that constitutes the unique rational response to her evidence at that time, and nothing more, then the unique rational response is to set her credence function to \(c\).
Now, suppose \(c^\dag\) is a non-probabilistic credence function and apply the version of Joyce’s argument that results from replacing (2) with (2’). That is, we assume that it is possible that the agent learn with certainty that \(c^\dag\) is the unique rational response to her evidence, even if in fact it is not. We might assume, for instance, that a mischievous God whispers in the agent’s ear that this is the case. Then we must conclude that \(c^\dag\) is not weakly dominated relative to any legitimate measure of epistemic disutility. But now we have that no credence function is weakly dominated, whether it is probabilistic or not. And, combined with Joyce’s other considerations, this is impossible. If no probabilistic credence functions are weakly dominated relative to an epistemic disutility function, then all of the non-probabilistic credence functions are: that’s the lesson of Theorem 5 above. Of course, the natural response to this objection is to note that (2’) only holds when \(c\) is a probabilistic credence function. But such a restriction is unmotivated until we have established Probabilism.
6.1 Mayo-Wilson and Wheeler on numerical representations of epistemic utility
We have considered a number of different characterizations of the legitimate ways of measuring (in)accuracy and epistemic (dis)utility. Each has assumed that the measures of these quantities are numerically representable; that is, each assumes it makes sense to use real numbers to measure these quantities. Conor Mayo-Wilson and Greg Wheeler call this assumption into question (Mayo-Wilson & Wheeler, ms.). They argue that, in order to represent a quantity numerically, you need to prove a representation theorem for it in measurement theory. And, if you wish to use that quantity as a measure of utility, or as a component of a measure of utility, you need to prove a representation theorem not only for the quantity itself, but for its use in expected utility calculations. They note that this was the purpose of the representation theorems of von Neumann & Morgenstern as well as Savage and Jeffrey (see entry on normative theories of rational choice: expected utility). And they argue that the methods that these authors use are not available to the proponent of epistemic utility arguments.
7. Related issues
That completes our survey of the existing literature on the epistemic utility arguments for Probabilism. We have considered three families of argument: calibration arguments, accuracy arguments, and epistemic disutility arguments. In this final section, we briefly consider ways in which the argument strategy employed here (and described in section 2) might be generalised.
7.1 Infinite probability spaces
We have assumed throughout that the set of propositions on which an agent’s credence function is defined is finite. What happens when we lift this restriction? The first problem is that we need to say how to measure the inaccuracy of a credence function defined over an infinite set of propositions. Then, having done that, we need to say which such credence functions are accuracy dominated relative to these measures, and which aren’t.
Sean Walsh has described an extension of the Brier score to the case in which the set of propositions to which we assign credences is countably infinite; and he has shown that non-probabilistic credence functions on such sets are accuracy dominated relative to that inaccuracy measure, while probabilistic ones aren’t. (For a description of Walsh's unpublished work, see Kelley 2019). Mikayla Kelley (2019) has then gone considerably further and generalized Walsh’s results significantly by describing a wide range of possible inaccuracy measures and characterizing the undominated credence functions defined on sets of propositions of different varieties. One interesting consequence is that an accuracy dominance argument for the norm of Countable Additivity does not seem to be forthcoming.
7.2 Other principles of rationality for credences
We have focussed here on the synchronic coherence principle of Probabilism. But there are many other principles that are thought to govern rational credence. It is natural to ask whether we can give similar arguments for those. As we saw above in section 5.2, a number of epistemic norms have been explored in this framework, but of course there are many more still to consider.
7.3 Other doxastic states
In this entry, we have considered agents represented as having precise credence functions. But there are, of course, many other models of doxastic states that are considered in current epistemology. As mentioned at the outset, we might represent an agent by the set of propositions that they believe (their full beliefs); or we might represent them using a set of precise credence functions (their imprecise credences); or a comparative confidence ordering; or a precise primitive conditional probability function. And, when modelled in this way, there are principles of rationality that apply to these agents. Are there accuracy arguments in their favour?
In the case of full beliefs, it is reasonably straightforward to define the measures of accuracy: a belief in a proposition receives some positive epistemic utility \(R\) when the proposition is true and some negative epistemic utility \(-W\) when it is false; and if you suspend judgment on a proposition, you receive epistemic utility 0 whether it is true or false. Kenny Easwaran (2015) and Kevin Dorst (2017) explore the consequences of this account and show that it naturally gives rise to what is known as the Lockean account of the relationship between credences and full beliefs. Relative to a probability function \(c\), you maximise your expected epistemic utility by believing a proposition \(A\) iff \(c(A) > \frac{W}{R+W}\).
In the case of imprecise credences, it is much less straightforward to define the measures of accuracy. Indeed, there are a number of powerful results that seem to show that there can be no measures that satisfy some basic plausible conditions (Seidenfeld, Schervish, & Kadane 2012, Schoenfield 2015, Mayo-Wilson & Wheeler 2016). To see how these work, note that one of the central motivations for representing an agent’s credences using imprecise credences is that there are often situations in which our evidence seems to demand that our credences are not captured by a single precise credence function. When our evidence is complex, mixed, and ambiguous, we might well think only an imprecise credal state is an appropriate response. However, as these various results show, if your accuracy measure satisfies certain plausible conditions, then for any imprecise credal state, there is a precise one that is at least as accurate as the imprecise one at all worlds. But if that’s the case, Veritism says that it would be just as good to have the precise state as the imprecise one. But that goes against the requirements of our evidence. Jason Konek (2019, section 3) offers a response to these impossibility results on behalf of the epistemic utility theorist who wishes to use imprecise credences to represent agents.
7.4 Non-classical logic
In all of the arguments we’ve surveyed above, we have assumed that classical logic governs the propositions to which our agent assigns credences. This secures Probabilism, which demands, among other things, that an agent assign maximal credence to every classical tautology. But what happens if we drop this assumption? What if, instead, the propositions are governed by a three-valued logic, such as strong Kleene logic or the Logic of Paradox (see entry on many-valued logic)? In a series of papers, Robbie Williams has built on mathematical results by Jeff Paris and Jean-Yves Jaffray to understand what norms of credence the accuracy arguments establish in this case (Williams 2012a,b, 2018, Paris 2001, Jaffray 1989). I’ll give a single example here to illustrate. Strong Kleene logic has three truth values: true, false, and neither. Our first question is this: what is the omniscient credence in a proposition that is neither true nor false? Williams argues that it should be zero. And then he shows that, if we measure the inaccuracy of a credence function at a world as its distance from the omniscient credence function at that world in the usual way, then the credence functions that are not accuracy dominated are precisely those that satisfy the norm of Generalized Probabilism:
Generalized Probabilism Suppose \(\models\) is the logical consequence relation of the correct logic. A rational agent’s credence function \(c\) at a given time is a generalized probability function for that logic. That is:
- If \(\bot \models\), then \(c(\bot) = 0\).
- If \(\models \top\), then \(c(\top) = 1\).
- If \(A \models B\), then \(c(A)\leq c(B)\).
- \(c(A \vee B) = c(A) + c(B) - c(A \wedge B)\).
Note that, if \(\models\) is classical, then Generalized Probabilism is equivalent to Probabilism.
Bibliography
- Ahlstrom-Vij, K. & J. Dunn (eds.), 2018, Epistemic Consequentialism, Oxford: Oxford University Press.
- Berker, S., 2013a, “Epistemic Teleology and the Separateness of Propositions”, Philosophical Review, 122(3): 337–393.
- –––, 2013b, “The Rejection of Epistemic Consequentialism”, Philosophical Issues (Supp. Noûs), 23(1): 363–387.
- Briggs, R. A. & R. Pettigrew, forthcoming, “An Accuracy-Dominance Argument for Conditionalization”, Noûs. doi:10.1111/nous.12258
- BonJour, L., 1985, The Structure of Empirical Knowledge, Cambridge, MA: Harvard University Press.
- Caie, M., 2013, “Rational Probabilistic Incoherence”, Philosophical Review, 122(4): 527–575.
- Carr, J., 2015, “Epistemic Expansions”, Res Philosophica, 92(2): 217–236.
- –––, 2017, “Epistemic Utility Theory and the Aim of Belief”, Philosophy and Phenomenological Research, 95(3): 511–534.
- –––, 2019, “A Modesty Proposal”, Synthese. doi:10.1007/s11229-019-02301-x
- de Finetti, B., 1974, Theory of Probability Vol. 1, New York: Wiley.
- Dorst, K., 2017, “Lockeans Maximize Expected Accuracy”, Mind, 128(509): 175–211.
- Dunn, J., 2018, “Accuracy, Verisimilitude, and Scoring Rules”, Australasian Journal of Philosophy, 97(1): 151–166.
- Easwaran, K., 2013, “Expected Accuracy Supports Conditionalization—and Conglomerability and Reflection”, Philosophy of Science, 80(1): 119–142.
- –––, 2016, “Dr Truthlove, Or: How I Learned to Stop Worrying and Love Bayesian Probabilities”, Noûs, 50(4): 816–853
- Easwaran, K. & B. Fitelson, 2012, “An ‘evidentialist’ worry about Joyce’s argument for Probabilism”, Dialectica, 66(3): 425–433.
- –––, 2015, “Accuracy, Coherence, and Evidence”, Oxford Studies in Epistemology, 5, 61–96.
- Fraassen, B.C. van, 1983, “Calibration: Frequency Justification for Personal Probability”, in R.S. Cohen & L. Laudan (eds.), Physics, Philosophy, and Psychoanalysis, Dordrecht: Springer.
- Goldman, A.I., 2002, Pathways to Knowledge: Private and Public, New York: Oxford University Press.
- Greaves, H., 2013, “Epistemic Decision Theory”, Mind, 122(488): 915–952.
- Greaves, H. & D. Wallace, 2006, “Justifying Conditionalization: Conditionalization Maximizes Expected Epistemic Utility”, Mind, 115(459): 607–632.
- Harman, G., 1973, Thought, Princeton, NJ: Princeton University Press.
- Hájek, A., 2008, “Arguments For—Or Against—Probabilism?”, The British Journal for the Philosophy of Science, 59(4): 793–819.
- –––, 2009, “Fifteen Arguments against Hypothetical Frequentism”, Erkenntnis, 70: 211–235.
- Horowitz, S., 2014, “Immoderately rational”, Philosophical Studies, 167: 41–56.
- Huttegger, S.M., 2013, “In Defense of Reflection”, Philosophy of Science, 80(3): 413–433.
- Jaffray, J-Y., 1989, “Coherent bets under partially resolving uncertainty and belief functions”, Theory and Decision, 26: 90–105.
- Jeffrey, R., 1965, The Logic of Decision, New York: McGraw-Hill.
- Jeffrey, R., 1983, The Logic of Decision (2nd). Chicago; London: University of Chicago Press.
- Jenkins, C.S., 2007, “Entitlement and Rationality”, Synthese, 157: 25–45.
- Joyce, J.M., 1998, “A Nonpragmatic Vindication of Probabilism”, Philosophy of Science, 65(4): 575–603.
- –––, 2009, “Accuracy and Coherence: Prospects for an Alethic Epistemology of Partial Belief”, in F. Huber & C. Schmidt-Petri (eds.), Degrees of Belief, Springer.
- –––, 2018, “The True Consequences of Epistemic Consequentialism”, in Ahlstrom-Vij & Dunn 2018.
- Kelley, M., 2019, Accuracy Dominance on Infinite Opinion Sets, MA Thesis, UC Berkeley. [Online version available here]
- Konek, J., 2016, “Probabilistic Knowledge and Cognitive Ability”, Philosophical Review, 125(4): 509–587.
- –––, 2019, “IP Scoring Rules: Foundations and Applications”, Proceedings of Machine Learning Research, 103: 256–264.
- Konek, J. & B.A. Levinstein, 2019, “The Foundations of Epistemic Decision Theory”, Mind, 128(509): 69–107.
- Lam, B., 2013, “Calibrated Probabilities and the Epistemology of Disagreement”, Synthese, 190(6): 1079–1098.
- Lange, M., 1999, “Calibration and the Epistemological Role of Bayesian Conditionalization”, The Journal of Philosophy, 96(6): 294–324.
- Leitgeb, H. & R. Pettigrew, 2010a, “An Objective Justification of Bayesianism I: Measuring Inaccuracy”, Philosophy of Science, 77: 201–235.
- –––, 2010b, “An Objective Justification of Bayesianism II: The Consequences of Minimizing Inaccuracy”, Philosophy of Science, 77: 236–272.
- Levinstein, B.A., 2012, “Leitgeb and Pettigrew on Accuracy and Updating”, Philosophy of Science, 79(3): 413–424.
- –––, 2015, “With All Due Respect: The Macro-Epistemology of Disagreement”, Philosophers’ Imprint, 15(3): 1–20.
- –––, 2018, “An Objection of Varying Importance to Epistemic Utility Theory”, Philosophical Studies. doi:10.1007/s11098-018-1157-9
- Lewis, D., 1980, “A Subjectivist’s Guide to Objective Chance”, in R.C. Jeffrey (ed.), Studies in Inductive Logic and Probability (Vol. II). Berkeley: University of California Press.
- Maher, P., 1993, Betting on Theories, Cambridge: Cambridge University Press.
- –––, 2002, “Joyce’s Argument for Probabilism”, Philosophy of Science, 69(1): 73–81.
- Mayo-Wilson, C. & G. Wheeler, 2016, “Scoring Imprecise Credences: A Mildly Immodest Proposal”, Philosophy and Phenomenological Research, 92(1): 55–78.
- –––, ms., “Epistemic Decision Theory’s Reckoning”. Unpublished manuscript. [Online version available here]
- Meacham, C. J. G., 2018, “Can All-Accuracy Accounts Justify Evidential Norms”, in Ahlstrom-Vij & Dunn 2018.
- Moss, S., 2011, “Scoring Rules and Epistemic Compromise”, Mind, 120(480): 1053–1069.
- Oddie, G., 2019, “What Accuracy Could Not Be”, The British Journal for the Philosophy of Science, 70(2): 551–580.
- Paris, J. B., 2001, “A Note on the Dutch Book Method”, Proceedings of the Second International Symposium on Imprecise Probabilities and their Applications Ithaca, NY: Shaker.
- Pettigrew, R., 2010, “Modelling uncertainty”, Grazer Philosophische Studien, 80.
- –––, 2013a, “A New Epistemic Utility Argument for the Principal Principle”, Episteme, 10(1): 19–35.
- –––, 2013b, “Epistemic Utility and Norms for Credence”, Philosophy Compass, 8(10): 897–908.
- –––, 2014a, “Accuracy and Evidence”, Dialectica.
- –––, 2014b, “Accuracy, Risk, and the Principle of Indifference”, Philosophy and Phenomenological Research.
- –––, 2016, Accuracy and the Laws of Credence, Oxford: Oxford University Press.
- –––, 2018a, “Making Things Right: the true consequences of decision theory in epistemology”, in Ahlstrom-Vij & Dunn 2018.
- –––, 2018b, “The Population Ethics of Belief: In Search of an Epistemic Theory X”, Noûs, 52(2): 336–372.
- Predd, J., et al., 2009, “Probabilistic Coherence and Proper Scoring Rules”, IEEE Transactions on Information Theory 55(10): 4786–4792.
- Rosenkrantz, R.D., 1981, Foundations and Applications of Inductive Probability, Atascadero, CA: Ridgeview Press.
- Schoenfield, M., 2016, “Conditionalization does not (in general) Maximize Expected Accuracy”, Mind, 126(504): 1155–1187
- –––, 2017, “The Accuracy and Rationality of Imprecise Credences”, Noûs, 51(4): 667–685.
- –––, 2019, “Accuracy and Verisimilitude: The Good, The Bad, and The Ugly”, The British Journal for the Philosophy of Science. doi:10.1093/bjps/axz032
- Seidenfeld, T., 1985, “Calibration, Coherence, and Scoring Rules”, Philosophy of Science, 52(2): 274–294.
- Seidenfeld, T., M.J. Schervish, & J.B. Kadane, 2012, “Forecasting with imprecise probabilities”, International Journal of Approximate Reasoning, 53: 1248–1261.
- Shimony, A., 1988, “An Adamite Derivation of the Calculus of Probability”, in J. Fetzer (ed.), 1988, Probability and Causality: Essays in Honor of Wesley C. Salmon, Dordrecht: Reidel.
- Walsh, S., ms., “Probabilism in Infinite Dimensions”. Unpublished manuscript.
- White, R., 2009, “Evidential Symmetry and Mushy Credence”, Oxford Studies in Epistemology, 3: 161–186.
- Williams, J. R. G., 2012a, “Gradational accuracy and nonclassical semantics”, Review of Symbolic Logic, 5(4):513–537.
- –––, 2012b, “Generalized Probabilism: Dutch Books and accuracy domination”, Journal of Philosophical Logic, 41(5):811–840.
- –––, 2018, “Rational Illogicality”, Australasian Journal of Philosophy, 96(1): 127–141.
- Williamson, T., 2000, Knowledge and its Limits, Oxford: Oxford University Press.
Academic Tools
How to cite this entry. Preview the PDF version of this entry at the Friends of the SEP Society. Look up this entry topic at the Internet Philosophy Ontology Project (InPhO). Enhanced bibliography for this entry at PhilPapers, with links to its database.
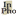

Other Internet Resources
- Pettigrew, Richard, The webpage for Pettigrew’s Accuracy and the Laws of Credence. This includes video tutorials that work through some of the central results in accuracy-first epistemology.
- Weisberg, Jonathan, A series of blogposts that walk slowly through the technical side of accuracy-first epistemology.
