

Biological Information
During the last sixty years, the concept of information has acquired a strikingly prominent role in many parts of biology. This enthusiasm extends far beyond domains where the concept might seem to have an obvious application, such as the biological study of perception, cognition, and language, and now reaches into the most basic parts of biological theory. Descriptions of how genes play their causal role in metabolic processes and development are routinely given in terms of “transcription,” “translation,” and “editing.” The most general term used for the processes by which genes exert their effects is “gene expression.” Many biologists think of the developmental processes by which organisms progress from egg to adult in terms of the execution of a “developmental program.” Other biologists have argued for a pivotal role for information in evolution rather than development: John Maynard Smith and Eors Szathmary (for example) suggest that major transitions in evolution depend on expansions in the amount and accuracy with which information is transmitted across the generations. And some have argued that we can only understand the evolutionary role of genes by recognizing an informational “domain” that exists alongside the domain of matter and energy.
Both philosophers and biologists have contributed to an ongoing foundational discussion of the status of this mode of description in biology. It is generally agreed that the sense of information isolated by Claude Shannon and used in mathematical information theory is legitimate, useful, and relevant in many parts of biology. In this sense, anything is a source of information if it has a range of possible states, and one variable carries information about another to the extent that their states are physically correlated. But it is also agreed that many uses of informational language in biology seem to make use of a richer and more problematic concept than Shannon's. Some have drawn on the teleosemantic tradition in philosophy of mind to make sense of this richer concept.
A minority tradition has argued that the enthusiasm for information in biology has been a serious theoretical wrong turn, and that it fosters naive genetic determinism, other distortions of our understanding of the roles of interacting causes, or an implicitly dualist ontology. Others take this critique seriously but try to distinguish legitimate appeals to information from misleading or erroneous ones. In recent years, the peculiarities of biological appeals to information have also been used by critics of evolutionary theory within the “intelligent design” movement.
- 1. Introduction
- 2. Shannon's concept of information
- 3. Teleosemantic and other richer concepts
- 4. The genetic code
- 5. Signaling systems
- 6. Rejections of informational concepts in biology
- 7. Genetic programs
- 8. Information and evolution
- Bibliography
- Other Internet Resources
- Related Entries
1. Introduction
Biology is concerned with living organisms — with their structure, activities, distribution in space and time, and participation in evolutionary and developmental histories. Many of these organisms engage in activities that seem best understood in terms of information processing or representation. These include perception, cognition, signaling, and language use. But over the second half of the 20th century, biology came to apply informational concepts (and their relatives) far more broadly than this. For many biologists, the most basic processes characteristic of living organisms should now be understood in terms of the expression of information, the execution of programs, and the interpretation of codes. So although contemporary mainstream biology is an overtly materialist field, it has come to employ concepts that philosophers will recognize as intentional or semantic ones, concepts with a long history of causing foundational problems for materialists (and, to some extent, for everyone else).
The embrace of informational and other semantic concepts has been especially marked within genetics, but it has also become important in other areas, such as evolutionary theory and developmental biology, particularly where these fields border on genetics. The usage that has generated the most discussion is found in the description of the relations between genes and the various structures and processes that genes play a role in causing. For many biologists, the causal role of genes should be understood in terms of their carrying information about their various products. That information might require the cooperation of various environmental factors before it can be “expressed,” but the same can be said of other kinds of message. Breaking things down further, we can recognize two causal roles for genes, and hence two potential explanatory roles for genetic information, within biology. Genes are crucial to both explaining the development of individual organisms, and to explaining the inheritance of characteristics across generations. Information has been invoked in both explanatory contexts.
Initially it might be thought that these modes of description are anchored in a set of well-established facts about the role of DNA and RNA within the manufacture of protein molecules in cells, a set of facts summarized in the familiar chart representing the “genetic code,” that maps triplets of the DNA bases (C, A, T, G) to individual amino acids, which are the building blocks of protein molecules. And in many ways, this sense of “genetic coding” is one of the best-established and least problematic ways of using informational concepts within biology. But even this mode of description can be challenged (Sarkar 1996). And it is important that informational enthusiasm in biology pre-dates even a rudimentary understanding of these mechanisms (Schrodinger 1944), and now extends far beyond this relatively straightforward case. Current applications of informational concepts in biology include:
- The description of whole-organism phenotypic traits (including complex behavioral traits) as specified or coded for by information contained in the genes,
- The treatment of many causal processes within cells, and perhaps of the whole-organism developmental sequence, in terms of the execution of a program stored in the genes,
- Treating the transmission of genes (and sometimes other inherited structures) as a flow of information from the parental generation to the offspring generation.
- The idea that genes themselves, for the purpose of evolutionary theorizing, should be seen as, in some sense, “made” of information. Information becomes a fundamental ingredient in the biological world.
There is no consensus about the status of these ideas, and the result has been a growing foundational discussion within biology and the philosophy of biology. Some have hailed the employment of informational concepts as a crucial advance (Williams 1992). Others have seen almost every biological application of informational concepts as a serious error, one that distorts our understanding and contributes to lingering genetic determinism (Francis 2003). Most of the possible options between these extreme views have also been defended. Perhaps most commentators within philosophy have seen the project of sorting through the various kinds of informational description that have become current as valuable, distinguishing legitimate ones from illegitimate ones (Sterelny, Smith, and Dickison 1996, Godfrey-Smith 2000, Griffiths 2001). Philosophers have also tried to give a reductive or naturalistic explanation for the legitimate ones. A smaller (and perhaps shrinking) group of commentators have claimed that the whole issue is a storm in a teacup; they do not think that the development of an informational language for describing genes makes much of a difference to anything, as it is loose metaphorical talk that carries no theoretical weight (Kitcher 2001).
This entry proceeds as follows. In the next section we discuss the most unproblematic technical use of information in biology, which draws on Shannon and the mathematical theory of information. Against that background, some of the more contentious uses are both motivated and introduced. “Teleosemantics” is discussed as one possible way of analyzing the richer senses of information that may be relevant in biology (Section 3). We then discuss the status of the “genetic code” in its original sense (Section 4), and discuss signaling systems outside of genetics (Section 5). Ways of rejecting all or most informational forms of description are discussed (Section 6). The final two sections discuss the idea that biological development in individuals proceeds by the execution of a program (Section 7), and the use of information in understanding the role of inheritance systems in the “major transitions” in evolution (Section 8).
Before moving on, there are two other preliminary points to make. We will not discuss the role of the concepts of information and representation in the parts of biology where they are most obviously relevant; the paper is not concerned with neuroscience, perception, or language-processing. The topic of this paper is the role of information (and its relatives) in parts of biology where its role is less obvious. Secondly, in the early part of this discussion we will not put much emphasis on some of the finer distinctions between the concepts of information, representation, meaning, coding, and so on. As the entry goes on, distinctions between concepts within this family will become more important, but some of the subtler distinctions will be backgrounded initially.
2. Shannon's concept of information
One common way to start organizing the problem is to make a distinction between two senses of “information,” or two kinds of application of informational concepts. One of these is a weak or minimal sense, and the other is stronger and more controversial. In the weaker sense, informational connections between events or variables involve no more than ordinary correlations (or perhaps correlations that are “non-accidental” in some physical sense involving causation or natural laws). A signal carries information about a source, in this sense, if we can predict the state of the source from the signal. This sense of information is associated with Claude Shannon (1948), who showed how the concept of information could be used to quantify facts about contingency and correlation in a useful way, initially for use in communication technology.
For Shannon, anything is a source of information if it has a number of alternative states that might be realized on a particular occasion. And any other variable carries information about the source if its state is correlated with the state of the source. This is a matter of degree; a signal carries more information about a source if its state is a better predictor of the source, less information if it is a worse predictor.
This way of thinking about contingency and correlation has turned out to be useful in many areas outside of the original applications that Shannon had in mind, and genetics is one example. Philosophy has produced a very good foundational discussion of this sense of information, in Dretske (1981). There are puzzles surrounding this concept, especially with respect to the use of physical concepts of probability. But the most important point in the present context is that when a biologist uses this sense of information in a description of gene action or other processes, he or she is just adopting a quantitative framework for describing ordinary correlations or causal connections.
This framework has turned out to be very useful in biology. Often the use is overtly instrumentalist. “Bioinformatics” or “computational biology” makes extensive use of information-theoretic measures, as part of the attempt to use sophisticated computational data analysis tools on biological problems. Some have also argued that abstract patterns in evolutionary processes can be described using informational concepts (Harms 2004). But in all these uses, there is no sense in which biological processes are being explained in terms of the use or manipulation of information. The familiar example of tree rings is helpful here. When a tree lays down rings, it establishes a structure that can be used by us to make inferences about the past. The number and size of the rings carry information, in Shannon's sense, about the history of the tree and its circumstances. Despite the usefulness of the informational description, there is no sense in which we are explaining how the tree does what it does, in informational terms. The only reader or user of the information in the tree rings is the human observer. The tree itself does not exploit the information in its rings to control its growth or flowering. Similarly, we might note ways in which the distribution of different DNA sequences within and between biological populations “carries information about” the historical relationships between those populations, and the histories of the individual populations themselves. It has been argued, for example, that the greater diversity in mitochondrial DNA in African populations, in comparison to other human populations, is an indicator of a comparatively recent human dispersal from an African origin. In making these inferences, informational concepts can be useful tools. But this is just a more complicated version of what is going on in the case of tree rings. The appeal to information has an inferential use that is no way explanatory. A large proportion of the informational descriptions found in biology have this character.
Consequently, philosophers have sometimes set the discussion up by saying that there is one kind of “information” appealed to in biology, the kind originally described by Shannon, that is unproblematic and does not require much philosophical attention. The term “causal” information is also sometimes used to refer to this concept, and it is essentially the same as what Grice (1957) referred to as “natural meaning” in his work in the philosophy of language. Information in this sense exists whenever there is contingency and correlation. So we can say that genes contain information about the proteins they make, and also that genes contain information about the whole-organism phenotype. But when we say that, we are saying no more than what we are saying when we say that there is an informational connection between smoke and fire, or between tree rings and a tree's age. The more contentious question becomes whether or not biology needs another, richer concept of information as well. Information in this richer sense is sometimes called “semantic” or “intentional” information.
Why might we think that biology needs to employ a richer concept? One thought is that genes play a special, instructional role in development, telling the embryo how to grow. It is true that genes carry Shannon-information about phenotypes: the genome of a fertilized egg predicts much of the resulting phenotype. In mammals, for example, chromosome structure predicts the sex of the adult animal. But if an informational relationship between gene and phenotype is supposed to involve a distinctive instruction-like mode of causation, then this cannot be information in Shannon's sense. For environmental factors, not just genes, “carry information” about phenotypes, in Shannon's sense. With respect to Shannon information, there is a “parity” between the roles of environmental and genetic causes (Griffiths and Gray 1994). Moreover, if we are using Shannon's concept, then the informational relationship between genotype and phenotype is symmetrical. For example, once a reader knows that both authors of this article are male, they can predict that we both carry a Y-chromosome. Some talk about information in biology is consistent with these features of Shannon information, but some is not. In particular, it is usually thought that at least some applications of informational language to genes are supposed to ascribe to them a property that is not ascribed to environmental conditions, even when the environment is predictively important.
In addition, a message that carries “semantic information,” it is often thought, has the capacity to mis-represent, as well as accurately represent, what it is about. There is a capacity for error. Shannon information does not have that feature; we cannot say that one variable “carried false information” about another, if we are using the Shannon sense of the term. But biologists do apparently want to use language of that kind when talking about genes. Genes carry a message that is supposed to be expressed, whether or not it actually is expressed.
These are the usual “marks” that are taken in the literature to show that a richer sense of information than Shannon's has been introduced to biology. But it can also be added that a crucial difference between the less and more contentious applications of informational concepts is that, in the richer cases, information use is supposed to help explain how biological systems do what they do — how cells work, how an egg can develop into an adult, how genetic inheritance mechanisms make the evolution of complex phenotypes possible.
At this point, however, it is important to note that there are two ways in which richer notions of information can be introduced. One possibility is to argue that genes and other biological structures literally carry semantic information, and their informational character explains the distinctive role of these structures in biological processes. Another possibility is to treat the appeal to meaning and information as an analogical one. Here the idea is that language, coding systems, computer programs and other paradigmatically information-exploiting systems can serve as useful models for biological systems. If we take this second route, our task then is to identify the similarities between the cases of semantic phenomena used as models and the biological systems we seek to understand, and to show how those similarities are informative. If we think of genes or cells as literally carrying semantic information, our problem changes. Paradigm cases of structures with semantic information — pictures, sentences, programs — are built by the thought and action of intelligent agents. So we need to show how genes and cells — neither intelligent systems themselves nor the products of intelligence — can carry semantic information, and how the information they carry explains their biological role. We need some kind of reductive explanation of semantic information (arguably, we need this to understand cognition, too). One place we might look for such an analysis is naturalistic philosophy of mind.
3. Teleosemantic and other richer concepts
As noted above, several philosophers and biologists have argued that much informational talk about genes uses a richer concept than Shannon's, but this concept can be given a naturalistic analysis. The aim has been to make sense of the idea that genes semantically specify their normal products, in a sense similar to that seen in some paradigm cases of symbolic phenomena.
If genes are seen as “carrying a message” in this sense, the message apparently has a prescriptive or imperative content, as opposed to a descriptive or indicative one. Their “direction of fit” to their effects is such that if the genes and the eventual structure produced (the phenotype) do not match, what we have is a case of unfulfilled instructions rather than inaccurate descriptions.
In making sense of these ideas, the usual way to proceed has been to make use of a rich concept of biological function, in which the function of an entity derives from a history of natural selection. This move is familiar from the philosophy of mind, where similar problems arise in the explanation of the semantic properties of mental states (Millikan 1984). When an entity has been subject to and shaped by a history of natural selection, this can provide the grounding for a kind of purposive or normative description of the causal capacities of that entity. To use the standard example (Wright 1976), the function of a heart is to pump blood, not to make thumping sounds, because it is the former effect that has led to hearts being favored by natural selection. The hope is that a similar “teleofunctional” strategy might help make sense of the semantic properties of genes, and perhaps other biological structures with semantic properties.
The idea of a teleosemantic approach to genetic information was developed in an early form by Sterelny, Smith, and Dickison (1996; see also Maclaurin 1998). The eminent biologist John Maynard Smith took a similar approach, when he tried to make sense of his own enthusiasm for informational concepts in biology (2000; and see also the commentaries that follow Maynard Smith's article). Eva Jablonka (2002) has also defended a version of this idea. Her treatment is more unorthodox, as she seeks to treat environmental signals as having semantic information, along with genes, if they are used by the organism in an appropriate way. The most sophisticated teleosemantic treatment of genes to date is probably that in Shea (2007).
There are several ways in which the details of such an account can be developed (Godfrey-Smith 1999), some focusing on the evolved functions of the genetic machinery as a whole, and others on the natural selection of particular genetic elements. The fact that specific genetic elements (or the genetic system as a whole) have an evolved function is clearly not sufficient for genes to carry semantic information. Legs are for walking, but they do not represent walking. Enzymes are for catalyzing reactions, but they do not instruct this activity. There are things that legs and enzymes are supposed to do, but this does not make them into information-carriers, in a rich beyond-Shannon sense. Why should it do so for genes?
One possible response to this would be to retain a strong appeal to functional concepts, but abandon or downplay the appeal to information. A view with that structure was defended, on independent grounds, by Kaplan and Pigliucci (2001). In contrast, the proposal of Sterelny, Smith and Dickison (1996), supposed that there is an intimate connection between evolutionary function and semantic properties in the case of biological structures that have been selected to play a causal role in developmental processes. The argument is that genes, in virtue of these functional properties, represent the outcomes they are supposed to produce. Sterelny, Smith and Dickison add, however, that any non-genetic factors that have a similar developmental role, and have been selected to play that role, also have semantic properties. So Sterelny, Smith and Dickison want to ascribe very rich semantic properties to genes, but not only to genes. Some non-genetic factors have the same status. In contrast, in his 2000 paper, John Maynard Smith argued that only genes carry semantic information about phenotypes. He suggested that in contrast to other developmental resources, the relationship between adapted gene and phenotypic outcome is arbitrary; the gene-trait relationship is like the word-object relationship. This idea is intriguing but hard to make precise. One problem is that any causal relation can look “arbitrary” if it operates via many intervening links, for there are many possible interventions on those links which would change the product of the causal chain. The problem of arbitrariness is discussed further in Section 4.
Shea (2007) distinguishes between ordinary biological functions, and functions that involve information use. Here he draws on Millikan's teleosemantic theory. For Millikan, any object that has semantic properties plays a role that involves a kind of mediation between two “cooperating devices,” a producer and an consumer device. In the case of an indicative signal or representation, the representation is supposed to affect the activities of the consumer in a way that will only further the performance of the consumer's biological functions if some state of affairs obtains. In the case of an imperative representation, the representation is supposed to affect the activities of the consumer by inducing them to bring some state of affairs about. Shea treats genetic messages as having both indicative and imperative content. Where Shea following Millikan in emphasizing the roles of both producers and consumers, Jablonka (2002) tries to achieve as much as possible with an emphasis on consumer mechanisms alone. It seems clear that the attention to consumer mechanisms is a step forward in this discussion.
The overall picture envisaged by the teleosemantic approach has undeniably appealing structural features. If this program succeeds, we would have a uncontroversial sense of information, via Shannon, that applies to all sorts of physical correlations, and an “overlay” of richer semantic properties in cases where we have the right kind of history of natural selection. Genes and a handful of non-genetic factors would have these properties; most environmental features that have a causal role in biological development would not. There remain many problems of detail, but the appeal of the overall picture provides, at least for some, good reason to persevere with some account along these lines.
4. The genetic code
So far we have mostly discussed the concept of information; there has not been much talk of “coding.” And the ideas discussed so far do not put any emphasis on the distinctive features of the cell-level processes in which genes figure, such as the language-like combinatorial structure of the “genetic code.” Surely these features of genetic mechanisms provide much of the underlying motivation for the introduction of semantic concepts into biology? Many discussions have in effect treated this as an open question. As noted above, the enthusiasm for semantic characterization of biological structures extends back before the genetic code was discovered. (See Kay 2000 for a detailed historical treatment.) But one line of thought in the literature, overlapping with the ideas above, has focused on the special features of genetic mechanisms, and on the idea of “genetic coding” as a contingent feature of these mechanisms.
Both Godfrey-Smith (2000a) and Griffiths (2001) have argued that there is one highly restricted use of a fairly rich semantic language within genetics that is justified. This is the idea that genes “code for” the amino acid sequence of protein molecules, in virtue of the peculiar features of the “transcription and translation” mechanisms found within cells. Genes specify amino acid sequence via a templating process that involves a regular mapping rule between two quite different kinds of molecules (nucleic acid bases and amino acids). This mapping rule is combinatorial, and apparently arbitrary (in a sense that is hard to make precise.
Figure 1 below has the standard genetic code summarized. The three-letter abbreviations such as “Phe” and “Leu” are types of amino acid molecules.
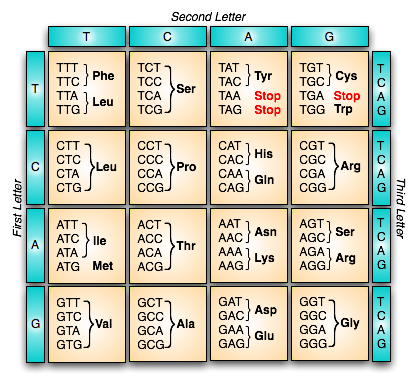
Figure 1. The Standard Genetic Code
This very narrow understanding of the informational properties of genes is basically in accordance with the influential early proposal of Francis Crick (1958). The argument is that these low-level mechanistic features make gene expression into a causal process that has significant analogies to paradigmatic symbolic phenomena.
Some have argued that this analogy becomes questionable once we move from the genetics of simple prokaryotic organisms (bacteria), to those in eukaryotic cells. This has been a theme of Sarkar's work (1996). Mainstream biology tends to regard the complications that arise in the case of eukaryotes as mere details that do not compromise the basic picture we have of how gene expression works. An example is the editing and “splicing” of mRNA transcripts. The initial stage in gene expression is the use of DNA in a template process to construct an intermediate molecule, mRNA or “messenger RNA,” that is then used as a template in the manufacture of a protein. The protein is made by stringing a number of amino acid molecules together. In organisms other than bacteria, the mRNA is often extensively modified (“edited”) prior to its use. This process makes eukaryotic DNA a much less straightforward predictor of the protein's amino acid sequence than it is in bacteria, but it can be argued that this does not much affect the crucial features of gene expression mechanisms that motivate the introduction of a symbolic or semantic mode of description.
So the argument in Godfrey-Smith (2000a) and Griffiths (2001) is that there is one kind of informational or semantic property that genes and only genes have: coding for the amino acid sequences of protein molecules. But this relation “reaches” only as far as the amino acid sequence. It does not vindicate the idea that genes code for whole-organism phenotypes, let alone provide a basis for the wholesale use of informational or semantic language in biology. Genes can have a reliable causal role in the production of a whole-organism phenotype, of course. But if this causal relation is to be described in informational terms, then it is a matter of ordinary Shannon information, which applies to environmental factors as well.
One of the most appealing, but potentially problematic, features of the idea that genes code for amino acid sequences concerns the alleged “arbitrariness” of the genetic code. The notion of arbitrariness figures in other discussions of genetic information as well (Maynard Smith 2000, Stegmann 2004). It is common to say that the standard genetic code has arbitrary features, as many other mappings between DNA bases triplets and amino acids would be biologically possible, if changes are assumed in the machinery by which “translation” of the genetic message is achieved. Francis Crick (1958) suggested that the structure of the genetic code should be seen as a “frozen accident,” one that was initially highly contingent but is now very hard for evolution to change. But the very idea of arbitrariness, and the hypothesis of a frozen accident, have become problematic. Conceptually, it seems that any causal relation can look “arbitrary” if it operates via many intervening links. There is nothing “arbitrary” about the mechanisms by which each molecular binding event occurs. What makes the code seem arbitrary is the fact that the mapping between base triplets and amino acids is mediated by a causal chain with a number of intervening links (especially involving “transfer RNA” molecules, and enzymes that bind amino acids to these intervening molecules). Because we often focus on the “long-distance” connection between DNA and protein, the causal relation appears arbitrary. If we focused on steps in any other biological cascade that are separated by three or four intervening links, the causal relation would look just as “arbitrary.” So the very idea of arbitrariness is elusive. And empirically, the standard genetic code is turning out to have more systematic and non-accidental structure than people had once supposed (Knight, Freeland, and Landweber 1999). The notion of arbitrariness has also been used in discussions of the links between genes and phenotypes in a more general sense. Kirscher and Gerhart (2005) discuss a kind of arbitrariness that derives from the details of protein molecules and their relation to gene regulation. Proteins that regulate gene action tend to have distinct binding sites, which evolution can change independently. This gives rise to a huge range of possible processes of gene regulation. So there is a perennial temptation to appeal to the idea of arbitrariness when discussing the alleged informational nature of some biological causation.
5. Signaling systems
So far we have concentrated on the informational treatment of genes, and other mechanisms that are involved in development and inheritance. But there is also another interesting category of biological processes that lend themselves naturally to an informational treatment. This includes hormonal signaling systems, and other mechanisms by which one part of the body conditions the activities of another by means of an intermediate molecule. Here, there is an obvious and almost undeniable analogy between a biological process and paradigm cases of representation use in everyday life. An example is the way that hormones such as insulin, testosterone, and growth hormone are produced in one part of the body, and travel to other parts where they interact with “receptors” in a way that modifies the activities of various other structures. It is routine to describe hormones as “chemical messages.” Philosophers have not invested a lot of energy in the topic of intra-organismal signals of this kind (though see Rosenberg 1986). But these cases have a very good fit to the schemas used in a number of philosophical treatments of semantic phenomena. These include Millikan's teleosemantic theory (1984), and Skyrms (1996) treatment of signaling systems in evolutionary game theoretic terms.
In Section 2 we noted that it is possible to treat information-using systems as models for biological systems. The use of informational concepts in cell biology might be best understood in this way. The analogy between everyday forms of symbol use and biological interactions might be very partial, whilst still being illuminating. The analogy would work like this. A central aspect of everyday symbol use is the use of such symbols to guide effective action: we can use a map of an underground rail system to make good decisions about where to get off and on. We guide behavior in one domain (traveling around a city) by attending to another: the layout of lines, colors and shapes on a train wall. This pattern is also installed in the picture that Shannon used in his theory of information: we have a source, and a signal whose state can be consulted to learn something about the source. A central feature of this schema is the distinction between some mechanism that reads or consumes the signal, and the signal itself. The very notion of a “receptor,” seen so often in cell biology, suggests this schema. This explains why hormones seem to be such good candidates for a semantic characterization.
The schema also has some application to the phenomena of gene expression, though only at a low level of description. The cell-level machinery of transcription and translation (the ribosomal/tRNA machinery, especially) is, in effect, a reader or consumer of nucleic acid sequence, with the function of creating protein products that will have a variety of uses elsewhere in the cell. But we immediately see that this realization of the causal schematism only applies at the cell level, at the level at which the transcription and translation apparatus shows up as a definite part of the machinery. One of the most extraordinary features of ontogeny is that it proceeds reliably and predictably without any central control of the development of the organism as a whole. There is nothing, for example, that checks whether the left-side limbs are the same size as the right side limbs, intervening to ensure symmetry. There are DNA sequence-readers, but no higher level readers that inspect growing limb-buds in the embryo. So this line of thought supports the idea that genes can be said to code for protein molecules but not for anything further downstream.
6. Rejections of informational concepts in biology
Some biologists and philosophers have argued that the introduction of informational and semantic concepts has had a bad effect on biology, that it fosters various kinds of explanatory illusions and distortions, perhaps along with ontological confusion. Here we will survey some of the more emphatic claims of this kind, but some degree of unease can be detected in many other discussions (see, for example, Griesemer 2005).
The movement known as Developmental Systems Theory (DST) has often opposed the mainstream uses of informational concepts in biology, largely because of the idea that these concepts distort our understanding of the causal processes in which genes are involved (Lehrman 1970, Oyama 1985, Griffiths and Gray 1994, Oyama, Griffiths and Gray 2001). These theorists have two connected objections to the biological use of informational notions. One is the idea that informational models are preformationist. Preformationism, in its original form, in effect reduces development to growth: within the fertilized egg there exists a miniature form of the adult to come. Preformationism does not explain how an organized, differentiated adult develops from a much less organized and more homogeneous egg; it denies the phenomenon. DST's defenders suspect that informational models of development do the same. In supposing, for example, that instructions for a “language organ” are coded in the genome of a new-born baby, you do not explain how linguistic abilities can develop in an organism that lacks them, and you foster the illusion that no such explanation is necessary. (See Francis 2003 for a particularly vigorous version of the idea that the appeal to information leads to pseudo-explanation in biology.)
Second, DST thinks that informational models of genes and gene action make it very tempting to attribute a kind of causal primacy to these factors, even when many other causal factors are essential players in the process in question. Once one factor in a complex system is seen in informational terms, the other factors are naturally treated as mere background, as supports rather than bona fide causal actors. But, the argument goes, in biological systems the causal role of genes is in fact tightly interconnected with the roles of many other factors (often loosely lumped together as “environmental”). Sometimes a gene will have a reliable effect against a wide range of environmental backgrounds; sometimes an environmental factor will have a reliable effect against a wide range of genetic backgrounds. Sometimes both genic and environmental causes are highly context-sensitive in their operation. In this situation, it is highly misleading to treat genes and only genes as carrying “messages” that are expressed in their effects. To say this is almost inevitably to treat environmental factors as secondary players. And even if this “privileging” of genes is not the result, it is the imposition of an unjustified distinction in the kinds of causal roles associated with genetic and non-genetic factors (Godfrey-Smith 2000b).
The key point has recently been re-asserted by Griffiths (2001). He notes that in complex systems, almost all causal factors are context-dependent, and usually it is not hard to remember this. If we think in ordinary causal terms, it is straightforward to note that a genetic cause will only have its normal effects if accompanied by suitable environmental conditions, and an environmental cause will only have its normal effect if accompanied by suitable genetic conditions. (If the sensitivity on either side is high, then talk of “normal” effects itself may be misleading.) But the informational mode of describing genes (and other factors) fosters the appearance of context-independence: “genes are thought to be a special kind of cause. Genes are instructions — they provide information — whilst other causal factors are merely material…. A gay gene is an instruction to be gay even when [because of other factors] the person is straight” (2001, pp. 395-96). So the idea is that the inferential habits and associations that tend to go along with the use of informational or semantic concepts lead us to think of genes as having an additional and subtle form of extra causal specificity. These habits can have an effect even when people are willing to overtly accept context-dependence of (most) causes in complex biological systems. Relatedly, the idea of internal genetic messages may also foster a tendency towards a kind of essentialist thinking; the meaning of the internal message tells us what the “true nature” of the organism is, regardless of whether this nature is actually manifested.
This point about essentialism links to another criticism of informational enthusiasms in biology. Some have argued that the materialist structure of biological theory is seriously compromised by the way informational concepts are used. We see some of this idea in the DST literature (Oyama 1985), but the most emphatic version is in Francis (2003). For Francis, the actual use of information in biological explanations shows that it is not being treated as a special sort of physical property, but as something genuinely “spooky” — as a kind of ultimate explainer and a ground of biological form. Philosophers may say that functionalism and other ideas about levels of explanation in philosophy of science have legitimized this sort of appeal to high-level properties, but this does not affect how the concept is actually used. For Francis, the fact that recent advocates of “intelligent design” creationism have seized on information and its role in evolutionary theory is no accident. These writers have argued that a reflection on the nature of information shows that natural processes could not produce complex evolutionary outcomes at all (Dembski 1997). For Francis and other critics, this shows what happens when informational concepts are allowed to guide our thinking too much; information is a non-material posit masquerading as a high-level physical property (see Pennock 2001 for a survey of debates over intelligent design theory).
These are good reasons to be cautious about the use of informational terminology in thinking about development. But it is also possible to over-estimate the strength of the connection between informational conceptions of development and evolution and the idea that genes play a uniquely important role in development. An ambitious use of informational concepts is not confined to those within mainstream biological thinking. Jablonka and Lamb (2005) are examples of quite unorthodox theorists about inheritance and evolution who base key parts of their work —including an advocacy of “Lamarckian” ideas —around informational concepts. In fact, Jablonka and Lamb hold that one of the useful features of informational descriptions is that they allow us to generalize across different heredity systems, comparing their properties in a common currency. In addition, one of the present authors (Sterelny 2004) has used informational concepts to distinguish between the evolutionary role of genes from that of other inherited factors whilst demonstrating the evolutionary importance of non-genetic inheritance. So in various ways, an informational point of view may facilitate discussion of unorthodox theoretical options, including non-genetic mechanisms of inheritance.
7. Genetic programs
A form of description very common in biology, but less extensively analyzed by philosophers, has it that the genes contain a program, in a sense analogous to that in computer science (Jacob 1982, Moss 1992, Sterelny 2001, Marcus 2004). Here the focus is more on the control of processes by genes, as opposed to the specification of a particular product. This has obvious connections to the topic of information, so we discuss it here.
The “program” concept seems to be applied in biology in an especially broad and unconstrained way, often guided only by very vague analogies with computers and their workings. First, we might isolate a very broad usage, in which talk of programming seems merely aimed at referring to the intricate but orderly and well-coordinated nature of many processes in biological systems. Here, the most that talk of “programs” could be doing is indicating the role of evolutionary design. An example might be talk of “programmed cell death” in neuroscience, which is a process within neural development that could just as accurately be described as “orderly and adaptive cell-death in accordance with evolutionary design.”
Secondly, however, we might isolate a sense in which talk of “programs” in biology is driven by a close analogy between some biological process and the low-level operation of modern computers. One crucial kind of causal process within cells is cascades of up and down-regulation in genetic networks. One gene will make a product that binds to and hence down-regulates another gene, which is then prevented from making a product that up-regulates another… and so on. What we have here is a cascade of events that can sometimes be described in terms of Boolean relationships between variables. One event might only follow from the conjunction of another two, or from a disjunction of them. Down-regulation is a kind of negation, and there can be double and triple negations in a network. Gene regulation networks do often have a rich enough structure of this kind for it to be useful to think of them as engaged in a kind of computation. Computer chip “and-gates,” neural “and-gates” and genetic “and-gates” have genuine similarities. Most other biological processes, though just as much the product of evolutionary design, do not have a structure that motivates this sort of description. In general, though, it would be fair to say that the concept of a “program” is used in biology in an especially loose and often problematic way.
8. Information and evolution
Information has also become a focus of general discussion of evolutionary processes, especially as they relate to the mechanisms of inheritance. As John Maynard Smith, Eors Szathmary, and Richard Dawkins have emphasized in different ways, inheritance mechanisms that give rise to significant evolutionary outcomes must satisfy some rather special conditions. Maynard Smith and Szathmary claim, for example, that the inheritance system must be unlimited or “indefinite” in its capacity to produce new combinations, but must also maintain high fidelity of transmission. They argue that many of the crucial steps in the last four billion years of evolution involve the creation of new ways of transmitting information across generations — more reliable, more fine-grained, and more powerful ways of making possible the reliable re-creation of form across events of biological reproduction. The transition to a DNA-based inheritance system (probably from a system based on RNA) is one central example (Maynard Smith and Szathmary 1995). The evolutionarily crucial features of inheritance mechanisms are often now discussed in informational terms, and the combinatorial structure seen in both language and DNA provides a powerful basis for analogical reasoning.
In some writers, however, the idea that evolution is an informational process can be taken too far. For example, Williams (1992) argues that, via reflection on the role of genes in evolution, we can infer that there is an informational “domain” that exists alongside the physical domain of matter and energy. This is an extreme version of a more common idea, that there exists such things as “informational genes” that should be understood as distinct from the “material genes” that are made of DNA and localized in space and time. We think that the reification of “the informational gene” is problematic; it is a mistake to suppose that there is both a physical entity — a string of bases — and an informational entity, a message. It is true that for evolutionary (and many other) purposes genes are often best thought of in terms of their base sequence (the sequence of C, A, T and G), not in terms of their full set of material properties. This way of thinking is essentially a piece of abstraction (Griesemer 2005). We rightly ignore some properties of DNA and focus on others. But it is a mistake of reification to treat this abstraction as an extra entity, with mysterious relations to the physical domain. The result is to obscure the ontological side of evolutionary theory, which can and should remain straightforwardly materialistic.
Bibliography
- Crick, Francis. (1958), “On Protein Synthesis”, Symposia of the Society for Experimental Biology 12: 138-163.
- Dawkins, R. (1976). The Selfish Gene. Oxford: Oxford University Press.
- Dawkins, R. (1986). The Blind Watchmaker. New York: Norton.
- Dembski, W. (1997). “Intelligent Design as a Theory of Information.” Reprinted in Pennock (2001).
- Dretske, F. (1981). Knowledge and the Flow of Information. Cambridge MA: MIT Press.
- Francis, R. (2003). Why Men Won't Ask for Directions: The Seductions of Sociobiology. Princeton: Princeton University Press.
- Giere, R. (1988). Explaining Science: A Cognitive Approach. Chicago: Chicago University Press.
- Godfrey-Smith, P. (1999). “Genes and Codes: Lessons from the Philosophy of Mind?” in V. Hardcastle (ed.), Where Biology Meets Psychology: Philosophical Essays. Cambridge MA: MIT Press.
- Godfrey-Smith, P. (2000a). “On the Theoretical Role of ‘Genetic Coding,’” Philosophy of Science 67: 26-44.
- Godfrey-Smith, P. (2000b). “Explanatory Symmetries, Preformation and Developmental Systems Theory.” Philosophy of Science 67: S322-S331.
- Godfrey-Smith, P. (2001). “Information and the Argument from Design.” In R. Pennock (ed.), Intelligent Design Creationism and its Critics: Philosophical, Theological and Scientific Perspectives. Cambridge MA: MIT Press, 2001, pp. 575-596.
- Grice, P. (1957). “Meaning.” Philosophical Review 66: 377-388.
- Griesemer, J.. (2005). “The Informational Gene and the Substantial Body: On the Generalization of Evolutionary Theory by Abstraction”, in M. Jones and N. Cartwright (eds.), Idealization XII: Correcting the Model. Idealization and Abstraction in the Sciences. Amsterdam/New York: Rodopi.
- Griffiths, P. E (2001). “Genetic Information: A Metaphor in Search of a Theory,” Philosophy of Science 68: 394-412.
- Griffiths, P. and R. Gray (1994). “Developmental Systems and Evolutionary Explanation,” Journal of Philosophy 91: 277-304.
- Harms, W. (2004). Information and Meaning in Evolutionary Processes. Cambridge: Cambridge University Press.
- Jablonka E. (2002). “Information: Its Interpretation, Its Inheritance and Its Sharing.” Philosophy of Science 69: 578-605.
- Jablonka, E. and M. Lamb (2005). Evolution in Four Dimensions. Cambridge MA: MIT Press.
- Jacob, F. (1982). The Possible and the Actual. Seattle: University of Washington Press.
- Kaplan, J. M., and Pigliucci, M. (2001). “Genes ‘For’ Phenotypes: A Modern History View.” Biology and Philosophy 16: 189-213.
- Kay, L. (2000). Who Wrote the Book of Life? A History of the Genetic Code. Palo Alto: Stanford University Press.
- Kirscher, M. W. and J. C. Gerhart (2005). The Plausibility of Life: Resolving Darwin's Dilemma. New Haven: Yale University Press
- Kitcher, Philip. S. (2001), “Battling the Undead: How (and How Not) to Resist Genetic Determinism”, in R. Singh, C. Krimbas, D. Paul and J. Beatty (eds.), Thinking About Evolution: Historical, Philosophical and Political Perspectives. Cambridge: Cambridge University Press.
- Knight, R., S. Freeland and L. Landweber (1999). “Selection, History and Chemistry: The Three Faces of the Genetic Code.” Trends in Biochemical Sciences 24: 241-247.
- Lehrman, D. S. (1970). “Conceptual and Semantic Issues in the Nature-Nurture Problem.” In L. R. Aronson, E. Tobach, D. S. Lehrman, and J. S. Roseblatt, (eds.) Development and Evolution of Behavior. San Francisco: Freeman, pp. 17-52.
- Maclaurin, J. (1998). “Reinventing Molecular Weismannism: Information in Evolution”, Biology and Philosophy 13: 37-59.
- Marcus, G. (2004). The Birth Of The Mind: How A Tiny Number of Genes Creates the Complexities of Human Thought. New York: Basic Books.
- Maynard Smith, J. (2000). “The Concept of Information in Biology,” Philosophy of Science 67: 177-194.
- Millikan, R. (1984). Language, Thought and Other Biological Categories. Cambridge MA: MIT Press.
- Moss, L. (1992), “A Kernel of Truth? On the Reality of the Genetic Program”, in D. Hull, M. Forbes and K. Okruhlik (eds.), PSA 1992, Volume 1. East Lansing: Philosophy of Science Association, pp. 335-348.
- Oyama, S. (1985). The Ontogeny of Information. Cambridge: Cambridge University Press.
- Pennock. R. (ed.) (2001). Intelligent Design Creationism and its Critics: Philosophical, Theological and Scientific Perspectives. Cambridge MA: MIT Press.
- Rosenberg, A. (1986). “Intention and Action Among the Macromolecules,” in N. Rescher, (ed.), Current Issues in Teleology. Lanham, MD: University Press of America.
- Sarkar, S. (1996), “Decoding ”Coding“ — Information and DNA.” BioScience 46: 857-864.
- Shannon, C. (1948). “A Mathematical Theory of Communication,” Bell Systems Technical Journal 27: 279-423, 623-656.
- Shea, N. (2007). “Representation in the Genome, and Other Inheritance Systems.” Biology and Philosophy 22: 313-331.
- Schrödinger, E. (1944/1992). What is Life? Cambridge: Cambridge University Press.
- Skyrms, B. (1996). Evolution of the Social Contract. Cambridge: Cambridge University Press.
- Smith, B. (2002) “The Foundations of Computing.” In M. Scheutz (ed.), Computationalism: New Directions. Cambridge MA: MIT Press
- Stegmann, U. (2004). “The Arbitrariness of the Genetic Code.” Biology and Philosophy 19: 205-222.
- Sterelny, K. (2000). “The ”Genetic Program“ Program: A Commentary on Maynard Smith on Information in Biology.” Philosophy of Science 67: 195-201.
- Sterelny, K. (2004). “Symbiosis, Evolvability and Modularity”. In G. Schlosser and G. Wagner (eds.), Modularity in Development and Evolution. Chicago: University of Chicago Press, pp. 490-516.
- Sterelny, K., K. Smith and M. Dickison (1996). “The Extended Replicator.” Biology and Philosophy 11: 377-403.
- Weisberg, M. (2007). “Who is a Modeler?” British Journal for the Philosophy of Science, 58: 207-233.
- Williams, G. C. (1992). Natural Selection: Levels, Domains, and Challenges. Oxford: Oxford University Press.
- Wright, L. (1973). “Functions.” Philosophical Review 82: 139-168.
Other Internet Resources
[Please contact the authors with suggestions.]
Related Entries
functionalism | genetics: evolutionary | genetics: genotype/phenotype distinction | heritability | mental content: teleological theories of | mental representation | naturalism | natural selection | teleology: teleological notions in biology
Acknowledgments
Thanks to Brett Calcott for preparing Figure 1.